重试非常重要,尤其是在微服务系统中,这些服务必须经常协作才能处理请求。如果一个服务只中断了几秒钟会发生什么?其他服务应该在放弃之前向客户抛出错误或重试多次。
举个简单的例子:通过http链式调用的服务:
链中调用的服务
如果服务 C 关闭,那么一个简单的方法是服务 B 向服务 A 抛出错误,服务 A 向客户返回错误。
但是如果服务 C 在几秒钟内关闭,那么更好的方法是服务 B 在 2 秒、4 秒、8 秒内重试……如果幸运的话,第三次重试将是成功的,最终对客户的结果仍然是成功的:
重试请求
所以我们可以在一个简单的例子中立即看到重试的好处。但是对于事件驱动的架构,服务 B 从消息队列接收事件作为 Kafka,然后重试策略具有更多的复杂性。在本文中,我们将了解原因并找到解决方法。
问题
简要概述一下,Altitude 是一个运行在大型微服务系统上的酒店数字平台。其中一项功能是自动钥匙管理:当预订登记时,将创建 RFID 卡和移动钥匙,当预订更改房间或更新出发日期时,所有钥匙也将被更新。全部自动运行。
我们使用 Kafka 作为流处理器,这基本上意味着 Kafka 连接源监听预订数据库中的更改,发布到 Kafka 主题,我们的服务将使用这些事件。如果您关心 Kafka 系统设计的细节,那么您可以再次阅读上一篇文章。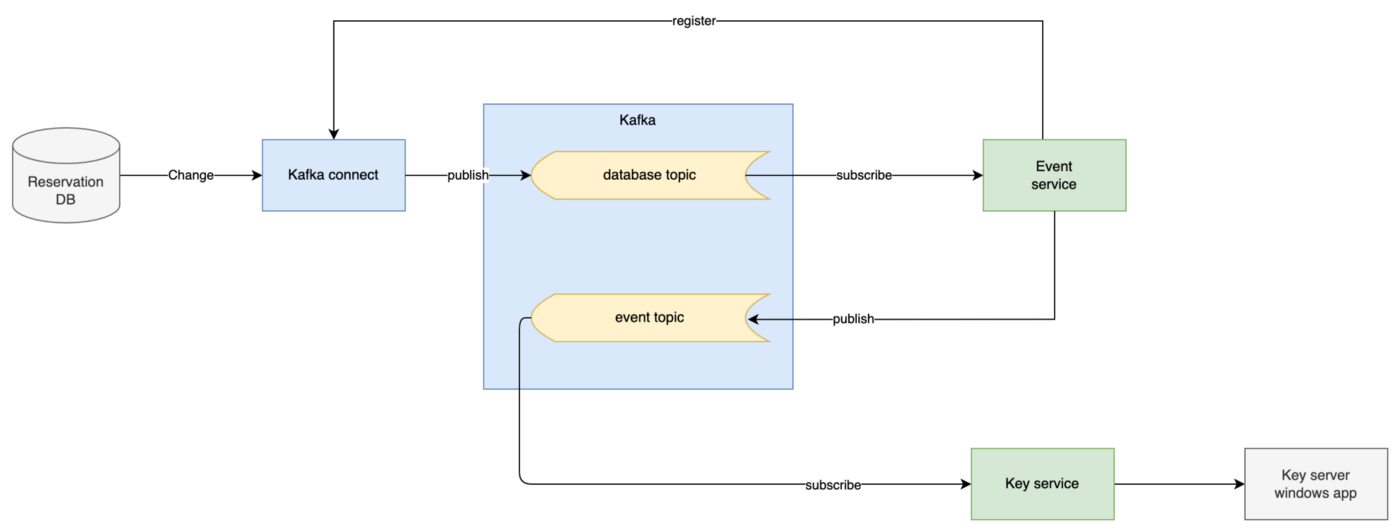
使用 Kafka 的系统架构
出于本文的目的,此架构已被简化。请专注于关键服务,它负责消费来自 Kafka 的预订登记、预订退房、预订更新,对作为 Windows 应用程序在我们客户的 PC 上运行的密钥服务器执行一些逻辑和请求或云。
