在过去的五个月中,我与 50 多家公司讨论了他们的授权系统。他们中的一半以上正在以某种形式使用微服务,我对它们带来的授权挑战着迷。似乎没有人就面向服务的后端授权的最佳实践达成一致:我与将用户角色附加到身份验证令牌的团队、将所有内容存储在特定于授权的图形数据库中的团队以及在 Kubernetes 中自动执行授权检查的团队进行了交谈。这些解决方案已经进行了数月或数年的工程工作,每个团队都发明了自己的轮子。为什么?
当你有一个单体时,你通常只需要与一个数据库交谈来决定是否允许用户做某事。单体应用中的授权策略不需要过多关注在哪里可以找到数据(例如用户角色)——你可以假设所有数据都可用,如果需要加载更多数据,它可以很容易从单体的数据库中提取出来。
但是分布式架构的问题变得更加困难。也许您正在将单体应用拆分为微服务,或者您正在开发一个新的计算密集型服务,该服务需要在运行作业之前检查用户权限。现在,决定谁可以做什么的数据可能并不那么容易获得。您需要新的 API,以便您的服务可以相互讨论权限:“谁是该组织的管理员?谁可以编辑此文档?他们可以编辑哪些文档?” 为了在服务 A 中做出决策,我们需要来自服务 B 的数据。服务 A 的开发人员如何要求这些数据?服务 B 的开发人员如何提供这些数据?
这些问题有很多答案,所以我试图将它们组织成几个广泛的模式。这些模式不一定能捕捉到解决方案世界的全部复杂性,但我发现它们可以帮助我与不同的人谈论他们构建的内容。当我与新团队交谈时,它们使我更容易对解决方案进行分类。
在构建微服务时,我看到了处理授权数据的三种主要模式。我将在这篇文章中讨论所有三个:
