分布式系统中最常见的可靠性模式之一是限制任务处理的速率。此任务可以是要处理的请求或事件。这样做是为了平滑流量的形状并避免流量突发,或者在底层系统运行时仅允许在任何给定时间进行最大特定数量的操作。速率限制器模式用于负载均衡器、公共 API以及作为不同层的网络策略的一部分。
实现速率限制器的一种方式是一种称为“漏桶”算法的算法。我也看到这在面试中成为编码挑战。尽管我知道该算法,但我自己从未实现过。通常使用算法实现概念验证可以帮助我更好地理解设计决策和注意事项。在写这篇文章时,我借此机会使用 Go 的泛型,我以前也没有使用过。
算法背后的想法很简单:想象有一桶任务正在被传入的任务填充。这个桶底部还有孔,任务可以滴入任务处理器。
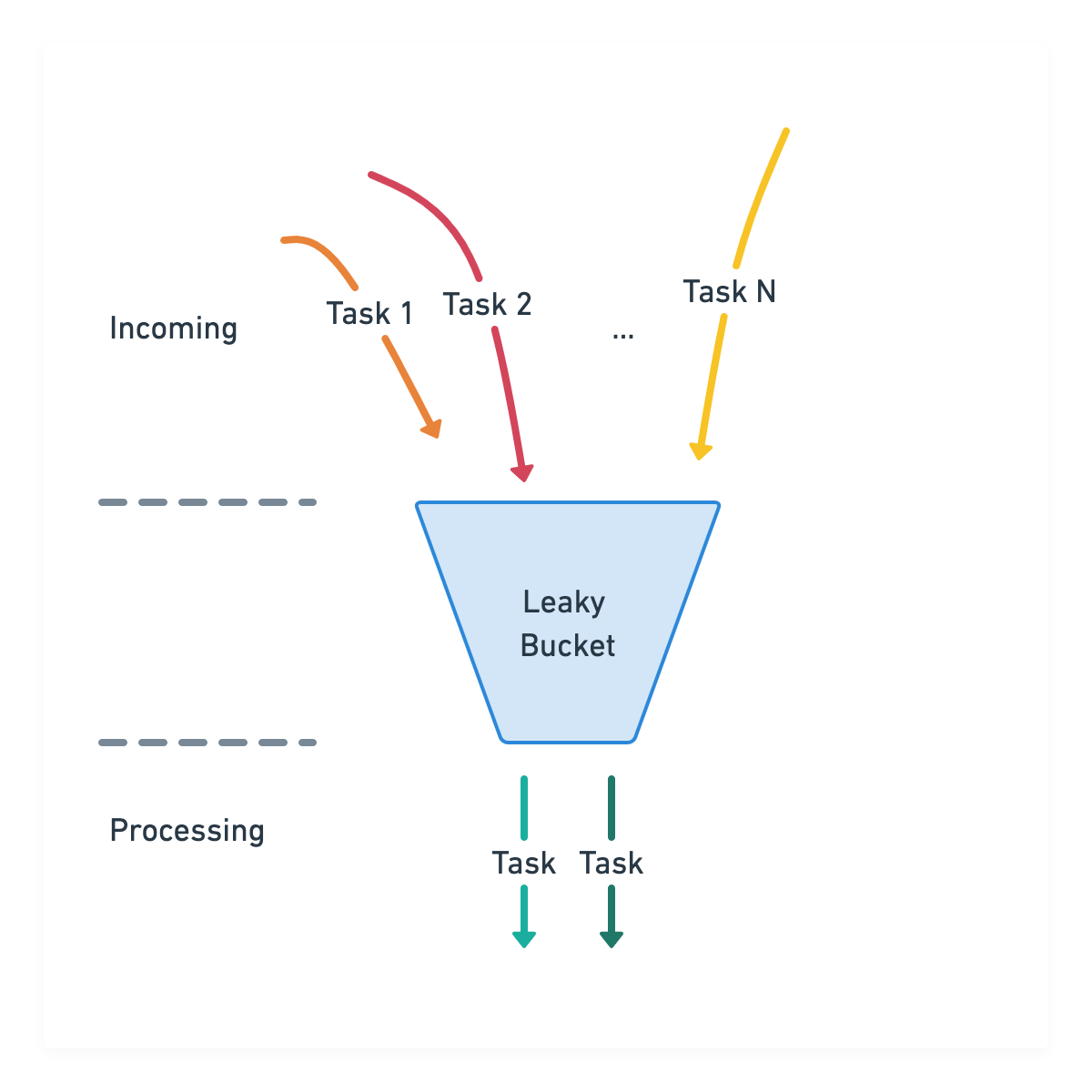
存储桶可能处于以下几种状态:空、满或正在处理一些任务但既不空也不满。只要桶没有装满,它就会一直以恒定的速率将任务交给处理器。当它已满时,它应该“溢出”并且在某些任务完成之前不允许传入任务。
这概述了漏桶速率限制器应该如何工作。现在让我们来看看实现。
我通常从定义我想向外界公开的接口开始。这些 API 在开发过程中是流动的,但它让我扎根于抽象层并隐藏了实现的复杂性:
速率限制器的接口定义:
package main
// Task is an abstraction that represents a task that can be submitted to the rate
// limiter for processing.
type Task interface {
}
type RateLimiter[T Task] interface {
// Start initializes the rate limiter and starts the intake & processing of
// tasks. Until it's called, no task is processed.
Start()
// Stop stops the intake & processing of tasks. Once Stop is called, until Start
// is called again, the rate limiter stays inactive.
Stop()
}
|
它们还允许作者独立于向用户公开的内容发展实现,并通过统一的接口支持不同的选项,例如不同的速率限制策略。尽管Task当前可以是任何东西,但我认为最好从抽象层开始以保持其灵活性。例如,在未来,我们可能决定为任务实现不同的权重——这意味着有些可能比其他的更昂贵,并且在桶中占据更多位置。现在,我们将一视同仁。
遵循相同的思路,定义用户将与之交互的另一个部分是我的下一步:
package main
// NewLeakyBucketRateLimiter returns a RateLimiter that uses the "leaky bucket"
// algorithm to limit the rate tasks added to the input channel are being
// processed. These tasks are passed to the output channel at a maximum rate
// denoted by "ratePerSecond". "input" & "output" may be a buffered channels
