这是 T20 世界杯赛季,我们想为我们的用户建立一个测验系统,用于短期预言预测。在比赛开始时要求用户预测场景,最后,主持人将提交所有预测场景中实际发生的情况。评分将根据谁回答正确以及回答所花费的时间进行。
鉴于我们系统的规模,我们估计可能有 5 万人参与测验。所以我们的目标是为100 万用户构建。这大致为我们提供了 20k 的目标 qps。
我的经验法则是,对于一个新系统,总是为预期用户数量的两倍设计系统。因此,如果您最终拥有更多用户,您的系统不会无法扩展。而且用户通常会随着时间的推移而增长,因此您不必不断地更改系统。但这并不意味着您将两倍的基础设施放在实际需要的地方。我通常会在我的系统中启用自动缩放,因此每当出现流量高峰时,系统都会自动缩放。
在进行规模估算后,我们迅速确定了哪些是大规模 API,以及处理能力较高的地方,以便我们可以有选择地为这些 API 进行可扩展的设计。我们不关心或花太多时间的其余小规模 API。
所以这些是我们确定的大规模 API
- 获取用户评分和排名
- 获取排行榜
- 计算排行榜(主要是数据处理而不是API)
- 发布用户答案
设计注意事项
看到要求后,我立即明白了两件事。
- 出于最明显的原因,我们将需要异步和分布式处理来计算分数和排行榜。如果您计划在单个节点上为 100 万或更多用户同步运行分数计算,祝您好运。想法很简单,我们将一个大任务拆分为多个小任务,并在不同的节点上运行它们,让它们按照自己的节奏进行。而且我们希望这个过程是容错的。
- Cache将成为我们阅读用户和排行榜排名的朋友。主要有两个原因,速度和易于扩展。对于简单的读取操作,缓存比 DB 快得多,并且通常比Postgres更容易扩展Redis/Memcached/Hazelcast集群。
在做出设计决策时,我选择使用我熟悉的技术,不想冒险寻找适合此用例的最佳技术。例如,我熟悉Redis,因此对于缓存,它是显而易见的选择。此外,每当我听到排行榜时,它会自动转换为我脑海中的Redis 排序集。对于异步处理,Kafka仍然是我的第一选择。如果有适当的时间我可能会做更多的探索,但这次我不会徘徊在寻找最好技术的荒野中,因为我没有时间!!!!
发布用户回答 API
这个 API 会让我们的用户提交测验的答案。这里的主要挑战是这会产生大量并发写入操作,这将大大增加我们数据库的负载。所以我们必须做两件事
- 减少数据库负载
- 产生某种背压或让 DB 操作员按自己的节奏工作,以免 DB 不堪重负
减少写入负载的解决方案是进行批处理。因此,如果我必须执行 10 次写入操作,我会将它们批处理以获取单个查询,然后运行 1 次 DB 写入操作。
背压和消息队列是配合的,架构图如下:

- 响应接收器接收用户响应并返回 202 HTTP 状态代码。这就像说我收到了你的请求,我将处理它,但你继续做你正在做的事情。这是异步处理的第一步,我们不会阻止调用者。