- 将数据留在原处,让服务直接请求它。
- 使用网关将数据附加到所有请求,因此它随处可用。
- 将授权数据集中到一个地方,并将所有决策转移到那个地方。
为什么微服务的授权更难?
我们以授权场景为例,一个用于编辑文档的应用程序。这是微不足道的,但希望能说明问题:
- 有用户、组织和文档。
- 用户可以在组织内拥有角色,member或者admin。
- 文件属于组织。
- 如果用户member在组织中具有角色,则她可以阅读文档。
- 如果用户admin在组织中具有角色,则她可以阅读或编辑文档。
在单体应用中,以干净的方式表达该逻辑并不太难。当您需要检查用户是否可以阅读文档时,您可以检查该文档属于哪个组织,为该组织加载用户的角色,然后检查该角色是否为member或 之一admin。这些检查可能需要额外的一两行 SQL,但数据都在那里。
当您将应用程序拆分为不同的服务时会发生什么?也许您已经剥离了一个新的“文档服务”——现在,检查对特定文档的读取权限需要检查位于该服务数据库之外的用户角色。文档服务如何访问它需要的角色数据?
模式 1:将数据保留在原处
通常,最简单的解决方案是将数据保留在原处,并让服务在需要时请求他们需要的数据。鉴于上述问题,您可能会认为这是最明显的解决方案。
您拆分数据模型和逻辑,以便文档服务控制由哪个角色授予哪些与文档相关的权限(管理员可以编辑,成员可以阅读等),然后用户服务公开一个 API 来获取用户的角色一个组织。有了这个 API,权限检查可以像这样发生:

