学习领域驱动设计、软件架构、设计模式、最佳实践,该项目的主要重点是提供有关如何设计软件应用程序的建议。本自述文件中介绍了从不同来源收集的一些技术、工具、最佳实践、架构模式和指南。
代码示例是使用NodeJS、TypeScript、NestJS框架和Typeorm 编写的,用于数据库访问。
虽然这里介绍的模式和原则与框架/语言无关,但上述技术可以很容易地被任何替代方案替换。无论使用什么语言或框架,任何应用程序都可以从下面描述的原则中受益。
注意:代码示例适用于 TypeScript 和上述框架,其他语言的实现看起来会有所不同。
架构特点:
主要依据:
以及许多其他来源(每章下面有更多链接)。
在我们开始之前,这里是使用这样一个完整架构的优点和缺点:
优点
- 独立于外部框架、技术、数据库等。框架和外部资源可以更轻松地插入/拔出。
- 易于测试和扩展。
- 更安全。一些安全原则已经融入设计本身。
- 该解决方案可以由不同的团队进行工作和维护,而不会互相干扰。
- 更容易添加新功能。随着系统随着时间的推移而增长,添加新功能的难度保持不变且相对较小。
- 如果解决方案沿有界上下文线正确分解,则可以在需要时轻松将其部分转换为微服务。
缺点
- 这是一个复杂的架构,需要对质量软件原则有深刻的理解,例如 SOLID、清洁/六边形架构、领域驱动设计等。任何实施此类解决方案的团队几乎肯定需要专家来推动解决方案并保持它从发展错误的方式和积累技术债务。
- 此处介绍的一些实践不推荐用于业务逻辑不多的中小型应用程序。增加了前期复杂性以支持所有这些构建块和层、样板代码、抽象、数据映射等。因此,实现这样的完整架构通常不适合简单的CRUD应用程序,并且可能会使此类解决方案过于复杂。下面描述的一些原则可用于较小规模的应用程序,但必须在分析和了解所有优缺点后才能实施。
流程: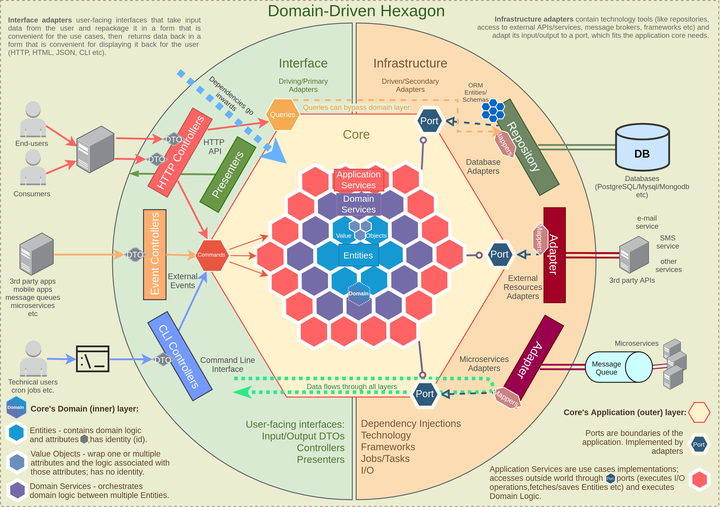
数据流是这样的(从左到右):
- 使用普通 DTO 将请求/CLI 命令/事件发送到控制器;
- 控制器解析这个 DTO,将其映射为命令/查询对象格式并将其传递给应用程序服务;
- 应用服务处理这个命令/查询;它使用域服务和/或实体执行业务逻辑,并通过端口使用基础设施层;
- 基础设施层使用映射器将数据转换为所需的格式,使用存储库获取/持久化数据,使用适配器发送事件或进行其他 I/O 通信,将数据映射回域格式并将其返回给应用程序服务;
- 应用程序服务完成其工作后,它会将数据/确认返回给控制器;
- 控制器将数据返回给用户(如果应用程序有演示者/视图,则返回它们)
每一层都负责自己的逻辑,并具有构建块,这些构建块通常应在可能且有意义的情况下遵循单一职责原则Repositories(例如,仅用于数据库访问、Entities用于业务逻辑等)。
请记住,不同的项目可能具有比此处描述的更多或更少的步骤/层/构建块。如果应用程序需要,可以添加更多,如果应用程序不是那么复杂并且不需要所有抽象,则跳过一些。
对任何项目的一般建议:分析应用程序的规模/复杂程度,找到折衷方案并根据项目需要使用尽可能多的层/构建块,并跳过可能过于复杂的层。
模块
本项目的代码实例采用了模块(也称为组件)的分离方式。每个模块的名字都应该反映领域中的一个重要概念,并有自己的文件夹和专门的代码库,该模块中的每个业务用例都有自己的文件夹来存储它所需要的大部分东西(这也叫垂直切分)。如果这些东西相对聚集在一起,就更容易在一起工作,因为这些东西都是相对靠近的。把模块想象成一个 "盒子",把相关的业务逻辑集中起来。
使用模块是封装高度凝聚的业务领域规则的一部分的好方法。