- 响应接收器将用户响应放入消息队列中,该队列再次分区以用于可扩展性/可用性/冗余目的。如果您已经了解 Kafka,您可以很容易地理解分区。如果您不这样做,只需将其视为一种将队列中的消息分发到多个较小的隔离队列的方法,这些队列在技术上可以驻留在不同的节点上。如果您知道数据库分片,那么它是相同的,但主要用于消息队列。在这里阅读更多关于 Kafka 的信息。
- 现在,这些原始响应由批处理器接收。然后它创建一批 10 条消息并将它们推送到下一个处理阶段。
- 数据库编写器提取批次并向数据库中插入查询。背压主要由数据库编写器引入,由于消息消费者是基于拉取的,因此它以自己的速度获取消息。因此我们可以防止数据库过载。由于它是批量处理而不是运行 100 个数据库查询,因此我们只运行了 10 个数据库查询。
由于我们使用消息队列在这里,随着异步无用户响应丢失,我们有内置的重试能力,它也是分配的负载在多个消费者。我们可以在需要时扩展我们的消息队列和我们的服务。
分数和排行榜计算
排行榜计算是主要问题,如果你看到这个系统,它不像我们事先知道正确答案的传统测验系统。因此,我们无法在有人回答后立即计算分数和排行榜。一旦主持人提交了正确的答案,我们必须计算所有用户的分数和排名。因此,一次性完成大量工作。很明显,我们的节点和数据库服务器都无法同步正确处理时尚。那么我们该怎么办?我们再次回到我们的朋友 Messages Queues 进行异步处理。很酷,所以我们可以异步计算分数,但是排行榜呢?这需要一直可用,对吗?那么排名呢?除非计算出所有用户的分数,否则您无法真正进行排名,对吗?并且专门计算排名可能是一个难题。
还记得我在谈论缓存时简要提到了 Redis 吗?他们有一个漂亮的东西叫做排序集 Sorted set,在有序集合中,您可以添加带有分数的键,Redis 会在O(log(N)) 中对其进行相应排序。这将解决我们的排名问题。它还允许我们运行范围查询,例如给我前 5 名,或者让我获得特定键的排名,所有这些都发生在 O(log(N)) 中。这正是我们在这里所需要的。
这些元素被添加到一个将 Redis 对象映射到分数的哈希表中。同时元素被添加到一个跳跃列表,将分数映射到 Redis 对象(所以对象在这个“视图”中按分数排序)——排序集内部
- 架构图
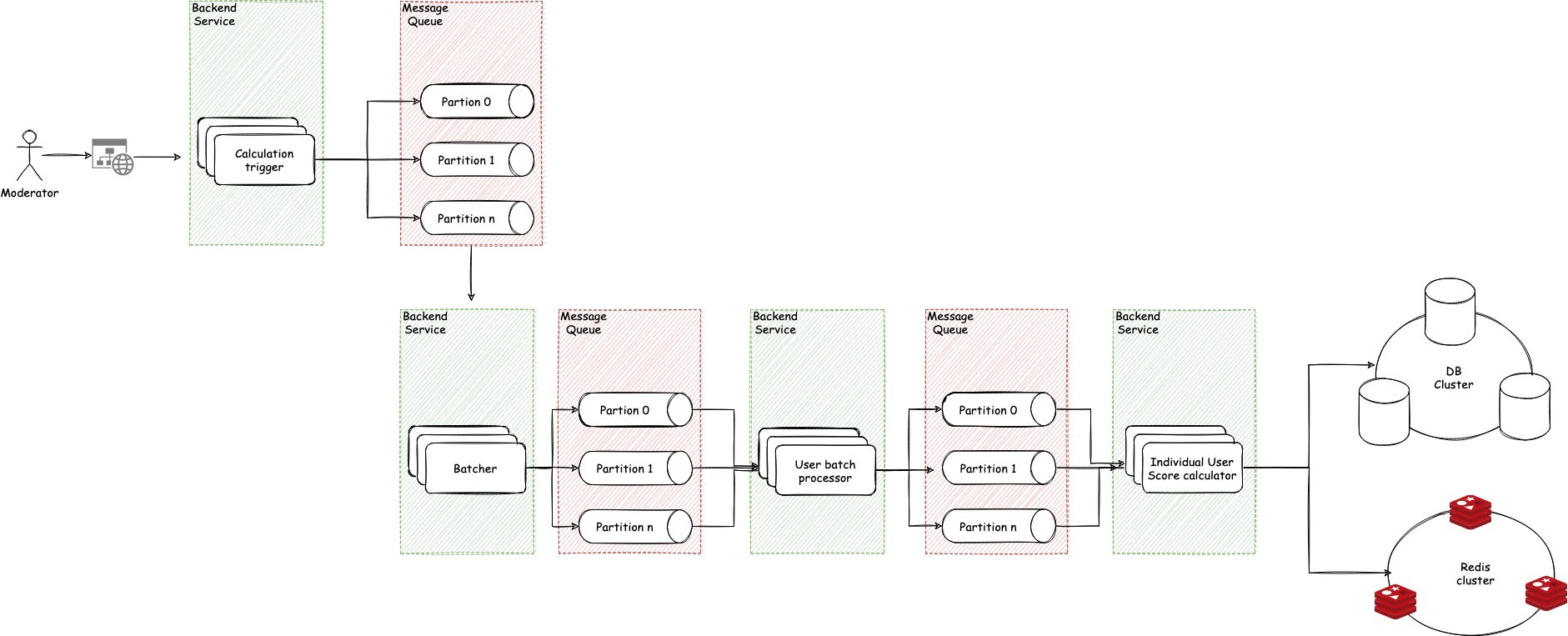
看起来有点吓人不是吗?请允许我解释一下
- 一旦主持人提交正确答案,就会推送分数计算触发消息,这将启动整个处理流程。