有一个合理的论点认为最简单的解决方案是最好的解决方案,这通常适用于这里。根据我的经验,这通常是当团队开始转向微服务并且只想让某些东西工作时的着陆点。它可以完成工作,并且不需要任何额外的基础设施。
当服务或团队数量增加、授权逻辑变得更加复杂或面临更严格的性能要求时,这种模式开始出现裂缝。为了实现这一目标,任何新服务的开发人员都需要知道如何从用户服务中获取角色数据,而用户服务本身必须进行扩展以满足该需求。随着服务依赖性的激增,该模式可能会增加不可预测的延迟和重复请求。也许引入单独的“文件夹”服务会使权限检查成为服务之间的聊天网络:
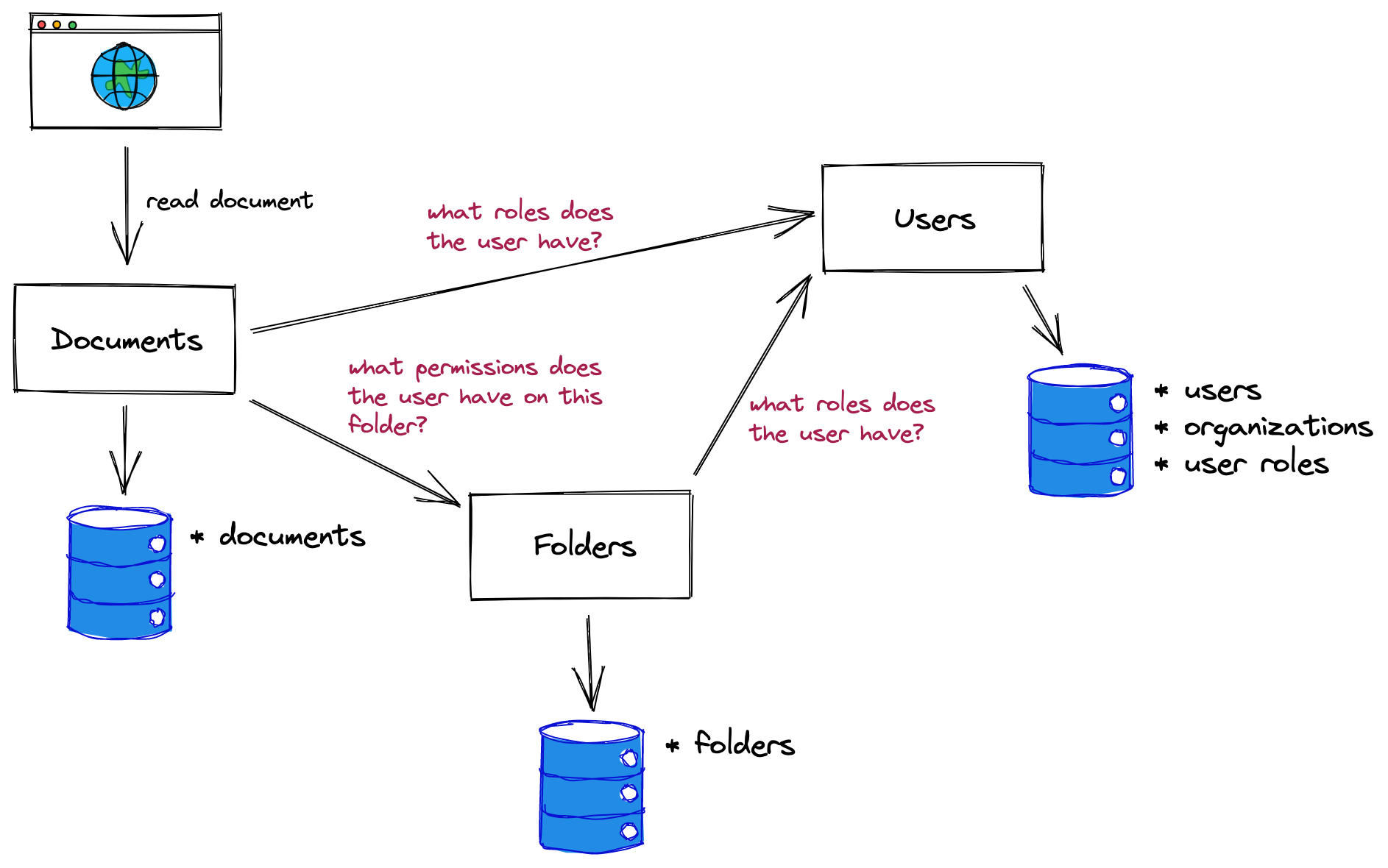
尽管它有变得有点混乱的风险,但这种模式可以让你走得很远。不必为授权部署和维护额外的基础设施可能是一个巨大的优势,如果带有数据的服务可以处理来自需要数据的服务的负载,那么将它们串在一起是一个很好的解决方案。
我已经与一些遵循这种一般模式的团队进行了交谈,但他们觉得他们应该用某种专门的授权服务来替换所有的管道。我总是确保问他们真正的问题是什么。如果是延迟,也许在正确的位置添加缓存可以解决它。如果授权逻辑在服务本身中变得杂乱无章,那么也许您需要强加标准的策略格式。(Oso 是一种解决方案;还有其他解决方案。)
但是,如果问题是您的数据模型变得过于复杂,或者您重复地重新实现相同的 API,或者权限检查需要与太多不同的服务进行交互,那么也许是时候重新考虑架构了。
模式 2:请求网关
授权数据问题的一种干净的解决方案是将用户的角色包含在对所有可能需要做出决定的服务的任何请求中。如果文档服务在请求中获取有关用户角色的信息,则它可以基于此做出自己的授权决策。
