软件设计是一个不断发展的过程。每一个大系统都是从一个小系统开始的。当现有架构遇到问题但无法解决时,系统将开始演进。每一次进化都伴随着一些技术选择。应该解决哪些问题?它会付出怎样的代价?作为架构师或高级工程师,必须找到合理的演进方式,无论开发进度、技术堆栈、团队水平如何,都必须能够满足这些标准,然后才能做出可行的解决方案。
本文将介绍CQRS(Command Query Responsibility Segmentation)的精神和要解决的问题。我们将从一个小的单体开始,像每个软件系统的演进一样进行演进,本文将介绍每个演进背后的原因和方法。
传统的单体架构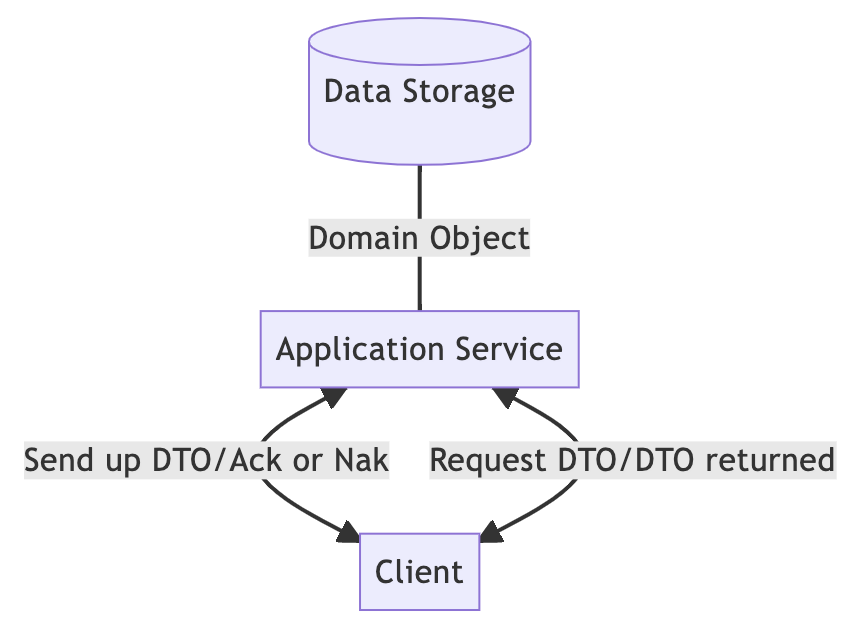
这是最常见的系统设计。有一个 API 服务器,通常是一个 RESTful API 和一个数据库。客户端提前与后端协商传输格式。读取和写入都是通过数据传输对象 DTO 完成的。而后端在处理业务逻辑时,会将DTO转化为具有领域知识的领域对象,并以领域对象作为数据库的存储单元。
为了实现Read/Write Splitting,在左边的写路径中,客户端向上发送DTO到后端对数据库进行CUD(create/update/delete)操作,后端用Ack响应客户端success 和Nak为处理后的失败。在restful API中,通常2xx代表成功,4xx代表失败。右边的读路径简单的通过读请求获得对应的DTO。
我进一步为客户解释了DTO的含义。客户端上的 DTO 通常包含要在屏幕上呈现的所有数据。例如,当您在社交媒体上查看您的个人资料时,它将包括您的姓名、帐户和其他个人信息,以及您自己最近的活动,甚至是您关注的活动。DTO 包含需要在此页面上显示的所有信息。