尽量使每个模块都是独立的,并使模块之间的互动最小。把每个模块看作是一个由单一上下文约束的小型应用程序。考虑模块内部的私有性,尽量避免模块间的直接导入(比如从'.../SomeOtherModule'导入一个类import SomeClass),因为这样会产生紧密的耦合,会使你的代码变成意大利面条,应用程序变成一个大泥球。
有几个建议可以避免耦合:
- 尽量不要在模块或用例之间建立依赖关系。相反,把共享的逻辑移到一个单独的文件中,让两者都依赖它,而不是相互依赖。
- 模块可以通过调解器或公共门面进行合作,隐藏模块的所有私有内部信息,以避免其被滥用,并只让公众访问某些本应公开的功能。
- 另外,模块之间可以通过使用消息进行交流。例如,你可以使用命令总线发送命令,或者订阅其他模块发出的事件(关于事件和命令总线的更多信息见下文)。
这确保了松散的耦合,模块内部的重构可以更容易完成,因为外部世界只依赖于模块的公共接口,如果边界上下文定义和设计得当,每个模块可以很容易地被分离成一个微服务,如果需要的话,无需触及任何领域逻辑或重大重构。
保持你的模块很小。你应该能够在较短的时间内重写一个模块。这不仅适用于模块模式,也适用于一般的软件开发:对象、函数、微服务、流程等。保持它们的小型和可组合性。这在不断变化的软件开发环境中是非常强大的,因为当你的需求改变时,改变小模块比改变大程序要容易得多。你可以在几天内删除一个模块并从头开始重写它。这个想法将在本讲座中进一步描述:Greg Young - The art of destroying software.
代码示例:
- 检查src/modules目录结构。
- src/modules/user/commands - 用户模块中的“commands”目录包括模块可以执行的业务用例(命令),每个用例都有自己的 Vertical Slice。
应用核心
这是使用DDD 构建块构建的系统的核心:
领域层:
- 实体
- 聚合
- 域服务
- 值对象
- 域错误
应用层:
- 应用服务
- 命令和查询
- 端口
应用服务
也称为“工作流服务”、“用例”、“交互者”等。这些服务编排了执行客户端强加命令所需的步骤。
- 通常用于协调外部世界如何与您的应用程序交互并执行最终用户所需的任务。
- 不包含特定领域的业务逻辑;
- 对标量类型进行操作,将它们转换为域类型。标量类型可以被认为是领域模型未知的任何类型。这包括原始类型和不属于域的类型。
- 声明对执行域逻辑所需的基础设施服务的依赖关系(通过使用端口)。
- 用于Entities通过端口从数据库/外部世界获取域(或其他任何内容);
- 通过端口执行其他进程外通信(如事件发送、发送电子邮件等);
- 在与一个实体/聚合交互的情况下,直接执行其方法;
- 如果使用多个实体/聚合,请使用 aDomain Service来编排它们;
- 基本上是Command/Query处理程序;
- 不应该依赖其他应用程序服务,因为它可能会导致问题(如循环依赖);
端口
端口是定义应由适配器实现的协定的接口。例如,一个端口可以抽象技术细节(比如使用什么类型的数据库来检索一些数据),基础设施层可以实现一个适配器,以便执行一些与技术细节而不是业务逻辑更相关的操作。端口就像业务逻辑不关心的技术细节的抽象。[url=https://en.wikipedia.org/wiki/Hexagonal_architecture_(software)]在Hexagonal Architecture[/url]中使用最活跃的名称“端口” 。
在应用程序核心依赖点向内。外层可以依赖于内层,但内层从不依赖于外层。应用程序核心不应依赖框架或直接访问外部资源。任何对进程外资源的外部调用/从远程进程检索数据都应该通过ports(接口)完成,类实现在基础设施层的某处创建并注入应用程序的核心(依赖注入和依赖倒置)。这使得业务逻辑独立于技术,便于测试,允许轻松插入/拔出/交换任何外部资源,使应用程序模块化和松散耦合。
