Cloudflare 自 2014 年以来一直在生产中使用 Kafka。从那时起,我们已经取得了长足的进步,目前跨多个数据中心运行 14 个不同的 Kafka 集群,大约有 330 个节点。在他们之间,在过去八年中处理了超过一万亿条消息。
Cloudflare 使用 Kafka 解耦微服务,并以容错的方式通过通用数据格式传达各种资源的创建、更改或删除。这种解耦是使 Cloudflare 工程团队能够同时处理多个功能和产品的众多因素之一。
我们在处理 1 万亿条消息的过程中学到了很多关于 Kafka 的知识,并构建了一些有趣的内部工具来简化采用,这些工具将在这篇博文中进行探讨。
Messagebus
我们的 Kafka 集群之一被创造性地命名为 Messagebus。它是我们运行的最通用的集群,其创建目的是:
- 防止数据孤岛;
- 使服务能够以基本为零的集成成本进行更清晰的通信(更多关于我们如何实现这一点的内容见下文);
- 鼓励使用自我记录的通信格式,从而消除文档过时的问题。
为了使其尽可能易于使用并鼓励采用,应用程序服务团队创建了两个内部项目。第一个是难以想象的命名 Messagebus-Client。Messagebus-Client 是一个 Go 库,它使用一组自以为是的配置选项和管理 mTLS 证书轮换的能力包装了出色的Shopify Sarama库。
