在自 2016 年以来,我们在 Mirakl 开始使用 Kafka 作为消息服务,以支持我们在微服务环境中的异步驱动架构。
起初,Kafka 仅用于非关键服务,如电子邮件、审计或日志记录。这是一种安全的方法,因为我们对这项技术还没有完全的信心,尤其是我们对关系数据库的交易方面,这是处理支付等更关键的服务时必须具备的。
本文将介绍 Kafka 中的消息传递语义、它们在发生故障时的限制,以及我们如何在 Mirakl 使用发件箱模式克服这一限制。
Kafka 中的消息传递
您可能已经知道 Kafka 支持三种消息语义:
1、至少一次
生产者向代理发送消息并期望得到确认以确保消息已成功添加到主题中。如果由于网络延迟或任何其他原因没有收到确认,则生产者会重试发送消息,假设它尚未添加到主题中。
这可能导致重复消息,考虑到所有消费者都必须是幂等的,这不一定是一个问题。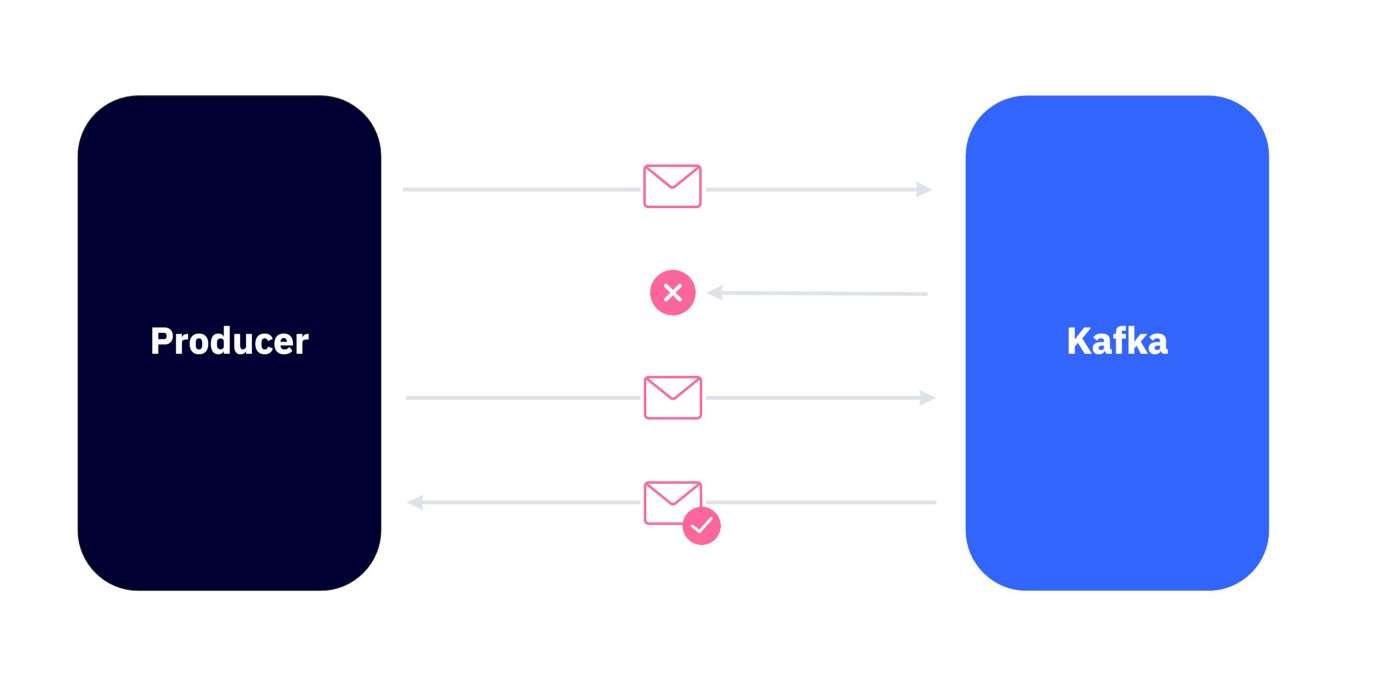
2、最多一次
这也被称为“尽力而为”策略。生产者在不等待确认的情况下向代理发送消息,如果代理无法访问或由于某种原因导致消息丢失(这种情况很少发生),生产者将不会尝试重新发送消息。换句话说,消息被传递一次(最好的情况)或根本不传递。
当我们对进度而不是结果更感兴趣时,或者在某些罕见的情况下,当不发送消息比发送两次消息(物联网传感器、跟踪……)更多或同样可以容忍时,这很有用。
3、恰好一次
每条消息都精确传递一次,它为流处理应用程序等读取-处理-写入任务提供端到端的精确一次保证。为了支持这种保证,Kafka 依赖于两个特性:
- 幂等传递:允许生产者只发送一次消息(属于同一生产者的重复消息被代理忽略)
- 事务交付:允许生产者以原子方式将数据发送到多个分区,这意味着要么所有事件都成功交付,要么没有一个。

您应该注意,此语义仅在 Kafka Streams 内部处理范围内得到保证,其中包括使用事件、更新状态存储和生成事件。尝试更新 Kafka 外部的状态,例如更新数据库中的行或进行 API 调用,将导致较弱的保证。
您可以在此处找到有关完全一次语义的更多详细信息。
使用现有解决方案时的限制
所有现有的语义在某些情况下可能有用,但在处理关键用例(如支付)时并不理想。
例如,考虑一个管理采购订单的“订单服务”微服务和另一个管理卖方余额和付款的“支付服务”微服务。当客户从卖家那里购买书籍时,我们需要在幕后执行以下操作:
- order-service : 在数据库中创建一个订单
- order-service:向 Kafka 发送事件以更新卖家的余额
- payment-service : 消费事件并更新卖家余额
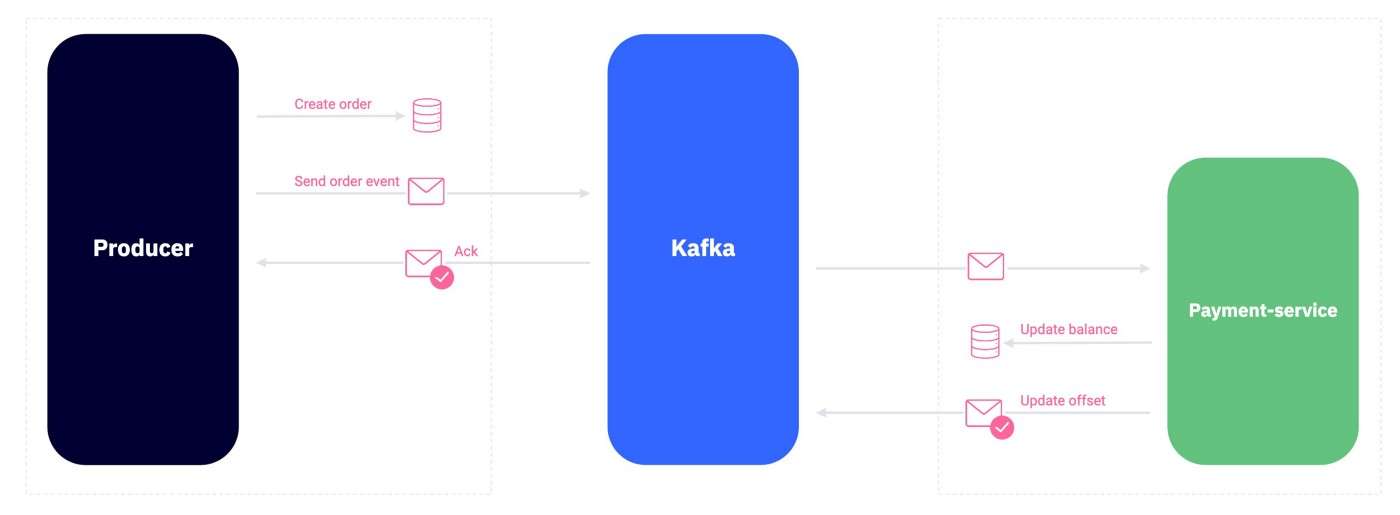
挑战在于前两个请求,在数据库中插入订单并向 Kafka 发送事件。如果两个调用中的任何一个失败,我们需要回滚所有内容,因此要么成功执行所有内容,要么什么都不执行。
让我们看看当我们使用上面提到的语义时会发生什么:
至少一次
使用这种策略有两个缺点:
- 数据重复:如果第一条消息的确认丢失, order-service可能会向 Kafka 发送两条消息,这几乎不是问题,因为它可以通过使用幂等消费者来解决。