为什么我们需要强调读/写拆分?我们不能在读写路径上使用相同的过程吗?因为我们希望在未来更好地优化我们的系统。写路径有特定的优化方法,读路径也有。例如,要制作缓存,可以在读取路径上使用只读缓存来减少响应时间。并且,可以通过缓存写入来改进写入路径。其次,写入也可以异步执行。所有的 DTO 都写入消息队列,由 Worker 处理,以处理大量写入的数据。此外,每个适当的数据库都可以用于写入和读取。
因此,读/写拆分是必不可少的。并且在系统设计的早期阶段就应该考虑到这一点。写入路径是专注于数据持久化;而读取路径则专注于数据查询。
然而,这种系统设计模型存在两个主要问题。
- 贫血模型。它也被称为 CRUD 模型。当后端专注于数据转换时,很难有处理业务逻辑的空间,这会导致业务逻辑四处分散。领域知识也会消失,例如对于电子商务网站,我们会说“购买”而不是“插入订单记录”。
- 可扩展性不足。从系统架构来看,数据库很容易成为整个系统的瓶颈。阅读和写作都必须在上面。由于没有水平扩展,RDBMS 的问题更加严重。
基于任务的单体
为了解决上述传统单体所遇到的问题,这里我们尝试引入域的概念。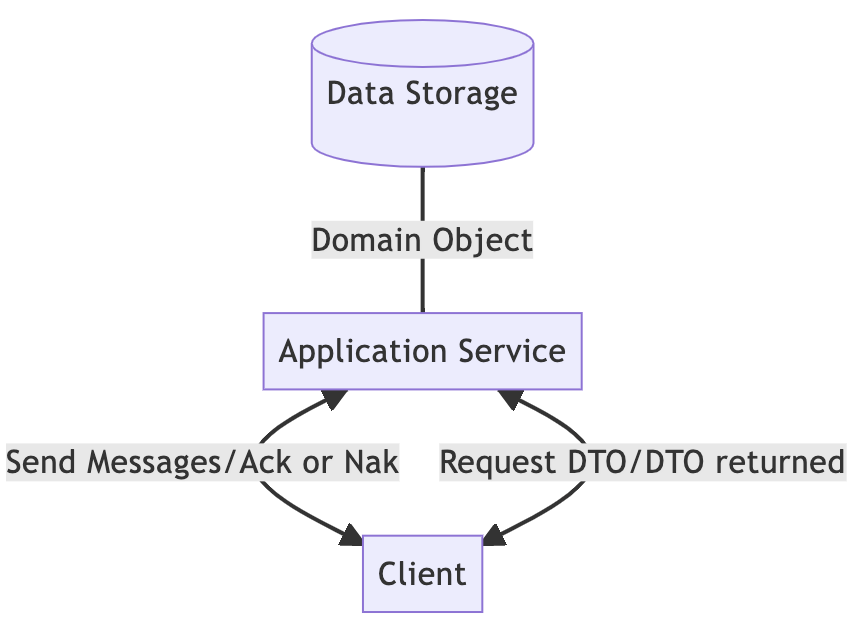
此图与上图基本相同。唯一的区别是将 DTO 替换为写入路径上的消息。消息包含操作和数据,而不仅仅是像 DTO 这样的数据本身。因此,我们可以在消息中携带特定领域的动作,使后端更容易识别每个动作,并有相应的领域实现。
在这个阶段,C inCQRS已经出现,message 是一种命令。但是,可扩展性的问题仍然没有解决。