// that can be used to control the max concurrency the bucket can be filled
// and emptied.
//
// Once either of these channels are closed, the rate limiter will
// not be able to rate limit & output further tasks.
func NewLeakyBucketRateLimiter[T Task](
ratePerSecond uint,
input <-chan T,
output chan<- T,
) RateLimiter[T] {
// TODO
}
|
以上是漏桶限速器构造函数选择使用Go 通道从速率限制器提交和读取任务是我做出的选择,因为我认为它会产生一个更简单的实现,更容易在本文中消化,但它可能不是在生产中使用的最佳选择。
通道带来的另一个有趣的特性是用户可以控制任务输入和输出的并发级别。这在语言规范中解释如下:
容量(以元素数量计)设置通道中缓冲区的大小。如果容量为零或不存在,则通道是无缓冲的,并且只有在发送方和接收方都准备好时通信才会成功。否则,如果缓冲区未满(发送)或非空(接收),则通道被缓冲并且通信成功而不会阻塞。
您可以将输出通道的容量视为从桶中滴出的速率任务,而输入通道的容量可以视为桶的大小。当我们达到这些限制时,发送者或处理器将被阻止,直到通道不再满为止。我们将在本文后面看到如何处理存储桶已满的情况。
接下来,我们研究RateLimiter使用漏桶算法实现接口。
我们首先定义内部结构,例如我们在执行期间需要的参数以及保持速率限制器当前状态的其他参数:
package main
import (
"sync"
"time"
)
type lbLimiter[T Task] struct {
sync.Mutex
interval time.Duration
pollInterval time.Duration
out chan<- T
in <-chan T
running bool
}
|
在这里,interval表示将任务传递到输出通道之间的理想时间,而pollInterval尝试从输入通道读取任务之间的时间。此外,running它是一个私有变量,指示速率限制器是否“活动”——这意味着它正在尝试从输入和输出通道读取和写入。由于我们可能正在处理多线程环境,因此我选择使用sync.RWMutex以确保在检查其状态时没有并发写入。
func (l *lbLimiter[T]) Start() {
l.Lock()
defer l.Unlock()
l.running = true
go func() {
for l.isRunning() {
select {
case w := <-l.in:
go func() { l.out <- w }()
time.Sleep(l.interval)
default:
time.Sleep(l.pollInterval)
}
}
}()
}
|
在通过我们的构造函数创建速率限制器后,用户需要调用该Start方法,该方法主要做两件事:通过running字段将自己标记为“活动”并启动一个执行主要任务的goroutine——从输入中读取并传递任务到输出通道进行处理。如果输入通道中有待处理的任务,我们会将其传递给输出通道并休眠一段时间,让我们以每秒任务数的速度吐出任务ratePerSecond。否则,我们将稍等片刻,直到我们再次尝试从输入通道读取。阻塞来自输入通道的接收操作将是另一种选择,但是在这种情况下,如果用户想要停止速率限制,我们需要关闭输入通道以摆脱阻塞状态。这就是为什么我在这里选择从输入通道中轮询项目的原因。