- 端口基本上只是定义必须做什么而不关心它是如何完成的接口。
- 可以创建端口以从域中抽象出副作用,例如 I/O 操作和数据库访问、技术细节、侵入性库、遗留代码等。
- 通过抽象副作用,您可以通过模拟实现来单独测试您的应用程序逻辑。这对于单元测试很有用。
- 应该创建端口以满足域需求,而不是简单地模仿工具 API。
- 模拟实现可以在测试时传递给端口。模拟使您的测试更快且独立于环境。
- 如果需要,端口提供的抽象可用于向端口注入不同的实现(多态性)。
- 在设计端口时,请记住接口隔离原则。在有意义的情况下将大型接口拆分为较小的接口,但也要记住在不必要时不要过度使用。
- 端口还可以帮助延迟决策。领域层甚至可以在决定使用什么技术(框架、数据库等)之前实现。
注意:由于大多数端口实现是在应用程序服务中注入和执行的,因此应用层可能是保留这些端口的好地方。但是有时域层的业务逻辑依赖于执行一些外部资源,在这种情况下,这些端口可以放在域层中。
注意:滥用端口/接口可能会导致不必要的抽象并使您的应用程序过于复杂。在很多情况下,依赖具体的实现而不是用接口抽象它是完全可以的。如果您真的需要抽象,请在使用它之前仔细考虑。
示例文件:
- repository.ports.ts - 存储库的通用端口
- user.repository.port.ts - 用户存储库的端口
- find-users.query-handler.ts - 注意查询处理程序如何依赖于端口而不是具体的存储库实现,并且注入了一个实现
- logger.port.ts - 应用程序记录器端口的另一个示例
领域层
该层包含应用程序的业务规则。
域应该使用通用语言描述的域对象进行操作。最重要的域构建块如下所述。
1、实体
实体是域的核心。它们封装了企业范围的业务规则和属性。实体可以是具有属性和方法的对象,也可以是一组数据结构和函数。
实体代表业务模型并表达特定模型具有哪些属性,它可以做什么,何时以及在什么条件下可以做到这一点。商业模式的一个例子可以是用户、产品、预订、票证、钱包等。
实体必须始终保护它们的不变量:
域实体应始终是有效实体。对于一个应该始终为真的对象,有一定数量的不变量。例如,订单项目对象始终必须具有必须为正整数的数量,加上商品名称和价格。因此,不变量的执行是域实体(尤其是聚合根)的责任,并且实体对象不应该能够在没有有效的情况下存在。
实体:
- 包含域业务逻辑。尽可能避免在您的服务中包含业务逻辑,这会导致贫血的领域模型(领域服务是不能放在单个实体中的业务逻辑的例外)。
- 有一个身份来定义它并使其与其他人区分开来。它的身份在其生命周期中是一致的。
- 两个实体之间的平等是通过比较它们的标识符(通常是它的id字段)来确定的。
- 可以包含其他对象,例如其他实体或值对象。
- 负责收集对状态的所有理解以及它在同一个地方如何变化。
- 负责协调对其拥有的对象的操作。
- 对上层(服务、控制器等)一无所知。
- 应该对域实体数据进行建模以适应业务逻辑,而不是某些数据库模式。
- 实体必须保护它们的不变量,尽量避免公共设置器 - 使用方法更新状态并在需要时对每次更新执行不变量验证(这可以是validate()检查更新是否违反业务规则的简单方法)。
- 必须在创作上保持一致。在创建时验证实体和其他域对象,并在第一次失败时抛出错误。快速失败。
- 避免无参数(空)构造函数,接受并验证构造函数(或工厂方法,如create())中的所有必需属性。
- 对于需要一些复杂设置的可选属性,可以使用Fluent 接口和Builder Pattern 。
- 使实体部分不可变。确定哪些属性在创建后不应更改并制作它们readonly(例如id或createdAt)。