- 数据不一致:即使数据库事务回滚,order-service也可能会发送 Kafka 消息来更新卖家的余额。或者反过来(如果您使用的是提交后策略),订单服务可能会在发送 Kafka 事件之前提交数据库事务并崩溃。
最多一次
这是我们要使用的最后一个语义,因为我们不能丢失消息。考虑以下场景:
- order-service : 创建一个订单
- order-service : 发送一个事件来更新seller1的余额而不等待确认
- Kafka:由于网络错误导致消息丢失
- payment-service : 不会更新seller1的余额
您可以猜到这对我们的卖家来说不是一个幸福的结局。
恰好一次
正如我上面提到的,只有当您尝试更新的数据位于 Kafka 中时,此策略才有效。这不是我们的情况,因为我们也与数据库进行通信。
我们如何在 Mirakl 解决这个问题
尝试一次更新两个系统在设计和实现方面都极具挑战性,尤其是对于我们知道 Kafka 不支持分布式事务的案例。在 Mirakl,我们决定一次只更新一个系统,首先我们更新数据库,然后使用异步过程将这些更新从数据库驱动到 Kafka。
这就是通常所说的发件箱模式。它可以被描述为一种帮助服务写入自己的本地数据库并以安全一致的方式与其他微服务交换数据的方式。
实现发件箱模式
如果我们回到我们的图书购买示例,我们希望订单服务在其本地数据库中创建一个订单,并以一致的方式与支付服务交换该信息。
通过使用 outbox 模式,order-service会将 book1 订单插入到 order 表中,并且作为同一事务的一部分,它还将在 outbox 表中插入表示要发送的事件的记录。