另外,虽然我们简化了DTO,改为使用消息进行通信,但在读取路径上仍然需要DTO。让我们再次以社交媒体为例。修改昵称时,消息的格式可能是{"rename": "LazyDr"}. 但是在渲染配置文件时,我们仍然需要额外的信息,例如活动。这种信息差距使得有必要在读取路径上进行大量处理以检索 DTO。
CQS(命令查询分段)
CQS的出现就是为了解决上述Read/Write Splitting的痛点。
读取时,客户端需要DTO,所以后端可以在读取路径上做一些专门用于读取的优化,比如从原始域对象预先生成DTO,将DTO存储在专用数据库中进行读取。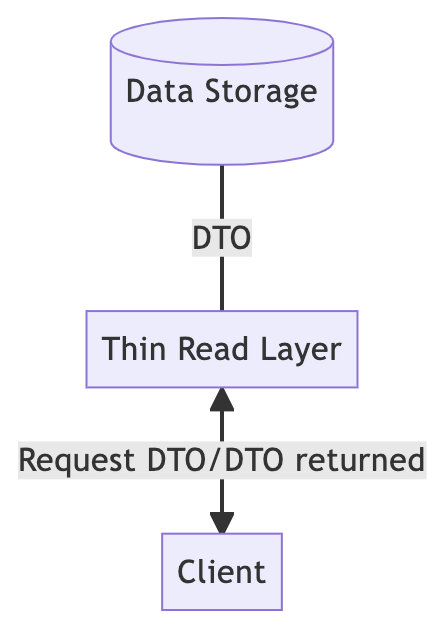
这样,在读路径上,应用服务的实现就变得更简单了。应用服务可以变成一个瘦读层,只需要负责分页、排序等工作,客户端请求之后,就可以很方便的从数据库中取回DTO。
所以问题是,谁来生成这些预先构建的 DTO?这是写路径的责任。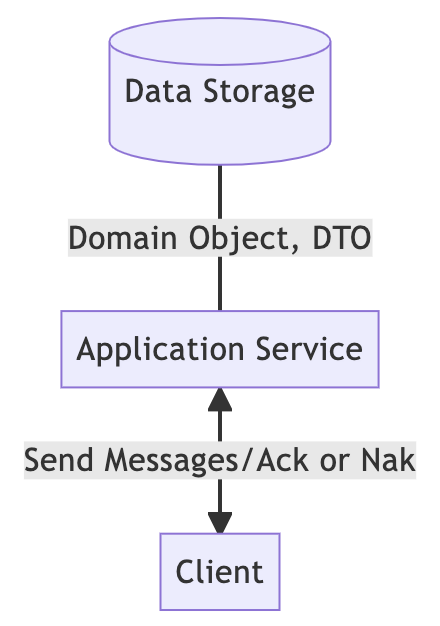
虽然图和之前看到的例子差不多,但其实应用服务除了要持久化领域对象外,还必须要持久化DTO。也就是说,大部分业务逻辑都会压在写路径上,需要准备各种读视图。
在这个阶段,我们已经解决了领域遇到的大部分问题,但是缩放仍然没有解决方案。现在,我们进一步定义缩放。缩放有两个不同的方面。
- 流量:写入量增加。
- 扩展:功能需求增加,比如需要各种不同的读取视图。继续以社交媒体为例,个人资料上有一个演示文稿,但时间轴上可能有另一个演示文稿。
CQRS
为什么写路径负责准备读视图?写应该关注持久化,那些各种读视图不应该在写路径上处理。但是读取路径上只有读取,谁应该准备那些读取视图?
