示例是:向经过身份验证的用户显示产品页面,下图显示了在这种情况下如何执行请求。

为经过身份验证的用户显示产品页面,请注意,必须执行五个请求,但我们应该只计算四个顺序请求。尽管如此,由于请求是以同步方式执行的,整个系统不容易扩展并且存在很多问题。
由于这种高耦合度,我们的系统可能面临多个问题,例如:
- 需要时难以扩展
- 高负载下性能低
- 外部服务不可用造成的不可用
- 因协调部署而难以维护
解决方案的主要思想是将所有主数据项转换并聚合为单个派生项,该派生项随后可以存储到数据源中并在需要时进行查询。
由于我们已经使用Kafka生态系统来解决这个问题,最终的解决方案将是一个Kafka Streams 拓扑以及几个Kafka Connect组件,这些组件将通过发件箱模式或更改数据捕获的各种实现风格从数据源中提取数据并发布将其发送到 Kafka,以便在流应用程序中摄取。
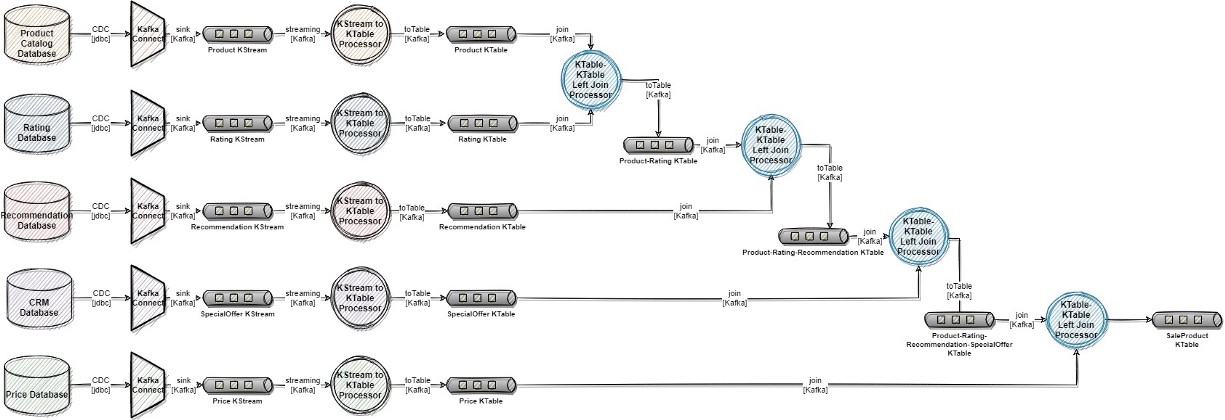
流拓扑将使用产品 ID作为分区键来连接所有 Kafka 主题中存在的数据。所有连接的结果将发布到 Kafka 主题中,然后可以写入数据库。正在生成的此数据聚合将称为SaleProduct。
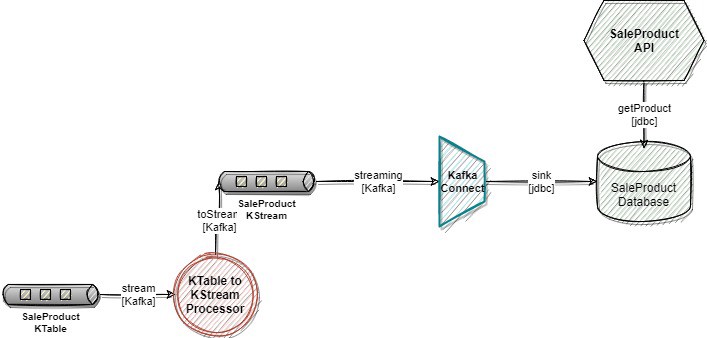
我们可以在SaleProduct数据库之上构建一个新服务(REST API、GraphQL API)。前端应用程序可以查询这个新端点,并且这个端点可以将产品作为响应提供服务,而无需任何中间处理。
结论
总之,让我们重新审视我们的系统面临的上述列举的问题,看看其中是否仍然存在:
- “需要时难以扩展”——在当前的解决方案中,组件不再难以扩展,因为 Kafka 拓扑可以通过添加分区轻松扩展。我们可以为新的SaleProduct数据存储选择特定的数据库技术,该技术也可以轻松扩展(例如:Cassandra 数据库)。此外,SaleProduct API是一个简单的无状态服务,可以横向扩展。
- “高负载下的低性能”——通过使用来自“本地”数据库的单个查询替换所有用于聚合数据的同步 HTTP 请求,将显着提高高负载下的性能。此外,查询不会执行任何连接,数据可以直接存储在所需的表示中(例如:JSON、XML 等)。
- “由于外部服务不可用而产生的不可用”——如果在之前的场景中,外部组件的不可用会导致所谓的“产品服务”的不可用,在当前的解决方案中,这是避免的,因为我们有数据已经存储在我们的“本地”数据源中。必须保持可用的单一组件必须是数据库本身。
- “由于协调部署而难以维护”——这不再是问题,因为我们不再在空间或时间上与任何外部服务耦合。
不过,我必须说这不是一个防弹解决方案,并且有两个主要缺点:
- 面对最终一致性——如果没有人注意到,我已经在本文中基本描述了我们如何以及为什么从著名的CAP 定理中选择A(可用性)和P(分区容限),我现在要说的是:使用这种方法,我们必须准备好面对最终的一致性!
- 数据治理——通常,在大型复杂企业中,很难像当前解决方案中那样使用(检索和派生)主数据和构建派生数据孤岛。通过查看Zhamak Dehghani 的数据网格,可以看到一些关于采用这种方法的概念。