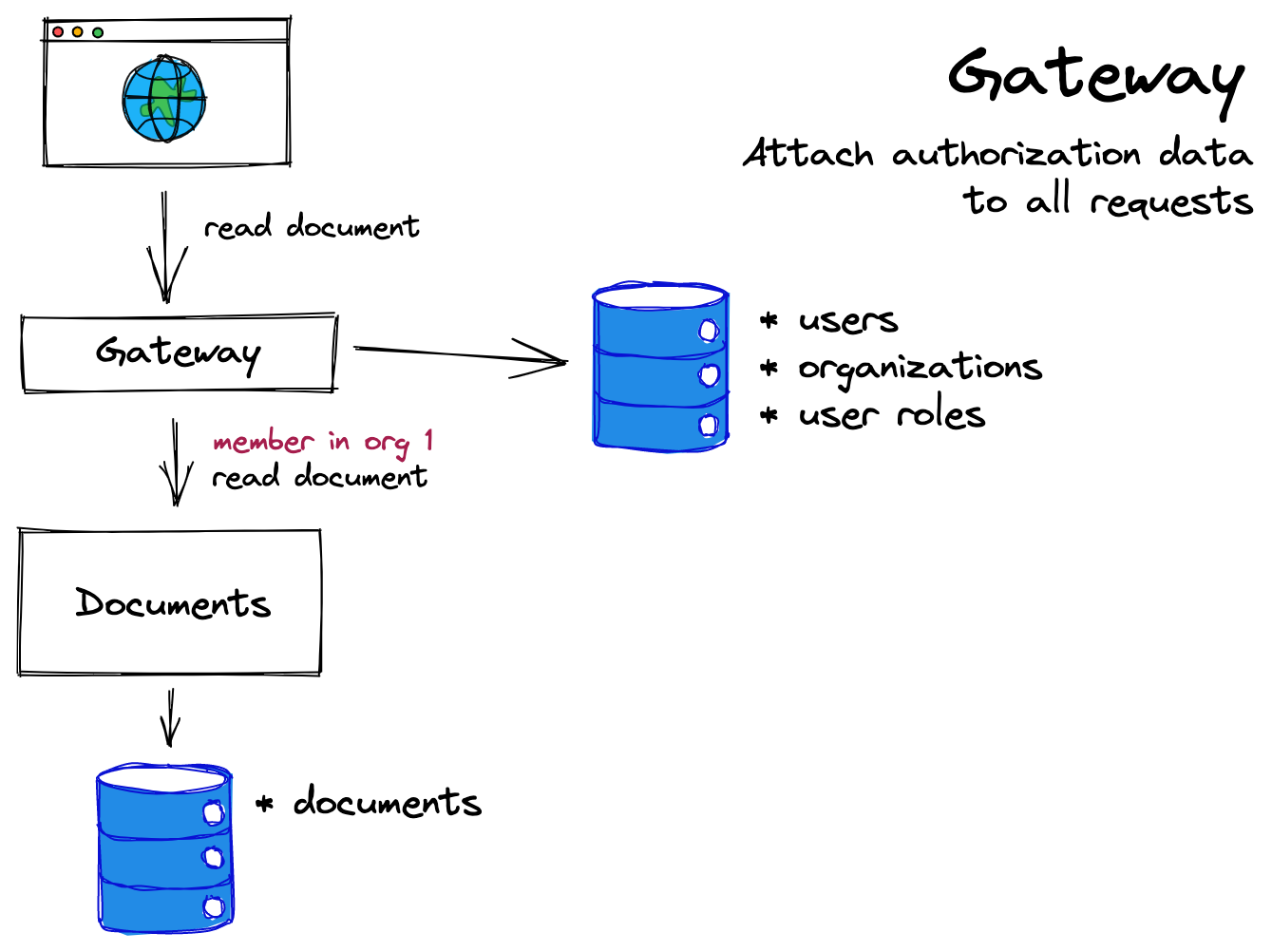
在这种模式中,“网关”位于 API 与其最终用户之间。网关可以访问用户信息和角色信息,它可以在将请求传递给 API 本身之前将这些信息附加到请求中。当 API 收到请求时,它可以使用请求中的角色数据(即在其标头中)来检查用户的操作是否被允许。
网关通常负责身份验证和授权。例如,网关可能使用Authorization标头对特定用户进行身份验证,然后另外获取该用户的角色信息。然后网关将带有用户 ID 和角色信息的请求代理到下游服务(上例中的文档服务)。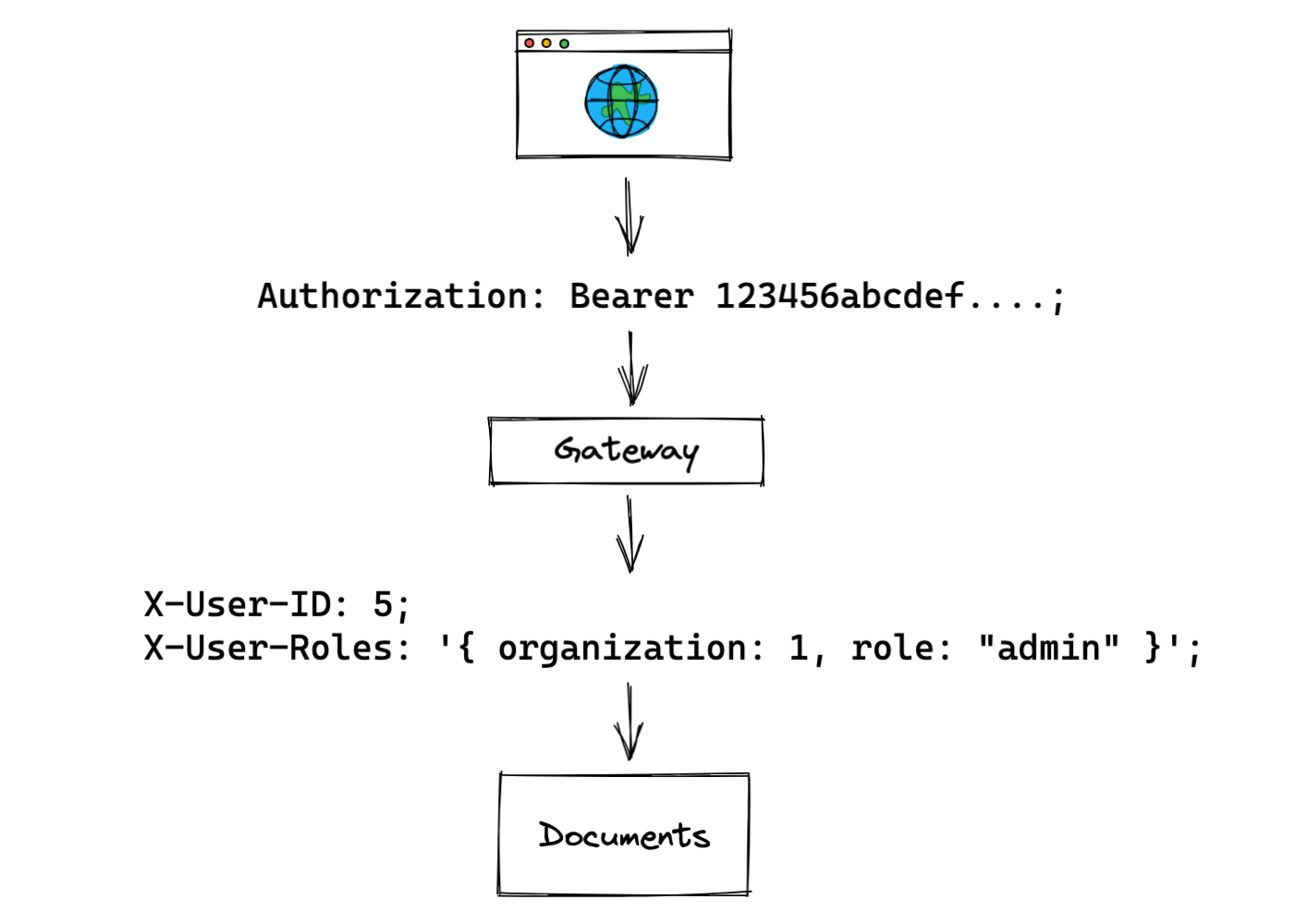
网关模式的主要好处是其架构简单。它允许下游服务(如文档服务)的开发人员不必关心角色数据来自何处。授权数据始终在请求中可用——可以立即执行权限检查,无需任何额外的往返。
请注意,在这里使用裸头确实开辟了新的攻击途径——您需要确保恶意客户端无法注入他们自己的头。作为替代方案,用户的角色或其他访问控制数据可以包含在他们的身份验证令牌本身中,通常表示为JWT。
如果您的授权数据包含少量角色(例如,每个用户在一个组织中只能拥有一个角色),则网关最有效。当权限开始不仅仅取决于用户在组织中的角色时,请求的规模可能会激增。也许用户可以根据他们尝试访问的资源类型(特定事件的组织者或特定文件夹的编辑者)具有不同的角色。有时,这些数据太大而无法合理地放入标题中,而有时急切地获取所有这些数据的效率很低。如果是这种情况,将所有相关的授权数据填充到令牌或标头中并不能完全削减它。