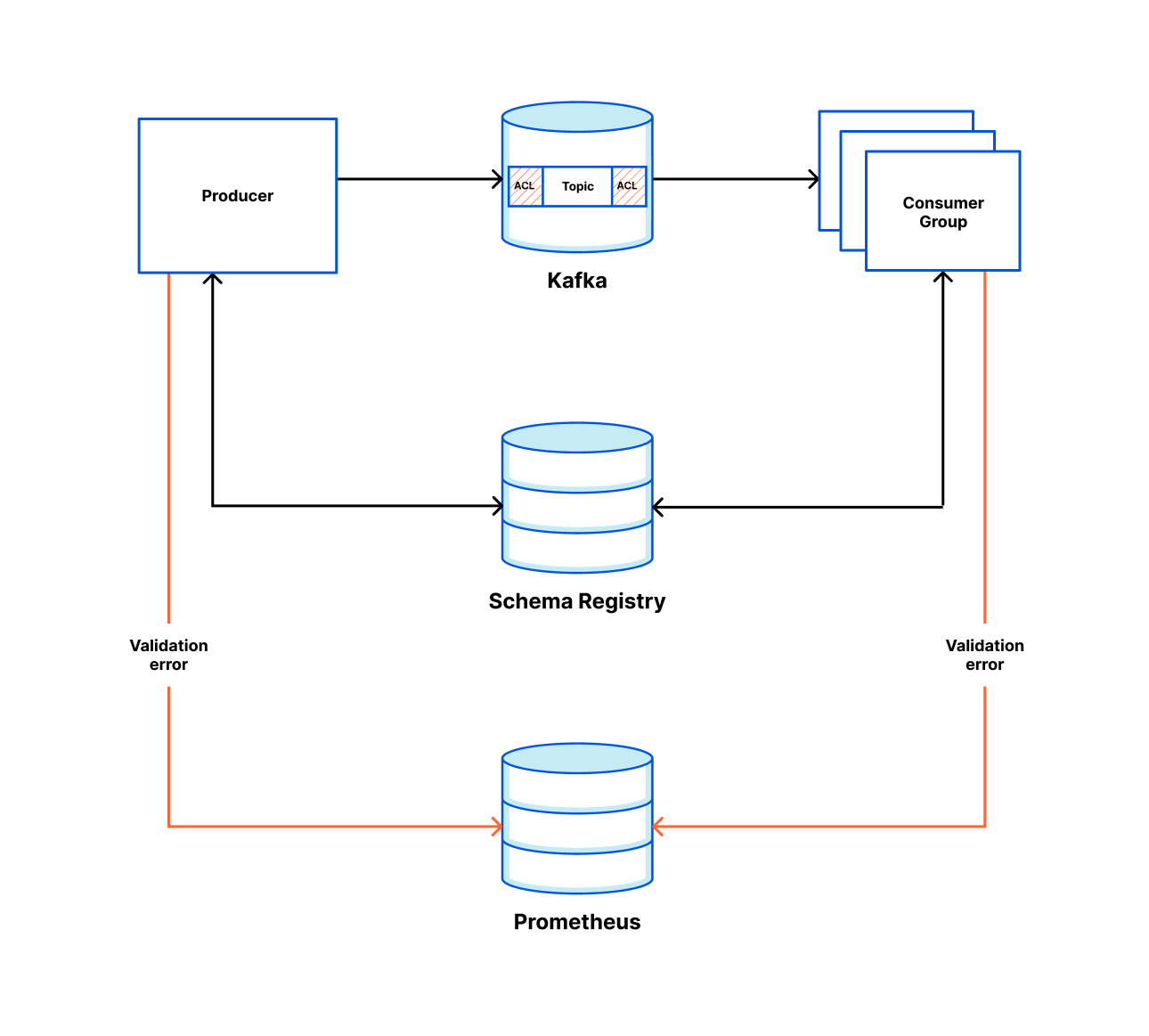
这个项目的成功在某种程度上也是它的失败。通过提供一个现成的 Kafka 客户端,我们确保了团队快速启动和运行,但我们也将 Kafka 的一些核心概念抽象得太多了,这意味着小的不起眼的配置更改可能会产生很大的影响。
一个这样的例子导致了分区倾斜(大部分消息被定向到单个分区,这意味着我们没有实时处理消息;见下图)。Kafka 的一个缺点是每个分区只能有一个使用者,因此您不能轻易地扩展自己的方式来提高吞吐量。
这也意味着在您的服务投入生产之前,明智的做法是在餐巾纸上进行一些数学运算,以弄清楚吞吐量可能是什么样子,否则您以后需要添加分区。
连接器
连接器框架基于 Kafka 连接器,允许我们的工程师轻松启动一个服务,该服务可以从记录系统中读取并将其推送到其他地方(例如 Kafka,甚至是 Cloudflare 自己的Quicksilver)。为了使这尽可能简单,我们使用 Cookiecutter 模板来允许工程师在 CLI 中输入一些参数,然后接收准备好部署的服务。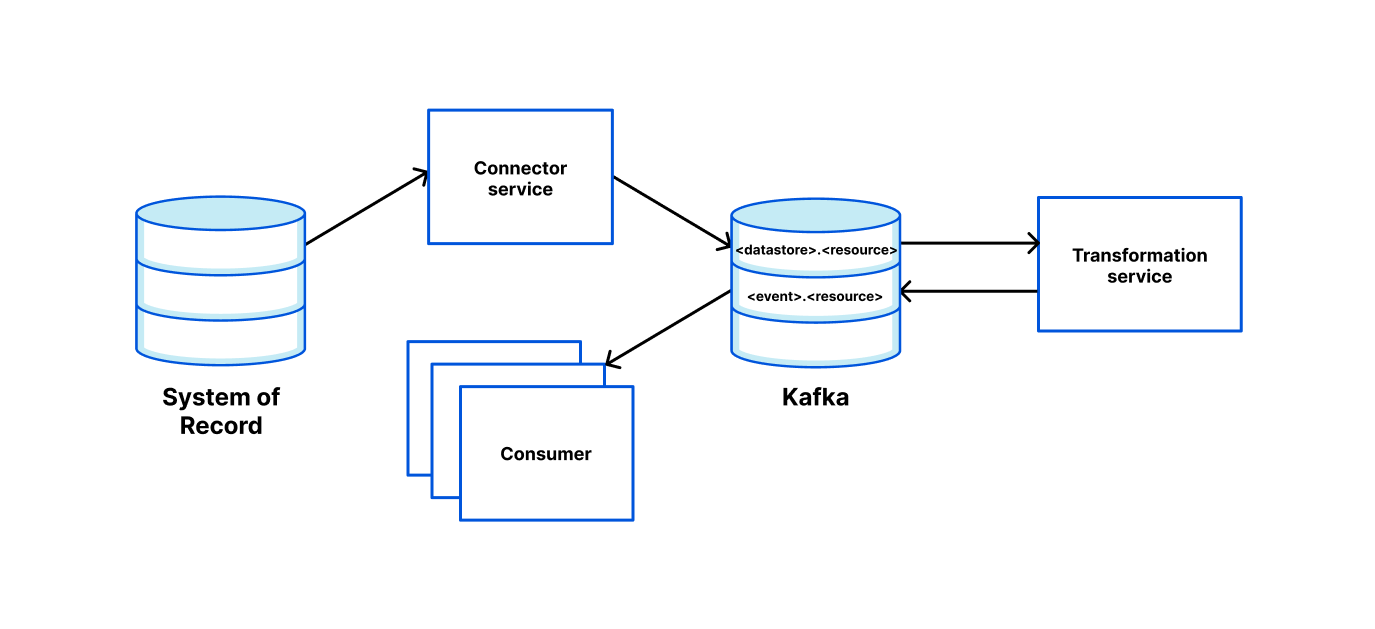
我们提供通过环境变量配置数据管道的能力。对于简单的用例,我们提供开箱即用的功能。然而,扩展读取器、写入器和转换就像满足接口并“注册”新条目一样简单。
例如,添加环境变量:
READER=kafka |
将要:
- 从 Kafka 主题“topic1”和“topic2”读取消息;
- 使用名为“pf_edge”的转换函数转换消息,该函数将请求从 Kafka protobuf 映射到 Quicksilver 请求;
- 将结果写入 Quicksilver。
连接器很容易带有基本指标和警报,因此团队知道他们可以快速但充满信心地投入生产。
下面是一个团队如何使用我们的连接器框架从 Messagebus 集群中读取并写入到各种其他系统的图表。这是由应用程序服务团队运行的称为通信偏好服务 (CPS) 的系统协调的。每当用户选择加入/退出营销电子邮件或更改其在 cloudflare.com 上的语言偏好时,他们都会调用 CPS,以确保这些设置反映在所有相关系统中。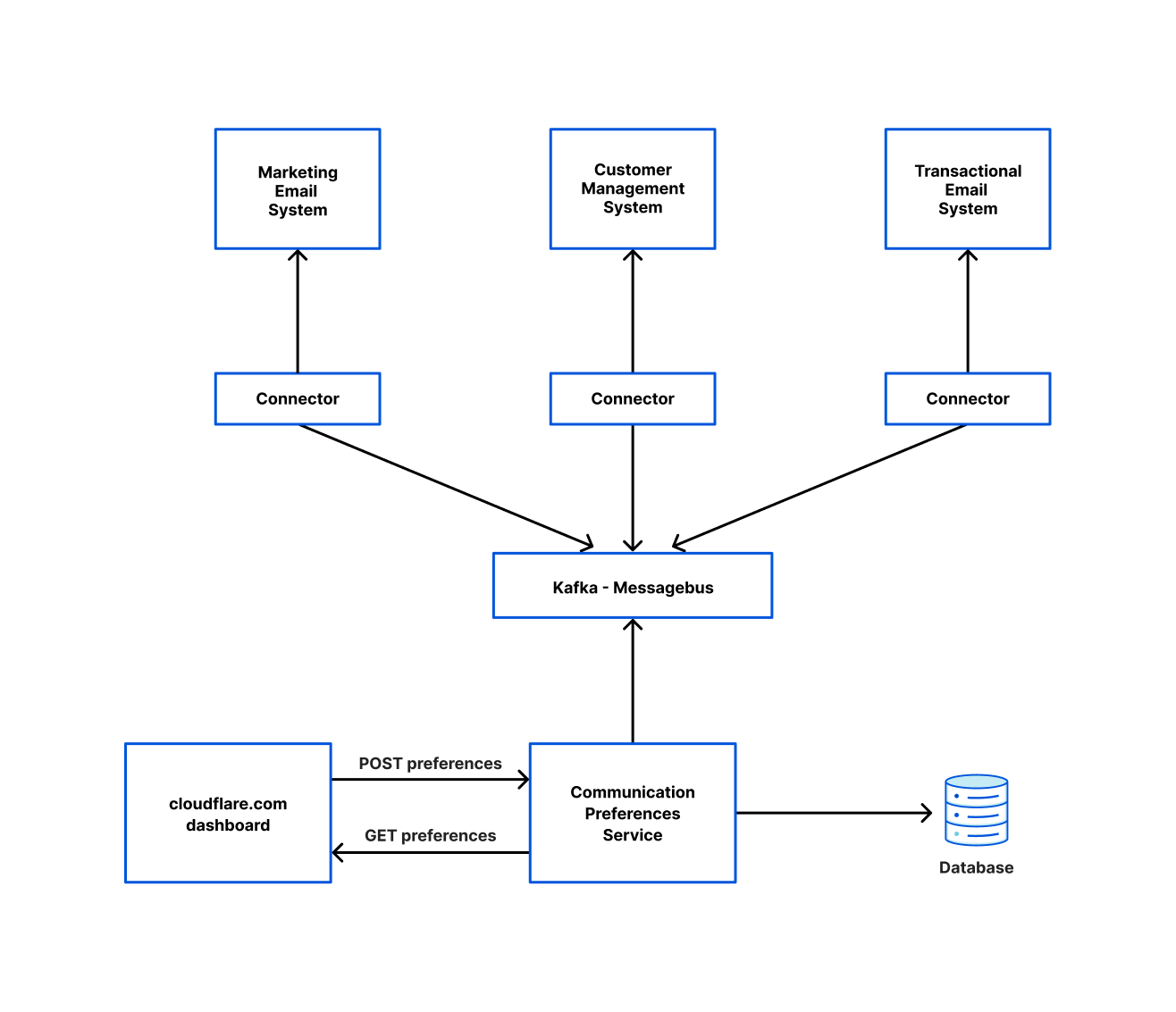
严格的Schema模式
除了 Messagebus-Client 库,我们还提供了一个名为 Messagebus Schema 的存储库。这是将通过我们的 Messagebus 集群发送的所有消息类型的模式注册表。对于消息格式,我们使用 protobuf 并且对这个决定非常满意。以前,我们的团队在我们的一些 kafka 模式中使用了 JSON,但我们发现执行向前和向后兼容性要困难得多,而且消息大小比 protobuf 等效项要大得多。Protobuf 提供了严格的消息模式(包括类型安全)、我们期望的向前和向后兼容性、以多种语言生成代码的能力以及非常易于人类阅读的文件。
