Apache kafka以其弹性、容错性和高吞吐量而闻名。但它的表现并不总是满足所有人的期望。在某些情况下,我们可以通过缩小或扩大代理规模来改进它。而在大多数情况下,我们必须玩配置游戏。
在卡夫卡的生态系统中,确实有很多配置。几乎不可能掌握每个配置的概念。一方面,它们确实使系统更加灵活,但另一方面,开发人员可能会对如何使用它们感到困惑。
幸运的是,大多数配置都是预定义的,它们在大多数情况下都能很好地工作。首先,他们需要知道的强制性配置非常有限。
当然,我想你读这篇文章是因为你想把卡夫卡制作人带到一个新的层次。因此,在本文中,我想分享10种配置,我认为这些配置对于使您的生产商更具弹性非常重要。
本文讨论的kafka配置参数:
acks |
ACK
ack是生产者从Kafka代理获得的确认,以确保消息已成功提交给该代理。 参数acks是生产者在考虑成功提交之前需要接收的多少次确认?
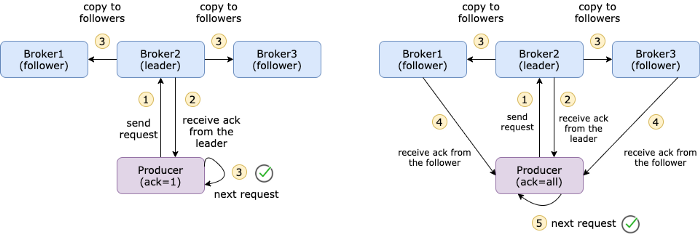
图中是ack=1 和ack=all的区别
ack默认值为1,这意味着只要生产者从该主题的leader broker接收到ack,它就会将其视为成功提交并继续执行下一条消息。不建议将acks设置为0,因为这样您就无法保证提交。acks=all将确保生产者从该主题的所有同步副本获取ACK。它提供了最强的消息持久性,但也需要较长的时间,从而导致更高的延迟。所以,你需要决定什么对你更重要。
In-sync replicas
acks=all将从所有同步副本(ISR)获得确认,那么什么是同步副本?创建主题时,必须定义所需的副本数量。副本只不过是其中一个代理中消息的副本,因此副本的最大数量是代理的数量。
在这些复制副本中,有一个领导者,其余的都是追随者。领导者处理所有读写请求,而追随者被动地复制领导者。同步副本是指在最后10秒内完全赶上领先者的副本。可以通过replica.lag.time.max.ms配置时间段。如果某个代理主机宕机或出现网络问题,则该代理无法跟进领导者主机节点,10秒后,该代理将从ISR中删除。
默认的最小同步副本(min.insync.replicas)为1。这意味着,如果所有的追随者都倒下了,那么ISR只包括领导者。即使acks设置为all,它实际上也只将消息提交给1个代理(leader),这会使消息易受攻击。
图中是不同min.insync.replicas参数得区别
config min.insync.replicas基本上定义了生产者在考虑成功提交之前必须接收的副本数量。此配置将添加到acks=all之上,使您的消息更安全。但另一方面,您必须平衡延迟和速度。
Retry on failure
假设您设置了acks=all和min.insync.replicas=2。出于某种原因,跟随者完成了,然后生产者识别出一个失败的提交,因为它无法从min.insync.replications代理获取ACK。
您将从生产者处收到一条错误消息:
KafkaError{code=NOT_ENOUGH_REPLICAS,val=19,str="Broker: Not enough in-sync replicas"} |
您将看到来自正在运行的代理的以下错误消息。这意味着,即使代理正在运行,如果当前ISR不足,Kafka也不会将消息追加到正在运行的代理。
ERROR [ReplicaManager broker=0] Error processing append operation on partition test-2-2-0 (kafka.server.ReplicaManager) |
