Spark Streaming 是核心 Spark API 的扩展,它支持实时数据流的可扩展、高吞吐量、容错流处理。Spark Streaming 可用于流式传输实时数据,并且可以实时进行处理。Spark Streaming 不断增长的用户群由 Uber、Netflix 和 Pinterest 等家喻户晓的名字组成。
在实时数据分析方面,Spark Streaming 提供了一个单一平台来摄取数据以进行快速实时处理。通过这个博客,我将向您介绍 Spark Streaming 这个令人兴奋的新领域,我们将通过一个完整的用例, 使用 Spark Streaming 进行Twitter 情绪分析。
什么是流媒体?
数据流是一种传输数据的技术,以便它可以作为稳定和连续的流进行处理。随着互联网的发展,流媒体技术变得越来越重要。
为什么是 Spark Streaming?
我们可以使用 Spark Streaming 从 Twitter、股票市场和地理系统等各种来源流式传输实时数据,并执行强大的分析来帮助企业。
Spark Streaming 概述
Spark Streaming用于处理实时流数据。它是对核心 Spark API 的有用补充。Spark Streaming 支持实时数据流的高吞吐量和容错流处理。
基本的流单元是 DStream 这基本上是一系列 RDD 来处理实时数据。
Spark 流功能
- 扩展: Spark Streaming 可以轻松扩展到数百个节点。
- 速度:它实现了低延迟。
- 容错: Spark 能够有效地从故障中恢复。
- 集成: Spark 集成了批处理和实时处理。
- 业务分析: Spark Streaming用于跟踪客户的行为,可用于业务分析
Spark Streaming 工作流
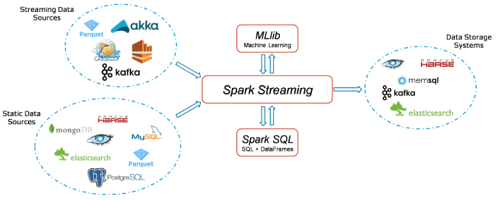
Spark Streaming 工作流有四个高级阶段。第一个是从各种来源流式传输数据。这些源可以是用于实时流式传输的流数据源,例如 Akka、Kafka、Flume、AWS 或 Parquet。第二种来源包括 HBase、MySQL、PostgreSQL、Elastic Search、Mongo DB 和用于静态/批处理流的 Cassandra。一旦发生这种情况,Spark 可用于通过其 MLlib API 对数据执行机器学习。此外,Spark SQL 用于对这些数据执行进一步的操作。最后,流输出可以存储到各种数据存储系统中,如 HBase、Cassandra、MemSQL、Kafka、Elastic Search、HDFS 和本地文件系统。
Spark Streaming 基础
- 流上下文
- 数据流
- 缓存
- 累加器、广播变量和检查点
流上下文
Streaming Context使用 Spark 中的数据流。它注册一个Input DStream以产生一个Receiver对象。它是 Spark 功能的主要入口点。Spark 提供了许多可从上下文访问的源的默认实现,例如 Twitter、Akka Actor 和 ZeroMQ。
StreamingContext 对象可以从 SparkContext 对象创建。SparkContext 表示与 Spark 集群的连接,可用于在该集群上创建 RDD、累加器和广播变量。
import org.apache.spark._ |
数据流
Discretized Stream (DStream) 是 Spark Streaming 提供的基本抽象。它是一个连续的数据流。它是从数据源或通过转换输入流生成的已处理数据流接收的。
在内部,一个 DStream 由一系列连续的 RDD 表示,每个 RDD 包含来自某个间隔的数据。
- 输入 DStreams:
输入 DStreams是表示从流源接收的输入数据流的 DStreams。
每个输入 DStream 都与一个 Receiver 对象相关联,该对象从源接收数据并将其存储在 Spark 的内存中以供处理。
- DStreams 上的转换:
任何应用在 DStream 上的操作都会转化为对底层 RDD 的操作。转换允许修改来自输入 DStream 的数据,类似于 RDD。DStreams 支持许多普通 Spark RDD 上可用的转换。
以下是 DStreams 上的一些流行转换:
- map(func) map( func ) 通过将源 DStream 的每个元素传递给函数func 来返回一个新的 DStream 。
- flatMap(func) flatMap( func ) 与 map( func )类似,但每个输入项都可以映射到 0 个或多个输出项,并通过将每个源元素传递给函数func 来返回一个新的 DStream 。
- filter(func) filter( func ) 通过仅选择func返回 true的源 DStream 的记录来返回一个新的 DStream 。
- reduce(func) reduce( func ) 通过使用函数func聚合源 DStream 的每个 RDD 中的元素,返回单元素 RDD 的新 DStream 。
- groupBy(func) groupBy( func ) 返回新的 RDD,它基本上由一个键和该组的相应项目列表组成。
- 输出 DStreams:
输出操作允许将 DStream 的数据推送到外部系统,如数据库或文件系统。输出操作触发所有 DStream 转换的实际执行。
- 缓存
DStreams允许开发人员在内存中缓存/持久化流的数据。如果 DStream 中的数据将被多次计算,这很有用。这可以使用 DStream 上的persist()方法来完成。对于通过网络接收数据的输入流(如Kafka、Flume、Sockets等), 默认持久性级别设置为将数据复制到两个节点以实现容错。
累加器、广播变量和检查点
- 累加器: 累加器是仅通过关联和交换操作添加的变量。它们用于实现计数器或总和。在 UI 中跟踪累加器对于了解运行阶段的进度很有用。Spark 本身支持数字累加器。我们可以创建命名或未命名的累加器。
- 广播变量: 广播变量允许程序员在每台机器上缓存一个只读变量,而不是随任务一起传送它的副本。它们可用于以有效的方式为每个节点提供大型输入数据集的副本。Spark 还尝试使用有效的广播算法来分发广播变量以降低通信成本。
- 检查点: 检查点类似于游戏中的检查点。它们使其 24/7 全天候运行,并使其能够适应与应用程序逻辑无关的故障。
用例 – Twitter 情绪分析
现在我们已经了解了 Spark Streaming 的核心概念,让我们使用 Spark Streaming 解决一个现实生活中的问题。
问题陈述: 设计一个 Twitter 情绪分析系统,在其中我们为危机管理、服务调整和目标营销填充实时情绪。
情感分析的应用:
- 预测一部电影的成功
- 预测政治竞选成功
- 决定是否投资某家公司
- 定向广告
- 查看产品和服务
Spark Streaming 实现:
下面是伪代码:
//Import the necessary packages into the Spark Program |
推文情绪的输出根据它们的创建时间存储到文件夹和文件中。此输出可以根据需要存储在本地文件系统或 HDFS 上。
使用 Spark Streaming 进行情感分析的公司已应用相同的方法来实现以下目标:
- 提升客户体验
- 获得竞争优势
- 获得商业智能
- 振兴一个失败的品牌