我们管理关键服务,关键服务器 windows 应用程序由占据我们大部分关注的客户管理。它在单个实例上运行,具体取决于客户,因此它可能会因网络问题、Windows 崩溃等而仅停机几秒钟。尤其是在自动化环境中,在他们检查日志之前没有人看到错误返回。所以使用重试策略很重要。
简单重试
假设我们将实施一个退避策略,该策略以以下间隔重试:2s、4s、8s、16s。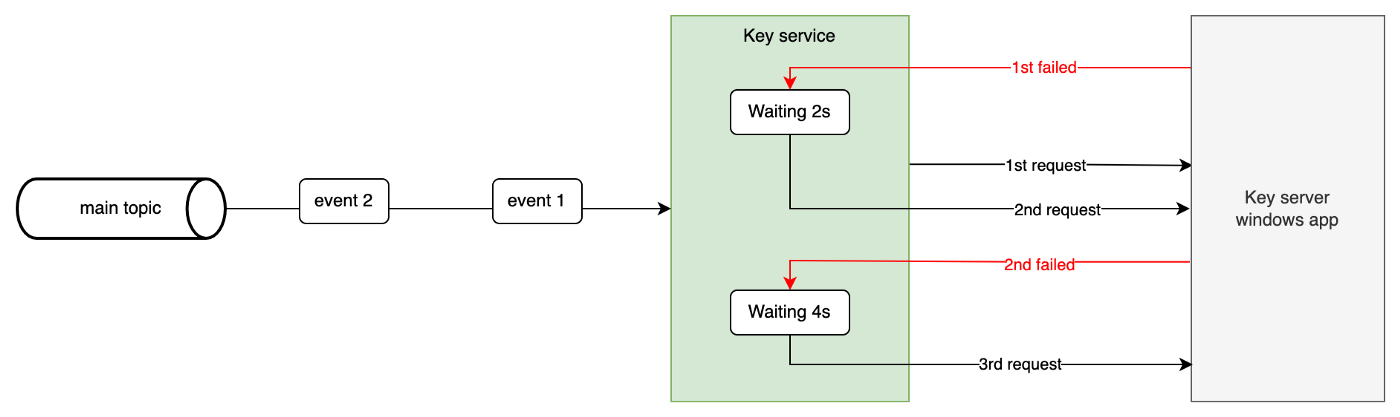
消费者客户端中的循环重试
我们可以想到的第一种方式是在消费者处循环重试:当请求 fto 密钥服务器失败时,它将等待接下来的 2 秒,然后再发送第二个请求,如果请求仍然失败,那么它将等待 4 秒,然后再发送下一个请求等。
看起来又快又简单?但是这种方法存在一个问题:因为 Kafka 执行顺序事件处理,所以如果事件 1 正在重试,那么事件 2 仍在队列中。在最坏的情况下,事件 2 必须等待 16 秒才能处理完毕。而且大多数时候等待是没有意义的。
非阻塞重试
很明显,我们应该在事件 1 重试时处理事件 2。所以更好的方法是将事件 1 放到不同的主题中并继续处理事件 2。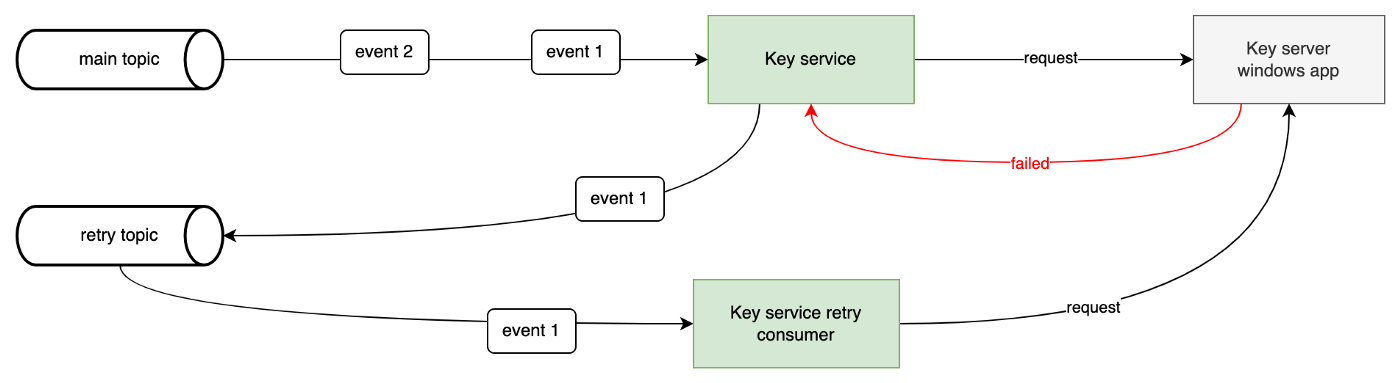
一个主题重试
当密钥服务处理事件 1 并失败时,它会将事件 1 放入重试主题并继续处理事件 2。重试主题将被另一个处理事件 1 并模仿逻辑作为密钥服务发送到密钥服务器的消费者使用.