模式 3:集中所有授权数据
另一种解决方案是将所有授权数据和逻辑放在一个地方,与所有需要强制执行授权的服务分开。实现这种模式最常见的方法是构建一个专门的“授权服务”。然后,当你的其他服务需要进行权限检查时,他们会转身询问授权服务: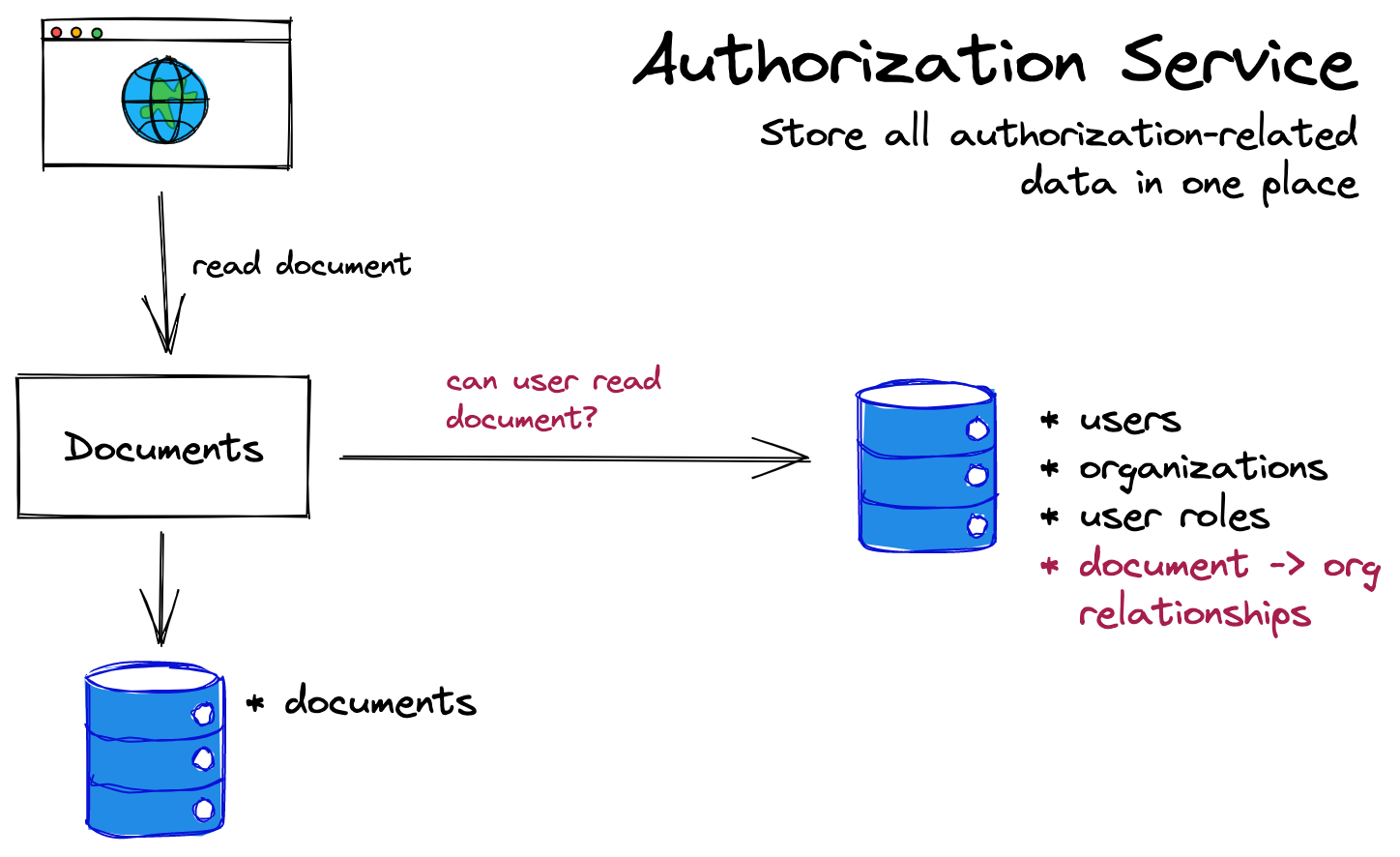
在这个模型中,文档服务根本不关心用户的角色:它只需要询问授权服务用户是否可以编辑文档,或者用户是否可以查看文档。授权服务本身包含做出该决定所需的一切(包括角色数据)。
这可能非常有吸引力:您现在拥有一个负责授权的系统,这符合微服务的理念。以这种方式分离关注点有一些优点:你团队中的其他开发人员不需要关心授权是如何工作的。因为它是独立的,所以您对授权服务所做的任何优化都有助于加快整个系统的其余部分。
当然,这种关注点分离是有代价的。现在所有授权数据都必须存放在一个地方。决策中可能使用的所有内容——用户在组织中的成员身份、文档与其组织的关系——都必须存在于集中式服务中。要么授权服务成为该数据的唯一真实来源,要么您必须将数据从应用程序复制和同步到该中心位置(更有可能)。授权系统必须了解作为任何权限基础的整个数据模型:组、共享、文件夹、来宾、项目。如果这些模型经常变化,系统就会成为新开发的瓶颈。任何微服务的任何更改都可能需要更新授权服务,
还有其他因素使授权服务变得棘手:部署负责保护每个请求的服务意味着您负责实现高可用性和低延迟。如果系统出现故障,每个请求都会被拒绝。如果系统对查询响应缓慢,则每个请求都很慢。