Stop方法很简单:
func (l *lbLimiter[T]) Stop() {
l.Lock()
defer l.Unlock()
l.running = false
}
func (l *lbLimiter[T]) isRunning() bool {
l.RLock()
defer l.RUnlock()
return l.running
}
|
它设置了running由轮询输入通道中的任务的 goroutine 检查的标志。设置标志后,它将停止轮询并退出。最后,让我们看一下如何通过示例应用程序使用这个速率限制器:
func main() {
out := make(chan int64)
in := make(chan int64, 10)
// Create a rate limiter that allows processing 5 tasks / second
rl := NewLeakyBucketRateLimiter[int64](5, in, out)
rl.Start()
// Stop processing tasks in 10 seconds and exit the program
go func() {
time.Sleep(10 * time.Second)
rl.Stop()
close(out)
}()
// Try adding tasks at a rate of 10 tasks / seconds
go func() {
for i := 0; ; i++ {
ts := time.Now().Format(time.RFC3339)
select {
case in <- int64(i):
fmt.Printf("[%s] Added one item in the bucket\n", ts)
default:
fmt.Printf("[%s] The bucket is full\n", ts)
}
time.Sleep(time.Millisecond * 100)
}
}()
// Process tasks
t := time.Now()
for c := range out {
now := time.Now()
dt := now.Sub(t)
t = now
fmt.Printf("[%s] Ran the operation %d after %d milliseconds\n",
now.Format(time.RFC3339), c, dt.Milliseconds())
}
}
|
在构建了速率限制器之后,我们设置了一些东西来为处理任务做准备:一个 goroutine 将任务添加到输入通道中,另一个控制何时停止处理以避免无限期地运行示例程序。
这里要注意的另一部分是如何处理“满桶”:使用selectwhile 将任务发送到输入通道,我们可以检查输入通道或桶何时满并调整我们的行为。在现实世界的场景中,我们可能会返回一个响应,例如带有429 Too Many Requests 状态代码的 HTTP 响应,表明他们已经超过了对这些用户的速率限制。在这种情况下,我们记录存储桶已满,并在一段时间后继续尝试。
还有其他策略,例如“令牌桶”,可以替代漏桶算法。如果你有一个有趣的速率限制策略。
可以在这里找到完整的代码