我们鼓励在批准合并之前发表大量评论。合并后,我们使用 prototool 进行重大更改检测,强制执行一些风格规则并为各种语言生成代码(在编写时它只是 Go 和 Rust,但添加更多是微不足道的)。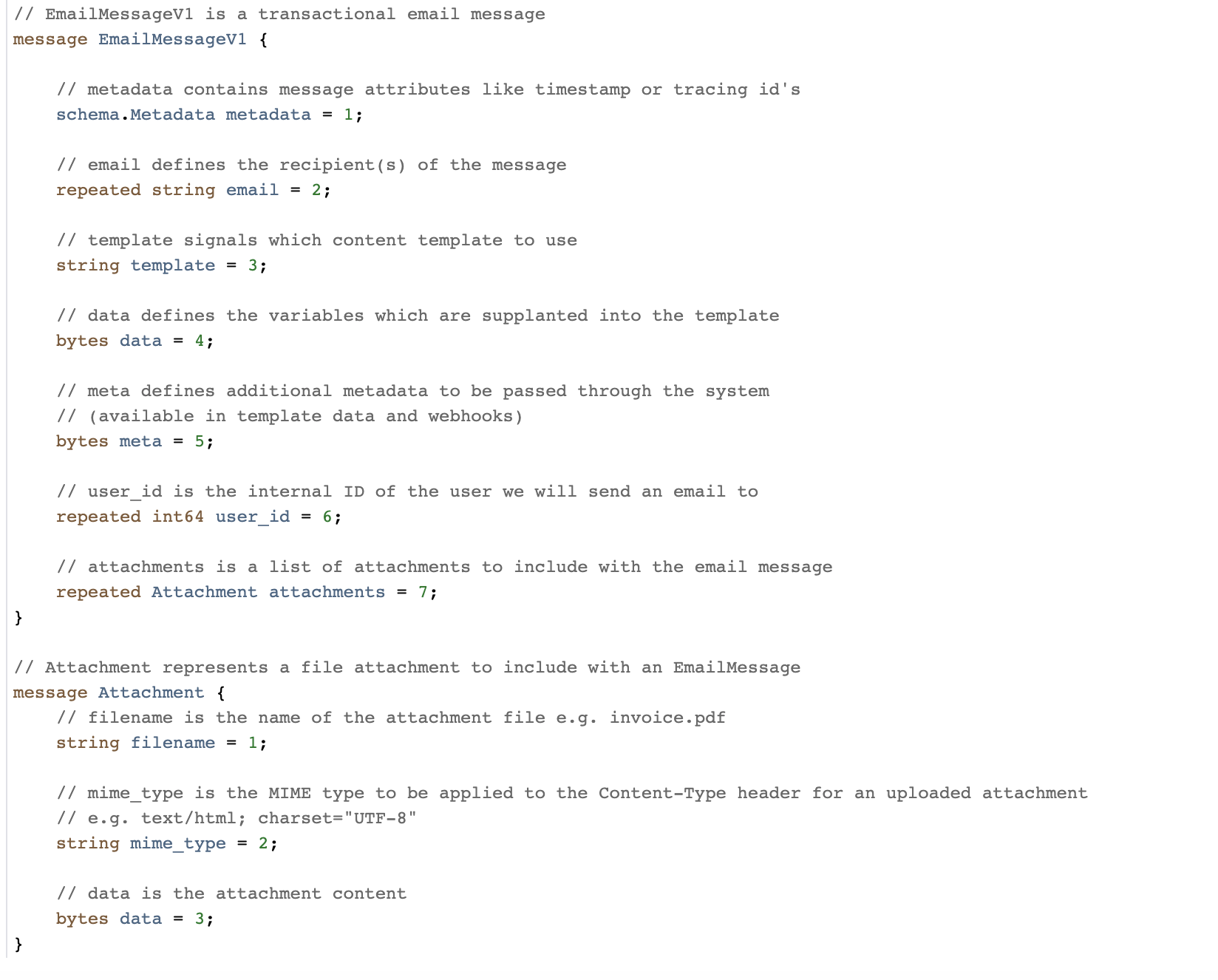
上图我们模式中的示例 Protobuf 消息
此外,在 Messagebus Schema 中,我们将原始消息的映射存储到团队,以及该团队的聊天室在我们的内部通信工具中。这使我们能够在必要时轻松地将问题上报给正确的团队。
我们为 Messagebus 集群做出的一项重要决定是每个主题只允许一条原始消息。这在 Messagebus Schema 中配置并由 Messagebus-Client 强制执行。这是一个易于采用的好决定,但它导致了许多主题的存在。当您考虑到对于我们创建的每个主题,我们添加大量分区并以至少 3 的复制因子复制它们以实现弹性时,有很大的潜力可以为我们的低吞吐量主题优化计算。
可观察性
让团队轻松观察 Kafka 对于我们的解耦工程模型取得成功至关重要。因此,我们尽可能地创建自动化指标和警报,以确保所有工程团队都能获得丰富的信息,以便及时响应出现的任何问题。