因此,整体解决方案如下。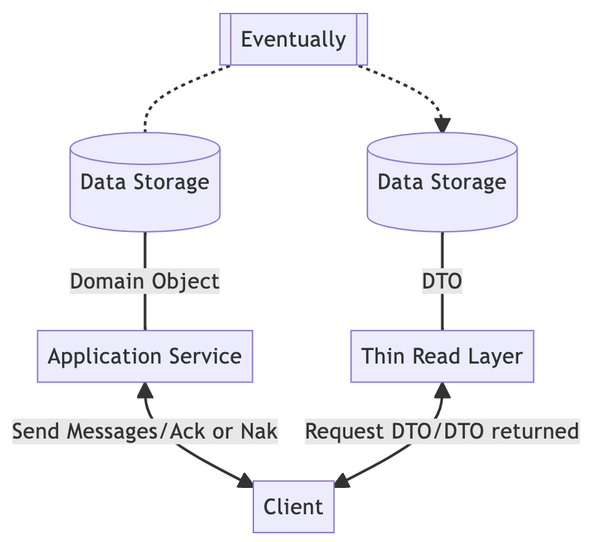
左边的写路径和右边的读路径已经在CQS部分介绍过了。唯一的区别是添加了一个finally块,负责将写路径上的数据库转换成读路径上使用的数据库。一旦涉及到数据同步,就有可能遇到数据一致性问题,所以这里列出了几种实现最终一致性的方法,按照耗时从短到长排序:
- 后台线程:典型代表是Redis。数据写入主节点后,Redis 会立即将数据发送到后台的副本。
- 消息队列加工作者:这是异步数据复制的常见做法。写入数据库时,会在消息队列中启动一个事件并由工作人员处理。
- Extract-Transform-Load:这个时间间隔最长,从几分钟到几小时不等。使用 map-reduce 或其他方法将结果写入另一端。
无论采用哪种方法,唯一的事实来源都是强制性的。也就是说,如果转换发生任何故障,系统必须能够恢复未完成的工作。因此,数据必须是唯一且可靠的。
数据通常分为两种类型,
- state:state 是指你此刻看到的,比如银行存折上写的余额。
- 事件:事件是修改每个状态的动作,例如银行存折上的每笔交易记录
实际上,我们已经有了可以存储为事件的消息。对于写路径,按顺序存储消息是非常有效的。通过每条不同的消息,您可以根据需要轻松构建不同的阅读视图。这种方法也称为事件溯源。
但是只有事件很难有效地使用。为了获得最终结果,每次转换都必须从头到尾运行以重建读取视图。因此,混合方法将是理想的。在写路径上,状态和事件都保留,转换过程可以根据实际情况选择数据源。
总结一下CQRS中数据的整个生命周期。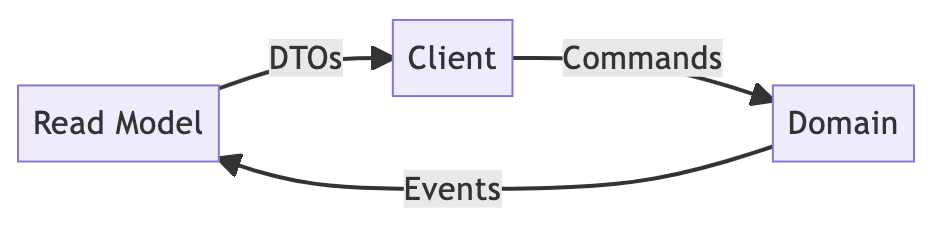
数据从客户端开始,然后以命令格式进入后端。根据业务逻辑,将其转换为领域对象并存储在数据库中。这些领域对象被转换成各种读取视图,并根据需要存储在不同的读取专用数据库中。最后,客户端将这些读取视图以 DTO 的形式取回。
结论
有许多书籍和文章描述了具有多种模式的 DDD 和 CQRS。在我看来,这些模式限制了实体、值对象、聚合等 DDD 的想象力。这导致大多数开发人员觉得 DDD 离自己很远,很难实现和实现。实际上,DDD 的概念并没有那么复杂;相反,DDD被提出来封装业务逻辑,然后方便扩展功能需求。
CQRS 更简单。在这篇文章中,我们从系统演化的过程入手,了解整个系统设计过程和要解决的问题,最后自然得出CQRS的结论。
系统设计中没有灵丹妙药。每次进化都是为了解决一些特定的问题,然而,它可能会出现一个新的问题。以本文的设计过程为例,CQRS 似乎解决了所有提到的问题,模型贫乏,可扩展性不足,但实际上 CQRS 也带来了新的问题,比如数据一致性。每个技术选择都有它的取舍,只要了解每个选项背后的所有威胁,就可以选择相对可接受的方法。
即使你选择了 CQRS,在实践中,实现最终一致性仍然有三种选择。系统设计是不断选择的结果。
这篇文章的目的是告诉你,DDD 没有那么可怕,CQRS 也没有那么复杂,它只是一个决定。