默认情况下,生产者不会对此错误采取行动,因此将丢失消息。这就是“最多只能调用一次”语义。但是您可以通过配置retries=n让生产者重新发送消息。这基本上是生产者在提交失败时的最大重试次数。默认值为0。
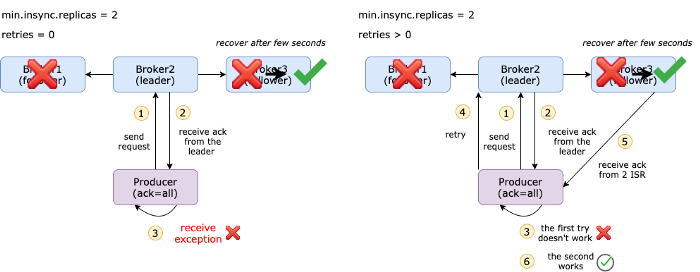
图是retries=0 和 retries>0区别
如果您将retries设置为5,则生产者最多将重试5次。您不会注意到生产者日志中的重试次数,因为它只显示提交是否成功。但是您可以在代理端看到retries+1日志消息。
避免重复消息
在某些情况下,消息实际上已提交给所有同步副本,但由于网络问题,代理无法发送回ack(例如,仅允许单向通信)。同时,我们将retries设置为3,那么生产者将重新发送消息3次。这可能会导致主题中出现重复消息。
假设我们有一个生产者向主题发送1M条消息,而代理在消息提交后但生产者收到所有ACK之前失败。在这种情况下,我们可能会收到超过100万条关于这个主题的信息。这也称为至少一次语义。
最理想的情况是一次语义,即即使生产者重新发送消息,消费者也只能收到同一消息一次。
我们需要的是一个幂等生产者。幂等式意味着一次或多次应用一个运算具有相同的效果。使用config enable.idempotent=true很容易启用此功能。
它是如何工作的?消息分批发送,每批都有一个序列号。在代理端,它跟踪每个分区的最大序列号。如果有一个序列号较小或相等的批进入,代理将不会将该批写入主题。这样,它还可以确保批次的顺序。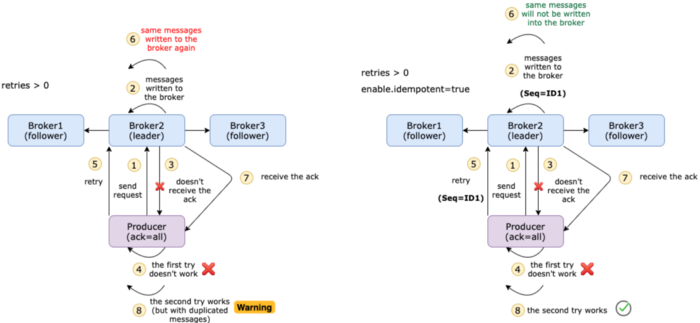
上图展示激活幂等和失效幂等得区别
按顺序发送消息
确保顺序的另一个重要配置是max.in.flight.requests.per.connection,默认值为5。这表示可以在生产者端缓冲的未确认请求的数量。如果重试次数大于1且第一个请求失败,但第二个请求成功,则第一个请求将重新发送,消息的发送顺序将变错误了。
根据文档说明:
请注意,如果此设置设置为大于1,并且存在发送失败的情况,则存在由于重试而导致消息重新排序的风险(即,如果启用了重试)。
如果不启用幂等项,但仍希望保持消息的有序,则应将此设置配置为1。
但如果已经启用了幂等项,则不需要显式定义此配置。卡夫卡将选择合适的值,如本文所述。
如果用户未明确设置这些值,将选择合适的值。如果设置了不兼容的值,将引发ConfigException。
消息发送得太快
当生产者调用send()时,消息不会立即发送,而是添加到内部缓冲区。默认的buffer.memory是32MB。如果生产者发送消息的速度快于它们传输到代理的速度,或者存在网络问题,则消息将超过buffer.memory,那么send()调用将被阻塞到max.block.ms(默认为1分钟)。
可以通过增加这两个值buffer.memory和max.block.ms来缓解此问题。
另外两个可以使用的配置是linger.ms和batch.size。linger.ms是批次准备好发送之前的延迟时间。默认值为0,这意味着即使批中只有1条消息,也会立即发送批。有时,人们会增加linger.ms以减少请求数量并提高吞吐量。但这将导致更多的信息保存在内存中。所以,一定要照顾好双方。
有一个与linger.ms等效的配置,即batch.size。这是单个批次的最大尺寸。当满足这两个要求中的任何一个时,将发送批次。