我们使用 Salt 来管理我们的基础架构配置并遵循 Gitops 样式模型,其中我们的 repo 保存了我们基础架构状态的真实来源。为了添加一个新的 Kafka 主题,我们的工程师向这个 repo 提出了一个拉取请求,并添加了几行 YAML。合并后,将创建主题和高延迟警报(其中延迟定义为读取的最后一个提交的偏移量与生成的最后一个产生的偏移量之间的时间差)。可以(并且应该)创建其他警报,但这由应用程序团队自行决定。我们自动为高延迟生成警报的原因是,这个简单的警报是捕捉大量问题的绝佳代理,包括:
- 您的消费者没有运行。
- 您的消费者无法跟上吞吐量,或者此时正在为您的主题生成异常数量的消息。
- 您的消费者行为不端并且不确认消息。
对于指标,我们使用 Prometheus 并使用 Grafana 显示它们。对于创建的每个新主题,我们会自动提供生产者/消费者的生产率、消费率和分区偏差视图。如果调用了工程团队,则警报消息中会包含指向此 Grafana 视图的链接。
在我们的 Messagebus-Client 中,我们自动公开了一些指标,用户可以进一步扩展它们。我们默认公开的指标是:
对于生产者:
- 消息已成功传递。
- 消息传递失败。
对于消费者:
- 消息成功消费。
- 消息消费错误。
一些团队使用它们来警告吞吐量的重大变化,其他团队使用它们来提醒在给定时间范围内是否没有生成/消费消息。