注意:很多人倾向于为每个实体创建一个模块,但这种方法不是很好。每个模块可能有多个实体。要记住的一件事是,将实体放在单个模块中要求这些实体具有相关的业务逻辑,不要将不相关的实体组合在一个模块中。
示例文件:
2、聚合
聚合是可以被视为单个单元的域对象集群。它封装了概念上属于一起的实体和值对象。它还包含一组可以操作这些域对象的操作。
- 聚合通过在单个抽象下收集多个域对象来帮助简化域模型。
- 聚合不应受数据模型的影响。域对象之间的关联与数据库关系不同。
- 聚合根是一个实体,包含其他实体/值对象以及操作它们的所有逻辑。
- 聚合根具有全局标识(UUID / GUID / 主键)。聚合边界内的实体具有本地身份,仅在聚合内是唯一的。
- 聚合根是整个聚合的网关。来自聚合外部的任何引用都应该只转到聚合根。
- 对聚合的任何操作都必须是事务性操作。要么一切都被保存/更新/删除,要么什么都没有。
- 只能通过数据库查询直接获得聚合根。其他的一切都必须通过遍历来完成。
- 与 类似Entities,聚合必须在整个生命周期内保护它们的不变量。当提交对聚合边界内的任何对象的更改时,必须满足整个聚合的所有不变量。简单地说,聚合中的所有对象必须是一致的,这意味着如果聚合中的一个对象更改状态,则不应与该聚合中的其他域对象冲突(这称为一致性边界)。
- 聚合中的对象可以通过其全局唯一标识符 (id) 引用其他聚合根。避免持有直接的对象引用。
- 尽量避免聚合太大,这可能会导致性能和维护问题。
- 聚合可以发布Domain Events(更多内容见下文)。
所有这些规则都来自于围绕聚合创建边界的想法。边界简化了业务模型,因为它迫使我们非常仔细地考虑每一种关系,并在一组明确定义的规则内。
总而言之,如果你在一个根中组合多个相关实体和值对象Entity,这个根Entity就变成了一个Aggregate Root,而这组相关实体和值对象就变成了一个Aggregate。
示例文件:
- aggregate-root.base.ts - 抽象基类。
- user.entity.ts - 聚合只是必须遵循上述一组特定规则的实体。
3、领域事件
域事件表示域中发生了您希望同一域的其他部分(进程中)知道的事情。域事件只是推送到内存中域事件调度程序的消息。
例如,如果用户购买了东西,您可能想要:
- 更新他的购物车;
- 从他的钱包里取钱;
- 创建一个新的运输订单;
- 执行与执行“购买”命令的聚合无关的其他域操作。
典型的方法涉及在执行“购买”操作的服务中执行所有这些逻辑。但是,这会在不同子域之间产生耦合。
另一种方法是发布Domain Event. 如果执行与一个聚合实例相关的命令需要在一个或多个附加聚合上运行附加域规则,您可以设计和实现由域事件触发的那些副作用。可以通过订阅具体Domain Event并根据需要创建尽可能多的事件处理程序来执行在同一域模型中跨多个聚合的状态更改传播。这可以防止聚合之间的耦合。
域事件可能有助于创建审计日志,通过将每个事件保存到数据库来跟踪对重要实体的所有更改。阅读更多关于为什么审计日志可能有用的信息:为什么软删除是邪恶的以及该怎么做。
由单个进程中跨多个聚合的域事件引起的所有更改都可以保存在单个数据库事务中。这种方法可确保数据的一致性和完整性。将整个流程包装在事务中或使用工作单元等模式或类似模式可以对此有所帮助。 请记住,当多个用户尝试同时修改单个记录时,滥用事务可能会造成瓶颈。仅在您负担得起时才使用它,否则请使用其他方法(例如最终一致性)。
有多种方法可以为领域事件实现事件总线,例如使用来自Mediator或Observer等模式的想法。
例子:
- domain-events.ts - 此类负责为需要发出或收听事件的任何人提供发布/订阅功能。请记住,这只是一个概念验证示例,可能不是生产应用程序的最佳解决方案。
