Cassie Kozyrkov是谷歌首席决策科学家,决策智能的先驱,本文是对决策智能的定义提要,原文点击标题:
决策智能是人工智能时代领导力的新学科,决策智能是一门新的学科,涉及在选项之间进行选择的所有方面。它将应用数据科学、社会科学和管理科学的精华汇集到一个统一的领域,帮助人们使用数据来改善他们的生活、他们的业务和他们周围的世界。
这是人工智能时代的一门重要科学,涵盖了负责任地领导人工智能项目以及设计目标、指标和大规模自动化安全网所需的技能。
决策智能是将信息转化为任何规模的更好行动的学科。
什么是决定、决策?
数据很漂亮,但重要的是决策。正是通过我们的决定——我们的行动——我们才能影响我们周围的世界。
我们将“决定、决策”一词定义为任何实体在选项之间的任何选择,因此对话比 MBA 式的困境(比如是否在伦敦开设分公司)更广泛。
在这个术语中,在用户的照片上添加诸如猫与非猫之类的标签是由计算机系统执行的决定,而确定是否启动该系统是人类领导者深思熟虑的决定。
什么是决策者?
用我们的话说,“决策者”不是突然介入以否决项目团队阴谋的利益相关者或投资者,而是负责决策架构和上下文框架的人。换句话说,是精心设计的目标的一个创造者,而不是破坏者。
什么是做出决策?
做决策是一个不同学科使用不同的词,所以可以指:
- 在有其他选择的情况下采取某种行动(在这个意义上,可以说是由计算机或蜥蜴做出决策)。
- 执行(人类)决策者的职能,其中一部分是对决策负责。即使计算机系统可以执行决策,它也不会被称为决策者,因为它不对其产出承担责任--这个责任完全在创造它的人类的肩上。
进行计算与作出决定
不是所有的产出/建议都是决策。在决策分析的术语中,只有在发生了不可撤销的资源分配后,才是一个决策。只要你可以免费改变你的想法,就还没有做出决定。
决策情报分类法
学习决策情报的一种方法是沿着传统的思路将其分成定量方面(主要与应用数据科学重叠)和定性方面(主要由社会科学和管理科学的研究人员开发)。
定性方面:决策科学
构成定性方面的学科在传统上被称为决策科学--我很希望整个事情能被称为决策科学(可惜我们不能总是得到我们想要的)。
决策科学关注的问题
- "你应该如何设定决策标准和设计你的衡量标准?" (全部)
- "你所选择的衡量标准是否与激励相容?" (经济学)
- "你应该在什么质量下做出这个决定,你应该为完美的信息支付多少钱?" (决策分析)
- "情绪、启发式方法和偏见是如何在决策中发挥作用的?" (心理学)
- "皮质醇水平等生物因素如何影响决策?" (神经经济学)
- "改变信息的呈现方式如何影响选择行为?" (行为经济学)
- "在群体背景下做决定时,如何优化你的结果?" (实验博弈论)
- "在设计决策环境时,如何平衡众多约束条件和多阶段目标?" (设计)
- "谁会体验到决策的后果,各种群体会如何看待这种体验?" (用户体验研究)
- "决策目标是否符合道德?" (哲学)
这只是一小部分......还有很多! 这也远远不是所涉及的学科的完整清单。把决策科学看作是处理决策设置和信息处理的模糊存储形式(人脑),而不是那种整齐地写在半永久性存储(纸上或电子)中的数据,我们称之为数据。
你的大脑是有问题的
在上个世纪,赞扬任何将一叠厚厚的数学塞进一些毫无戒心的人类努力的人是很时髦的。采取定量的方法通常比不假思索的混乱要好,但有一种方法可以做得更好。
基于纯数学理性的策略是相对幼稚的,往往表现不佳。
基于纯粹的数学理性而没有对决策和人类行为的定性理解的策略可能相当幼稚,相对于那些基于对定量和定性的共同掌握的策略,往往表现不佳。
人类不是优化者,我们是满足者,这是一个拐弯抹角的花哨的词。
实际上,我们人类都使用认知启发法来节省时间和精力。这通常是一件好事。在我们几乎没有开始计算之前,计算出一条完美的跑步路径以摆脱大草原上的狮子会让我们吃掉。满足感还可以降低生活中的卡路里成本,这也是一样的,因为我们的大脑是非常耗电的设备,尽管体重约为3 磅,但它却吞噬了我们大约五分之一的能量消耗。
我们削减的一些细节才会导致可预见的次优结果。
既然我们大多数人都不会在逃避狮子的日子里度过,我们削减的一些角落会导致可预见的垃圾结果。
我们的大脑并不完全适合现代环境。了解我们的物种将信息转化为行动的方式,可以让您使用决策过程来保护自己免受自己大脑的缺陷(以及那些故意掠夺您本能的人的伤害)。它还可以帮助您构建工具来增强您的性能并让您的环境适应您的大脑。
顺便说一句,如果您认为人工智能将人类排除在外,请再想一想!所有技术都是其创造者的反映,而大规模运行的系统会放大人类的缺点,这就是为什么发展决策智能技能对于负责任的人工智能领导来说如此必要的原因之一。
首要任务应该是弄清楚我们希望如何对事实做出反应。
如果我们有事实,我们总是更喜欢根据事实做出决定。这就是为什么首要任务应该是弄清楚我们希望如何处理事实。您希望将理想信息用于以下哪些用途?
