两个月前我组装了ngods(新一代开源数据堆栈),并从那时起将它用于我的朋友的两个项目。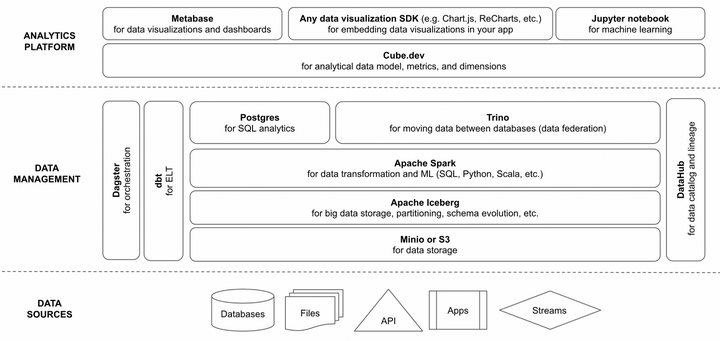
这个堆栈可以很好地从小数据(几 GB)扩展到中型数据(几百 GB)。它也比使用基于使用定价的类似云组件(例如,Snowflake、Redshift 或 BigQuery)更便宜。
我创建了一个简单的演示来展示它的功能。您可以将此演示用作项目的起点。
该演示可在此GitHub 存储库中找到。它从 Yahoo Finance API 检索所选股票代码的数据历史,将其存储在数据仓库中,对其进行转换,并为机器学习预测和数据可视化提供分析模型。
该演示使用具有三个数据阶段的奖章架构:bronze, silver, 和gold.。
架构:
- bronze数据阶段以其原始数据源的形式存储数据。此阶段使用Apache Iceberg进行数据存储。
- silver数据阶段存储混合了铜牌阶段的原始数据的清理和转换数据。这个阶段也使用了 Apache Iceberg。
- gold数据阶段实施分析模型(维度、事实等)。我决定在这个阶段使用 Postgres 数据库。
ngods 数据堆栈使用dbt在每个数据阶段之间和内部转换数据。dbt 在Apache Spark中执行 SQL,用于bronze与silver阶段的数据转换:
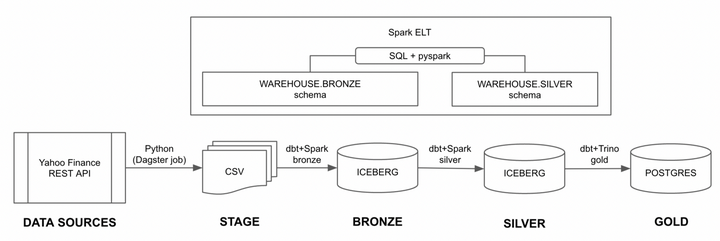
由于gold阶段使用 Postgres,dbt 必须在silver数据阶段和gold数据阶段之间移动数据。我决定使用Trino数据联合:Trino 将所有medallion数据阶段映射到一个数据库中的模式: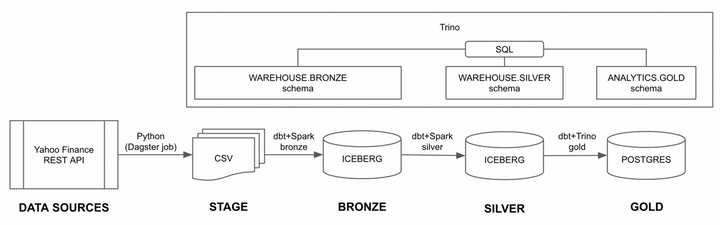
ngods 使用Dagster来编排数据仓库初始化、库存数据下载和 dbt 数据转换。我喜欢 Dragster 使用 Python 代码的可扩展性: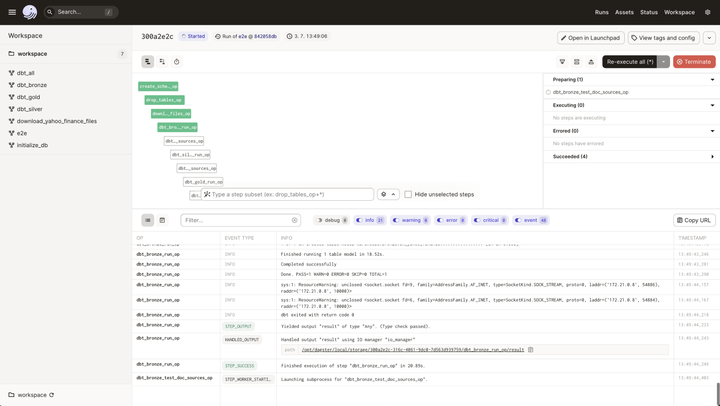