- user-created.domain-event.ts - 保存与已发布事件相关的数据的简单对象。
- create-wallet-when-user-is-created.domain-event-handler.ts - 这是域事件处理程序的一个示例,它在引发域事件时执行一些操作(在这种情况下,当创建用户时它也会创建该用户的钱包)。
- typeorm.repository.base.ts - 存储库在将更改持久化到聚合时发布所有域事件以供执行。
- typeorm-unit-of-work.ts - 这确保所有更改都保存在单个数据库事务中。
- unit-of-work.ts - 在这里您为事务中使用的特定域存储库创建工厂。
- create-user.service.ts - 这里我们从 a 获取一个用户存储库UnitOfWork并执行一个事务。
4、域错误
应用程序的核心层和域层不应该抛出 HTTP 异常或状态,因为它不应该知道它在什么上下文中使用,因为它可以被任何东西使用:HTTP 控制器、微服务事件处理程序、命令行接口等。更好的方法是使用适当的错误代码创建自定义错误类。
例外是针对特殊情况。复杂的域通常会有很多错误,这些错误并不例外,而是业务逻辑的一部分(例如“座位已预订,请选择另一个”)。这些错误可能需要特殊处理。在这些情况下,返回显式错误类型可能是比抛出更好的方法。
返回错误而不是显式抛出会显示方法可以返回的每个异常的类型,以便您可以相应地处理它。它可以使错误处理和跟踪更容易。
为了帮助解决这个问题,您可以使用某种带有 Success 或 Failure 的 Result 对象类型(来自 Haskell 等函数式语言的Either monad )。与抛出异常不同,这种方法允许为每个错误定义类型,并强制您显式处理这些情况,而不是使用try/catch. 例如:
if (await userRepo.exists(command.email)) { return Result.err(new UserAlreadyExistsError()); // <- returning an Error } // else const user = await this.userRepo.create(user); return Result.ok(user);
- oxide.ts - 如果你想使用 Result 对象,这是一个不错的 npm 包
- @badrap/result - 替代方案
返回错误而不是抛出它们会增加一些额外的样板代码,但可以使您的应用程序更加健壮和安全。
注意:区分域错误和异常。异常通常被抛出而不返回。如果您返回技术异常(如连接失败、进程内存不足等),可能会导致一些安全问题,并违反Fail-fast原则。返回异常不是终止程序流,而是继续执行程序并允许它在不正确的状态下运行,这可能会导致更多意外错误,因此在这些情况下通常最好抛出异常而不是返回异常。
示例文件:
- user.errors.ts - 用户错误
- create-user.service.ts - 注意如何Result.err(new UserAlreadyExistsError())返回而不是抛出它。
- create-user.http.controller.ts - 在用户 http 控制器中,我们打开一个错误并决定如何处理它。如果出现错误,UserAlreadyExistsError我们会抛出Conflict Exception一个用户将收到的409 - Conflict. 如果错误未知,我们只需将其抛出,NestJS 会将其作为500 - Internal Server Error.