如果我们只重试一次,那么保留一个重试主题就可以了。但是我们正在做一个退避策略,以以下间隔重试:2s、4s、8s……所以如果一个事件的第一次重试失败,那么这个事件的下一次重试必须在重试消费者中实现,这个循环会阻塞其他事件重试主题(与第一种方法相同的弱点)。
所以我们应该创建更多的重试主题,每个主题对应一个间隔时间: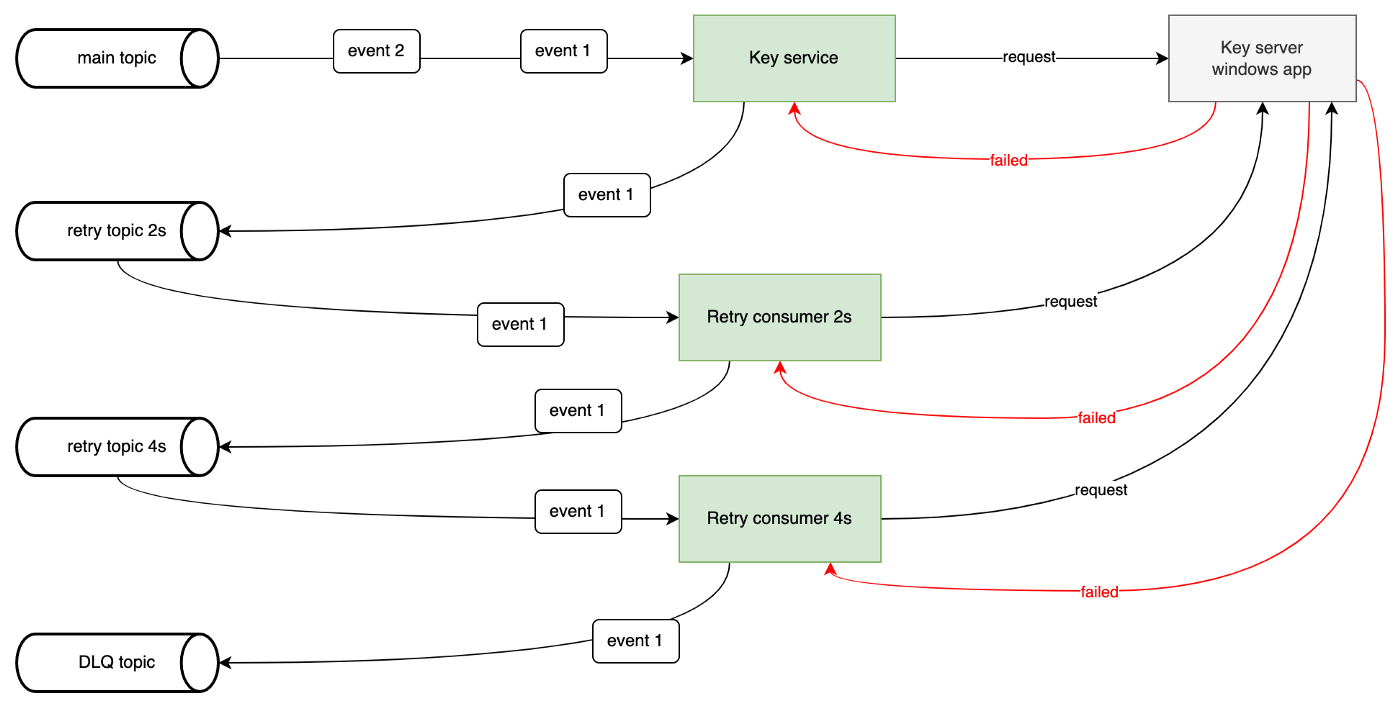
多个重试主题
如果第一次重试消费者的第一次尝试失败,它会将事件发送到下一个重试主题并继续处理其他重试事件。
当所有重试失败时,最后一个重试消费者会将事件发送到死信队列主题,以便在需要时手动查看或重新处理。
维护重试事件的顺序
同一预订中的事件顺序很重要。回到我们的要求,预订将包含更多应按顺序运行的事件:入住、更新出发日期、退房。如果重试时不能保持这个顺序,那么我们就有麻烦了,让我们看看为什么:
预订会生成两个 2 事件:事件 1 用于登记入住,事件 2 用于更新出发日期。当事件 1 到达关键服务消费者并处理失败时,关键服务将其发送到重试主题 2s。然后关键服务消费者继续处理更新出发日期的事件 2。但预订尚未签入,因此密钥服务将拒绝事件 2。