- 批处理器接收触发消息并根据正确回答的人数生成一对 DB 偏移和限制对象。例如,如果 10 个人回答正确并且批次大小为 5,那么它将生成两个对象(批次)。批次 1 {offset: 0, limit: 5},批次 2 {offset: 5, limit 5}。我们为什么要做这个?这样我们就可以运行批处理或运行分页的数据库查询,并且我们最终不会无限制地调用数据库。因此,如果我必须从数据库中获取 100 万条记录,并且我一次性完成,这将在许多地方引入很多问题。所以我们把它分解成更小的部分并运行更小但多个查询,这将返回更少的行数。
- 用户批处理器现在将接收这些批处理消息并相应地运行数据库查询。接收到 {offset: 0, limit: 5} 消息的处理器将从数据库中获取前 5 个用户 ID(也会执行另一个批处理操作,但这里很难解释,所以跳过)。在此之后,我们将告别批处理并切换到流处理。因为批处理器现在会将 5 个用户 ID 放入队列中,由下一个处理器处理。
- 现在用户分数计算器接收个人用户 ID,运行评分逻辑来计算个人用户分数。然后进行 1 DB update 修改用户评分。然后它更新排序集中该特定用户的分数,Redis 在内部分配或更新排名。一旦这个阶段完成处理,我们将获得我们数据库中所有用户的分数和我们 Redis 中所有用户的排名 + 分数。并且由于我们有排序集中每个人的排名,我们可以对其运行范围查询,以极快的速度获得排行榜。
如果我们的 Redis 集群在任何时候出现故障,因为我们也在数据库中维护了分数,我们可以随时触发该过程并在 Redis 上再次构建排序集。这是为了弹性。
我们的大部分问题现在都解决了,因为为了获得用户分数和排名,我们可以只进行 Redis 查询而不访问数据库。这也使我们的响应时间更快。
主要设计阶段到此结束。还有数据库、API 设计和其他我在这里跳过的东西。
实施
设计完成解决了我们 70% 的问题,我们知道我们可以解决这个问题,所以我们会迅速进入开发阶段。
在理想的世界中,我会去创建一个新的服务,尝试一种新的语言,比如Go,以获得更好更快的并行处理和其他东西。但鉴于时间表,这不是正确的做法。我们坚持使用我们的核心 NodeJS 服务并将所有东西都放在那里。微服务纯粹主义者在看到此声明后可能会失去它,但在与时间赛跑的过程中,您的负责人有时不得不退居二线。在众多权衡中,这是我们采取的主要措施之一。
部署和监控
经过一些错误修复和 QA 验收后,我们一切顺利。工作做对了吗?不,我的朋友,我们仍然必须为这件作品设置大量监控。因为它是在很短的时间内开发的,所以我至少有点不自信。默认情况下,我们通过LightStep在此服务上启用了跟踪。因此,除了跟踪之外,我还为所有 API设置了对流量、错误率、延迟仪表板和警报的专门监控。上线后我和我的队友,我们接到了一个电话,我们监视系统至少一个小时,从RAM 和 CPU 使用情况到错误日志。所以总是给可观察性同等的权重以及监控。生产系统存在一些小问题,我们只能通过监控及早发现它们。