你能用事实做什么?
你可以用事实来做一个单一的重要的预设的决定。如果它足够重要,你就需要在很大程度上倚重事物的定性方面,以明智地构建你的决定。心理学家知道,如果你允许自己被突如其来的信息伏击,它可以以你不喜欢的方式操纵你,所以他们(和其他人)对如何接近选择你预先接受的信息有很多意见。
你可以利用事实来做出一种特殊的预设决策,称为影响(或因果)决策。如果你的决策是以采取某种行动导致某种事情发生为框架的,那么你需要关于因果关系的事实来做出决策。在这种情况下,关于效果的事实(如 "人们从这种疾病中恢复过来")如果不附带关于原因的事实(如 "因为抗生素"),对你来说是没有用的。获得因果关系信息的方法是做一个受控实验。另一方面,如果你做出的执行决定是作为对非因果事实的反应(例如,"如果我的储蓄账户中至少有x,我就会给自己买双新鞋"),那么就没有必要做实验。
你可以用事实来支持观点("我估计外面阳光明媚 "变成 "我知道外面阳光明媚")。
你可以用事实来做一个基于存在的单一重要决定。基于存在的决策("我刚刚发现隔壁就有一例埃博拉病毒,所以我要马上离开这里......")是指这样的决策:一个以前不为人知的未知事物的存在动摇了你的方法的基础,以至于你在事后意识到你的决策背景是草率的框架。
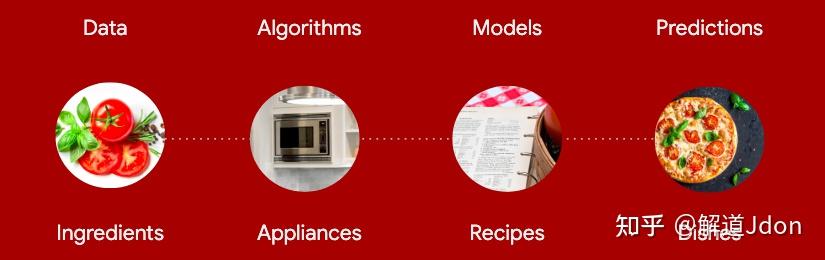
你可以使用事实来自动化大量的决策。在传统的编程中,人类指定了将事实输入转换为适当行动的指令集,可能涉及像查找表这样的东西。
你可以使用事实来揭示一个自动化解决方案。通过看到系统的事实,你可以根据它们来写代码。这比在没有信息的情况下,通过认真思考得出解决方案的结构,是一种更好的传统编程方法。例如,如果你不知道如何从摄氏度转换到华氏度,但你可以用一个数据集来查找与摄氏度输入相匹配的华氏度条目......但如果你分析那个查询表本身,你会发现连接它们的公式。然后你就可以用这个公式("模型")来为你做脏活累活,而丢掉那个笨重的表格。
你可以用事实来生成一个完全可以解决的自动化问题的最优方案。这就是传统的优化。你会在运筹学领域找到许多例子,其中包括如何处理约束条件以获得理想的结果,如完成一系列任务的最佳顺序。
你可以用事实来启发你如何对待未来的重要决策。这是分析学的一部分,它也属于部分信息部分。保持这种想法!