因此,如果事件在同一个保留中,那么当事件 1 重试时,事件 2 也应该默认设置为重试流程。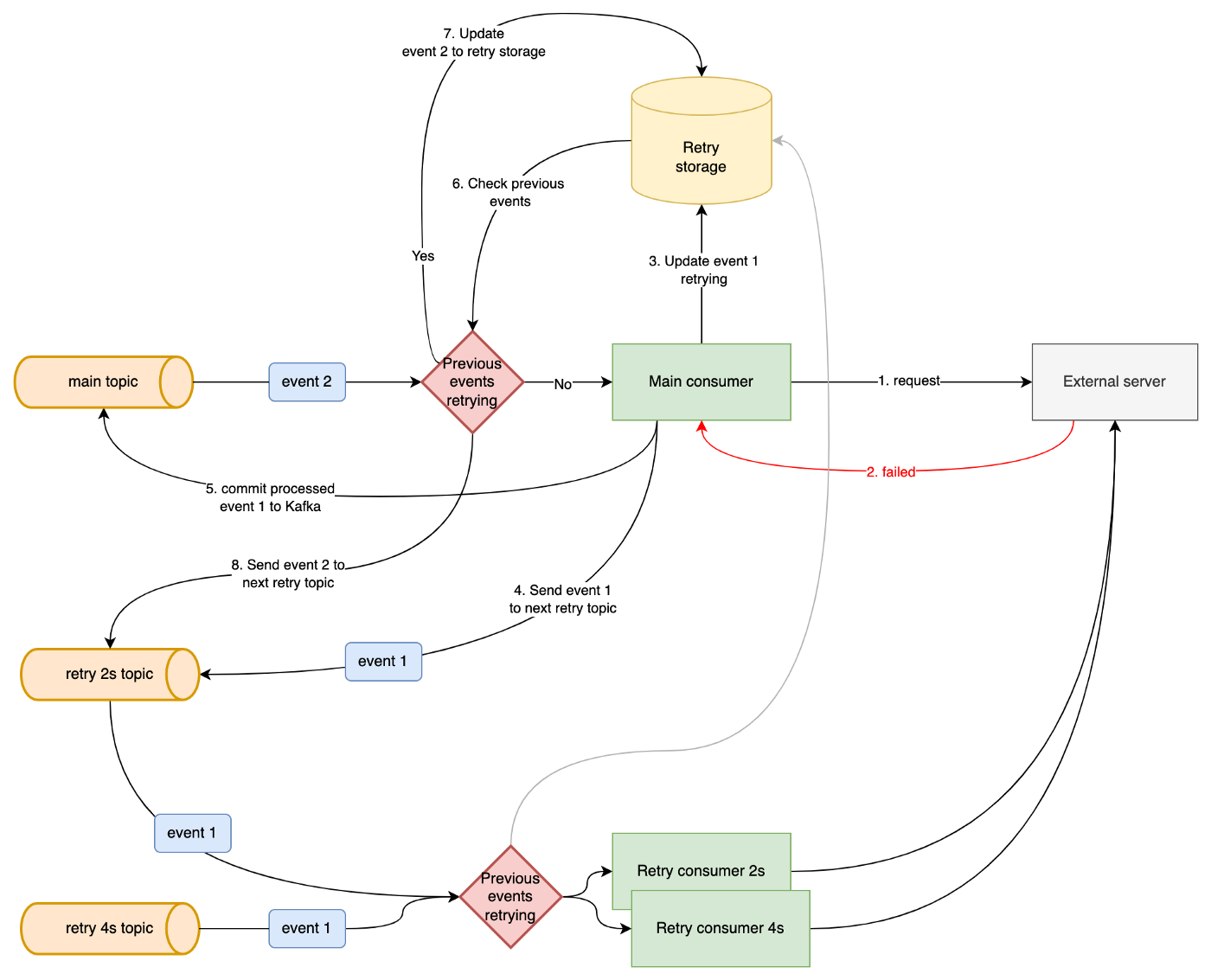
维护重试事件的顺序
我们可以使用存储来保持所有重试事件的状态。如果预留 A 中的事件处于重试流程中,则预留 A 中的所有其他事件将立即重试主题,而无需在消费者中处理。此流程包括以下步骤:
- 主要消费者(关键服务)向服务器发送请求。
- 请求因超时、内部服务器错误……而失败,需要重试。
- 主要消费者标记事件 1 正在存储中重试。
- 主消费者将事件 1 发送到主题 retry_2s。
- Kafka 的主要消费者提交是事件 1 已处理。
- Kafka 将主主题中的事件 2 发送给主消费者。主要消费者检查事件 1 是否相同的保留和重试。
- 主要消费者标记事件 2 在存储中重试并将事件 2 发送到主题 retry_2s。
- 主消费者将事件 2 发送到主题 retry_2s。
在每个重试消费者处,我们模拟检查之前的重试事件作为主要消费者:如果事件 2 即将重试消费者 2s 并且事件 1 在重试主题 4s 中,那么即使 2 也不会在消费者处处理并继续移动到重试主题 4s .