我使用cube.dev和Metabase构建了分析层。cube.dev 公开了一个带有维度和指标的无头分析模型: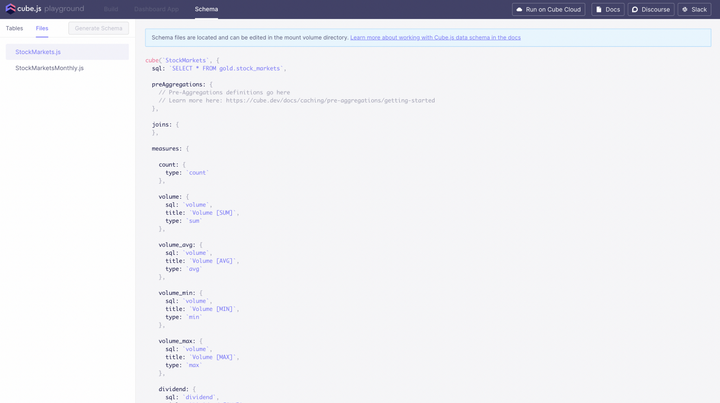
元数据库连接到此模型以进行数据可视化(报告和仪表板):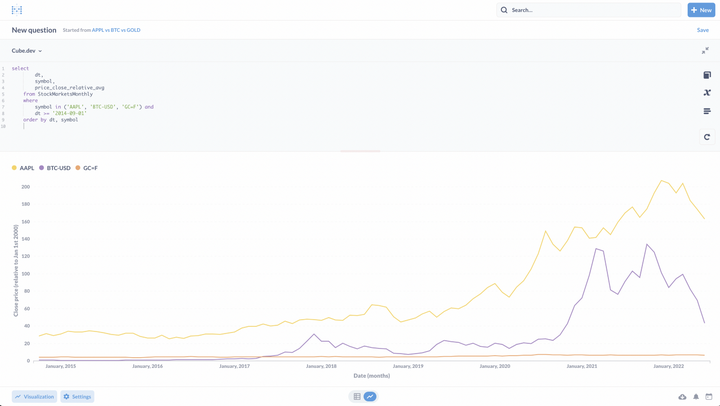
我还使用Jupyter notebook进行机器学习预测未来股票趋势(ARIMA 时间序列模型):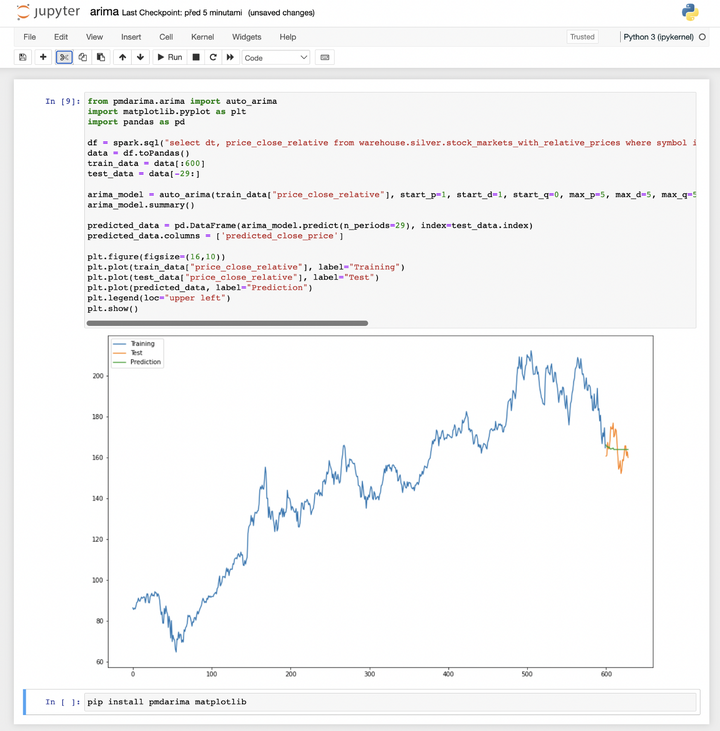
最后但同样重要的是,所有表和分析工件都发布到DataHub数据目录: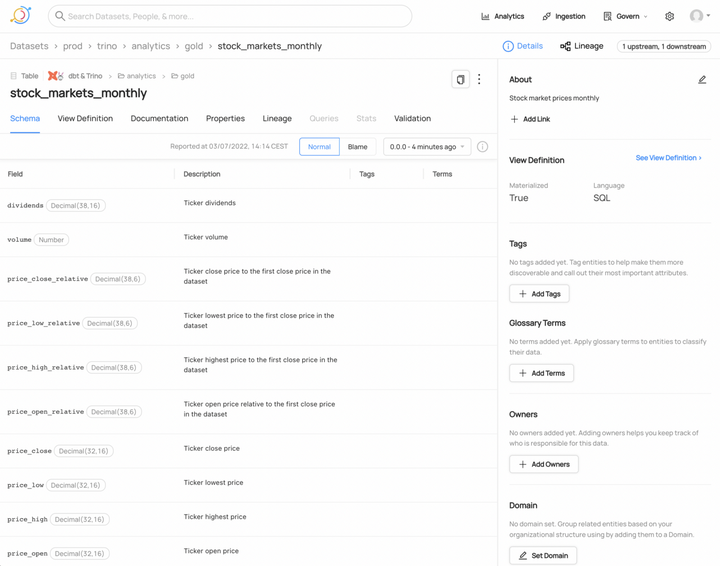
安装步骤
您可以通过几个快速步骤运行此演示:
1. 克隆 [ngods repo](https://github.com/zsvoboda/ngods-stocks)
git clone https://github.com/zsvoboda/ngods-stocks.git
2.为您的 CPU 架构选择docker-compose脚本
cd ngods-stocks
# use the docker-compose.x86.yml for Intel CPU
cp docker-compose.x86.yml docker-compose.yml
# use the docker-compose.arm64.yml for ARM (e.g. Apple M1/M2)
cp docker-compose.arm64.yml docker-compose.yml
3. 使用docker-compose up命令启动它
docker-compose up -d
这可能需要很长时间,具体取决于您的网络速度。
4. 使用docker-compose down命令停止它
docker-compose down
然后您可以探索演示端点:
演示报告和笔记本
带有 ARIMA 股票价格预测的用于 APPL 股票代码的Jupyter 笔记本