你可以用事实来评估你正在处理的事情。这有助于你了解你在未来的决策中可用的输入类型,并设计如何更好地策划你的信息。如果你刚刚继承了一个大的、黑暗的(数据)仓库,里面充满了潜在的成分,你不会知道里面有什么,直到有人看了它。幸运的是,你的分析师有一个手电筒和旱冰鞋。
你可以马马虎虎地使用事实来做出没有框架的决策。当决策的利害关系足够小,以至于不值得花费精力去仔细处理时,这种做法是有效的,例如,"今天中午我应该吃什么?" 试图对所有的决定都严格要求,会带来次优的长期/终生结果,属于无意义的完美主义范畴。把你的努力留给那些足够重要的情况,但请不要忘记,即使使用低质量低努力的方法是有效的,最佳决策方法仍然是低质量的。当这是你的方法时,你不应该捶胸顿足或过于自信......如果你偷工减料,你就会拿着脆弱的东西。在有些情况下,脆弱的东西能完成工作,但这并不能突然使你的结论变得坚固。不要倚靠它。如果你想要高质量的决策,你需要一个更严格的方法。
通过决策科学的培训,你可以学会减少做出严格的基于事实的决策所需的努力,这意味着同样的工作量现在可以让你获得更高质量的全面决策。这是一项非常有价值的技能,但需要大量的工作来磨练它。例如,行为经济学的学生形成了在获得信息之前设定决策标准的习惯。例如,我们中那些从足够苛刻的决策科学培训课程中受到打击的人,会忍不住问自己,在我们查找价格之前,我们为一张票支付的最高限额是多少。
数据收集和数据工程
如果我们拥有事实,我们就已经完成了。然而,我们生活在现实世界中,我们经常必须为我们的信息而努力。数据工程是一门复杂的学科,其核心是使信息能够可靠地大规模使用。就像去杂货店买一品脱冰淇淋一样容易,当所有可用的相关信息都在一个电子表格中时,数据工程就很容易。
当你开始要求交付200万吨冰激凌时,事情就变得棘手了......在那里它不允许融化! 如果你必须设计、建立和维护一个巨大的仓库,而你甚至不知道未来会要求你储存什么--也许是几吨鱼,也许是钚......祝你好运!事情变得更加棘手了。
当你甚至不知道下周会被要求存储什么时,建立一个仓库是很棘手的--也许是几吨鱼,也许是钚......祝你好运!。
虽然数据工程是一门独立的姐妹学科,也是决策智能的关键合作者,但决策科学包括一个强大的传统,即参与为事实收集的设计和策划提供建议的专业知识。
数据量化:数据科学
当你确定了你的决定,并使用搜索引擎或分析师(为你执行人类搜索引擎的角色)查询了你需要的所有事实,剩下的就是执行你的决定。你已经完成了! 不需要华丽的数据科学。
如果在所有这些腿部工作和工程柔术之后,所提供的事实并不是你理想中的决策所需的事实,那怎么办?如果它们只是部分事实呢?也许你想要明天的事实,但你只有过去的信息。(也许你想知道你所有的潜在用户对你的产品的看法,但你只能问他们中的一百个。那么你就在处理不确定性!你所知道的不是你希望的那样。你所知道的并不是你希望知道的。进入数据科学!
当你被迫做出超越数据的跳跃时,数据科学就变得有趣了......但要注意避免出现伊卡洛斯式的飞溅
当然,当你所拥有的事实不是你所需要的事实时,你应该期望你的方法会有所改变。也许它们是更大的拼图中的一块(如从更大的人群中抽取的样本)。也许它们是错误的拼图,但却是你所拥有的最好的拼图(就像用过去来预测未来)。当你被迫做出超越数据的跳跃时,数据科学就会变得很有趣......但要小心避免出现伊卡洛斯式的飞溅!"。
你可以利用部分事实,用统计推理的方式做出一个重要的预设决策,用假设来补充你所拥有的信息,看看你是否应该改变你的行动。这就是常数派(经典)统计。如果你在做一个影响决策(以采取行动导致某些事情发生为框架,例如,"你只想把你的标志颜色改为橙色,如果这能导致更多的人访问你的网站"),那么最好是使用随机对照实验的数据。如果你正在做一个执行决定(例如,"如果至少有25%的用户认为橙色是他们最喜欢的颜色,你才会想把你的标志颜色改成橙色"),调查或观察研究就足够了。
你可以使用部分事实来合理地将意见更新为更有根据的(但仍然是不完美的和个人的)意见。这就是贝叶斯统计。如果这些意见涉及因果关系,最好使用受控随机实验的数据。
你的部分事实可能会变成包含关于存在的事实,这意味着你可以在事后将它们用于基于存在的决策(见上文)。
你可以使用部分事实来实现大量决策的自动化。这就是传统的编程,使用类似查找表的东西,将你以前没有见过的东西转换成你所拥有的最接近的东西,然后照常进行。(这就是k-NN的工作,简而言之......而且当这个简表有更多的东西时,它通常工作得更好。)
你可以使用部分事实来激发一个自动化解决方案。通过看到系统的部分事实,你仍然可以根据你所看到的编写代码。这就是分析学。
你可以使用部分事实来生成一个体面的解决方案,以解决一个不完全可解决的自动化问题,这样你就不必自己想出来了。这就是机器学习和人工智能。
你可以使用部分事实来启发你如何对待未来的重要决策。这就是分析学。
你可以使用部分事实来理解你正在处理的问题(见上文),并通过高级分析来加速自动化解决方案的发展,例如,通过激发新的方法来将信息混合在一起,形成有用的模型输入(这的行话是 "特征工程")或在人工智能项目中尝试新方法。
你可以马虎地使用部分事实来做无框架的决策,但要注意,质量比你马虎地使用事实时还要低,因为你实际知道的东西与你希望知道的东西相差一步。
对于所有这些用途,有一些方法可以整合来自各种以前口口相传的学科的智慧来更有效地接近决策。这就是决策智能的意义所在! 它汇集了关于决策的各种观点,这些观点使我们所有人都更加强大,并赋予它们一种新的声音,摆脱了其原始研究领域的传统限制。