- create-user.cli.controller.ts - 在 CLI 控制器中,我们不关心返回正确的状态代码,所以我们只是.unwrap()一个结果,它只会在错误的情况下抛出。
- exceptions文件夹包含一些通用应用程序异常(不是特定于域的)
- exception.interceptor.ts - 在这个文件中,我们将应用程序的通用异常转换为 NestJS HTTP 异常。这样,我们就不受框架或 HTTP 协议的束缚。
基础设施层
基础设施层负责封装技术。您可以在那里找到用于存储/检索业务实体的数据库存储库、用于发出消息/事件的消息代理、用于访问外部资源的 I/O 服务、与框架相关的代码以及代表架构可替换细节的任何其他代码的实现。
它是最不稳定的层。由于这一层中的事物很可能发生变化,因此它们尽可能远离更稳定的域层。因为它们是分开的,所以进行更改或将一个组件换成另一个组件相对容易。
基础设施层可以包含Adapters数据库相关文件Repositories,如ORM entities/ Schemas、框架相关文件等。
1、适配器
- 基础设施适配器(也称为驱动/辅助适配器)使软件系统能够通过在请求时接收、存储和提供数据(如持久性、消息代理、发送电子邮件或消息、请求第 3 方 API 等)与外部系统进行交互。
- 适配器也可用于与单个进程内的不同域进行交互,以避免这些域之间的耦合。
- 适配器本质上是端口的实现。它们不应该在代码中的任何位置直接调用,只能通过端口(接口)调用。
- 适配器可用作遗留代码的防损坏层 (ACL)。
阅读有关 ACL 的更多信息:反腐败层:如何防止遗留支持破坏新系统
适配器应具有:
- 它实现的应用程序/域层中的port某个地方;
- 将数据从域映射到域的映射器(如果需要);
- 接收数据的 DTO/接口;
- 一个验证器,以确保传入的数据没有损坏(验证可以使用装饰器驻留在 DTO 类中,或者可以通过 验证Value Objects)。
2、存储库
存储库是对存在于数据库中的实体集合的抽象。它们集中了通用数据访问功能并封装了访问该数据所需的逻辑。实体/聚合可以放入存储库,然后在以后检索,即使不知道数据保存在哪里:在数据库中、文件中或其他来源。
我们使用存储库将用于访问数据库的基础设施或技术与域模型层分离。
Martin Fowler 对存储库的描述如下:
存储库执行域模型层和数据映射之间的中介任务,其作用类似于内存中的一组域对象。客户端对象以声明方式构建查询并将它们发送到存储库以获取答案。从概念上讲,存储库封装了存储在数据库中的一组对象以及可以对它们执行的操作,提供了一种更接近持久层的方式。存储库还支持在一个方向上清晰地分离工作域与数据分配或映射之间的依赖关系的目的。
这里的数据流看起来像这样:存储库Entity从应用程序服务接收域,将其映射到数据库模式/ORM 格式,执行所需的操作(保存/更新/检索等),然后将其映射回域Entity格式并返回给服务。
应用程序的核心通常不允许直接依赖于存储库,而是依赖于抽象(端口/接口)。这使得数据检索技术与技术无关。
3、持久性模型
将单个实体用于域逻辑和数据库关注点会导致以数据库为中心的架构。在 DDD 世界中,域模型和持久性模型应该分开。
由于域Entities对其数据进行了建模,以便最好地适应域逻辑,因此它可能不是保存在数据库中的最佳状态。为此目的Persistence models,可以创建具有在所使用的特定数据库中更好地表示的形状。领域层不应该对持久性模型一无所知,也不应该关心。
可以有多个模型针对不同目的进行优化,例如:
- 域具有自己的模型-Entities和.AggregatesValue Objects
- 具有自己的模型的持久层 - ORM(对象-关系映射)、模式、读/写模型(如果数据库被分成读写数据库(CQRS)等)。
随着时间的推移,当数据量增加时,可能需要对数据库进行一些更改,例如通过重新设计某些表甚至完全更改数据库来提高性能或数据完整性。如果没有明确区分模型Domain和Persistance模型,对数据库的任何更改都将导致您的域Entities或Aggregates. 例如,在执行数据库规范化时,数据可以分布在多个表中,而不是在一个表中,反之亦然。这可能会迫使团队对域层进行完整的重构,这可能会导致意外的错误和挑战。分离域和持久性模型可以防止这种情况。
注意:对于较小的应用程序来说,分离域模型和持久性模型可能是多余的。创建和维护样板代码(如映射器和抽象)需要付出很多努力。在做出此决定之前,请考虑所有利弊。
示例文件:
- user.orm-entity.ts <- 使用 ORM 的持久性模型。
- user.orm-mapper.ts <- 持久性模型还应该有一个相应的映射器来从域映射到持久性并返回。
更详细点击标题见Github项目