比较 APPL、BTC 和 GC=F(黄金)股票代码历史趋势的元数据库报告
Cube.dev 报告
演示报告和notebooks
- 带有 ARIMA 股票价格预测的用于 APPL 股票代码的Jupyter 笔记本
- 比较 APPL、BTC 和 GC=F(黄金)股票代码历史趋势的元数据库报告
- Cube.dev 报告
Spark
- http://localhost:8888 : Jupyter 笔记本
- jdbc:hive2://localhost:10000JDBC URL(无用户名/密码)
- localhost:7077 : Spark API 端点
- http://localhost:8061:Spark主节点监控页面
- http://localhost:8062 : Spark 从节点监控页面
- http://localhost:18080 : Spark 历史服务器页面
Trino
- jdbc:trino://localhost:8060JDBC URL(用户名trino/无密码)
Cube.dev
- http://localhost:4000 : cube.dev 开发界面
- jdbc:postgresql://localhost:3245/cubeJDBC URL(用户名cube/密码cube)
Metabase元数据库
- http://localhost:3030:元数据库 UI(用户名metabase@ngods.com/密码metabase1)
Dagster
- http://localhost:3070 : Dagster 编排界面
DataHub数据中心
- http://localhost:9002:DataHub 目录 UI
Postgres
- jdbc:postgresql://localhost:5432/postgresJDBC URL(用户名postgres/密码postgres)
Minio
- http://localhost:9001:Minio UI(用户名minio/密码minio123)