Google 的 Zanzibar 论文概述了这种模式的一种实现,但它也带来了自己的挑战。您必须将所有数据作为“元组”插入 Zanzibar(Alice 拥有此文档,此文件夹包含此其他文件夹等)。并且因为它限制了它可以存储的数据,所以有些规则实际上无法单独用 Zanzibar 来表达:与时间、请求上下文或依赖于某种计算有关的规则。有些人称这些为“基于属性”的规则。例如,用户每周只能创建 10 个文档,或者管理员可以将某些文件夹设置为“只读”,以防止对其子文档进行编辑。在这些情况下,开发人员必须在 Zanzibar 之外编写自己的策略逻辑。
将您的授权集中到一个地方的挑战传统上阻止了大多数团队采用这种模式。那些确实倾向于拥有大量服务和足够复杂的数据模型——对他们来说吸收授权服务本身增加的复杂性是有意义的。例如,Airbnb构建了一个名为 Himeji 的授权服务,以支持他们从单体应用转向微服务的模型。它有一个专门的工程师团队为它工作两年,并且可能会无限期地工作。
但是,如果您可以削减其中的一些开销,对于许多使用微服务构建的团队来说,集中式授权服务可能是一个有吸引力的选择。我的团队正在努力构建授权服务,同时避免集中所有授权数据的挑战。
你应该使用哪一个?
在与工程团队交谈时,我的指导始终是“围绕应用程序构建授权,而不是相反”。对于维护大量额外基础设施成本高昂的简单系统,最好将数据保留在原处,并将您的服务与专门构建的 API 结合在一起。某些应用程序可以增长到大规模,只需要适合 JWT 的基本用户角色——在这种情况下,也许授权网关是最佳的。一些拥有多种产品、授权模式和用户类型的公司可能更愿意努力将他们的数据集中到一个专门的授权服务中。