那么如果事件 1 处理成功会发生什么,它将从重试存储中删除,以便消费者可以处理事件 2。
如果事件 1 被处理,事件 2 仍在重试流程中,事件 3 到达主消费者,它与 1 和 2 相同的预留。主消费者将检查事件 2 是否存在于重试存储中,并将事件 3 移动到重试流程。
当然,如果事件 3 不是同一个预订,那么它将照常处理。
大多数情况下,消费者会从重试存储中读取,只是在出现故障时写入。所以它的读重比写重。我们可以使用 Redis 来提高速度。
执行
这个流程很复杂,我们希望通过编写一次并将其作为库发布来隐藏这种复杂性。我构建了一个 npm 包并在我的公司内使用它。不幸的是,根据我们的政策,我不能公开,但我将在本文中用一些伪代码来讨论它。
在开始之前,如果我们能看看这个库是如何使用的,那就更好了:
我使用KafkaJS来处理 Kafka,让我们看看这个库的输入:
- kafkaConfig要连接的 Kafka 配置。基本上,它是代理地址和客户端 ID。
- consumerConfig Kafka 消费者配置。它将用于所有主要消费者,重试消费者......
- retryDelays以毫秒为单位重试的间隔时间。与上面的脚本一样,我们将在 3 分钟、5 分钟、7 分钟后重试。对应这个时间,我们将创建一个重试主题,其命名是由主主题名称和重试间隔时间组合创建的。originTopic-retry-18000
- getGroupId从事件中提取组 ID。所有具有相同 groupId 的事件都将保留订单。例如,预订的所有事件check-in、check-out、update-departure-date将具有 groupId 是 reservationId。所以有重试的时候可以按顺序处理。
- consumeMessageCallback当事件被主消费者或重试消费者消费时调用回调。把你的代码放在这里来处理一个事件。要触发事件的重试流程,您必须在此函数中引发异常。我们不应该抛出所有异常。例如,http 状态码 400 不应该重试,但超时重试应该是
try { |
- movedToDLQCallback当事件被重试一次但失败时回调,因此必须将其移动到 DQL 主题。这是一个可选的。您可以在此处放置代码以发送电子邮件、通知(如果需要),但不要编写事件来重试存储,因为它应该在存储库中实现
- repository用于重试存储。这是一个界面,您可以在其中标记事件正在重试存储。您可以将此接口实现到任何类型的存储,例如 Mongodb、Redis……
export interface Repository { |
复杂流程看起来很简单,对吗?我们将详细了解内部运行的内容。
当我们使用上述配置初始化KafkaReprocessing对象时,它将创建:
- 一个 Kafka 主消费者和三个 Kafka 重试消费者,每个间隔时间 3 分钟、5 分钟、7 分钟
- 一位 Kafka 生产者向消费者发布事件
当主要消费者处理消息并失败时,它将附加 4 个标头到消息:
- x-altitude-retry-message-id消息的 id 用于存储库,对于每条消息都是唯一的。
- x-altitude-retry-attempts重试次数,随着每次尝试失败而增加。
- x-altitude-retry-timestamp-ms重试事件的纪元时间,当重试消费者消费一个事件时,它将检查此标头并等待重试时间。
当主消费者进程事件失败时,它会将这些标头添加到 Kafka 消息并发布到第一次重试主题。第一次重试消费者将检查 headerx-altitude-retry-timestamp-ms并等到此时重试并将 headerx-altitude-retry-attempts增加到 1。
如果重试消费者检查标头x-altitude-retry-attempts达到最大尝试次数,那么它将向 DLQ 主题发布消息。
这是全流程处理事件的伪代码:
const headers = message.headers; |
结论
使用更多重试主题和死信队列主题使我们能够在不阻塞主要消费者的情况下重试请求。开发人员将轻松监控 DLQ 中一直失败的事件并手动删除或重新处理它。
这种方法的一个缺点是,如果我们想多次重试,它会创建多个主题。所以我们应该限制重试的次数。
另一个需要考虑的问题是在需要时中断事件的重试流程。我们可以删除 Kafka 的重试主题(墓碑)中的记录。