如您所料,我们需要一个异步进程来驱动从发件箱表到 Kafka 的更新,该进程将从发件箱表中读取事件并将它们发送到 Kafka。
- order-service : 在数据库中插入订单
- order-service:在数据库中插入 Kafka 有效负载
- outbox-process:从发件箱表中读取事件并使用至少一次策略将其发送到 Kafka
- payment-service : 消费事件并更新seller1的余额
发件箱异步流程
需要触发发件箱异步过程,以便实际传播我们保存在发件箱表中的事件。这需要尽快完成,以避免在order-service中的订单创建和payment-service中的卖家余额更新之间出现任何额外的延迟。有两种选择:
1、使用 Kafka 消费者触发事件
这里的想法是每次我们向发件箱表添加记录时,在“触发发件箱进程”主题中发送一个事件(使用最多一次语义),触发事件将被“发件箱进程”消费这将从发件箱表中获取/删除数据并将其发送到 Kafka。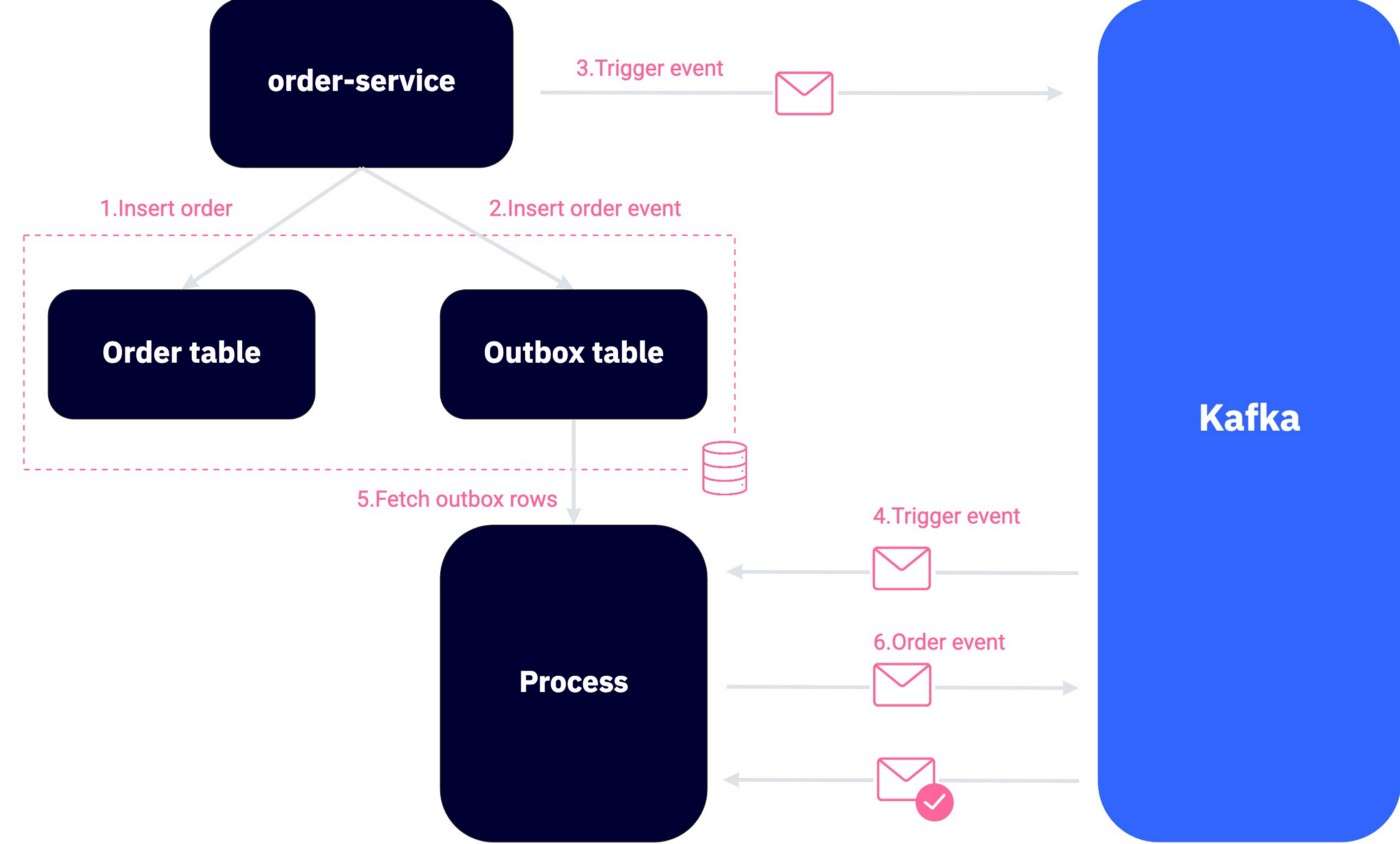
2、使用 Debezium 捕获变更数据
如果您的基础架构允许,您可以简单地使用 Debezium,这是一种为变更数据捕获提供低延迟数据流平台的工具。您可以将其配置为监控发件箱表中的所有更改并将其流式传输到 Kafka。可以在此处找到有关其工作原理的更多详细信息。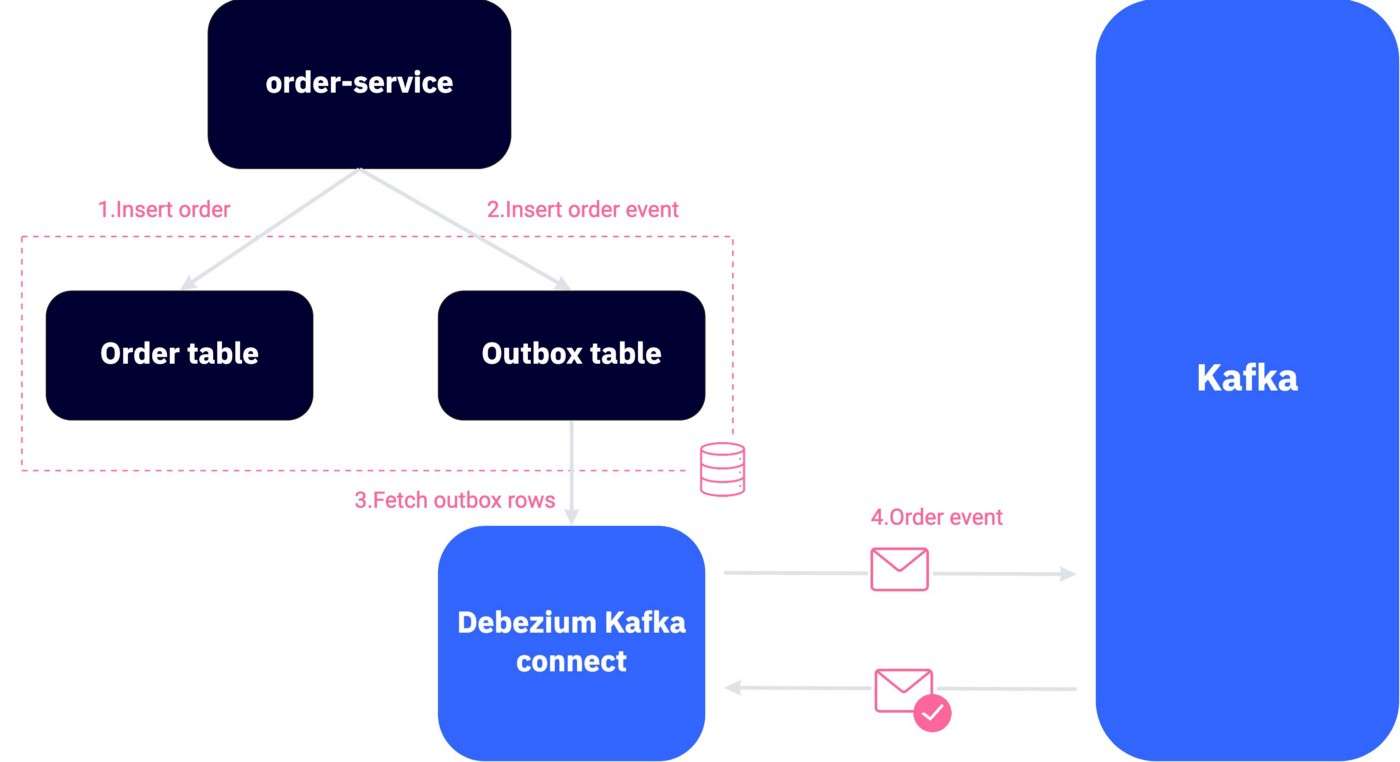
处理数据库膨胀
无论您选择哪种解决方案,您都需要记住需要维护发件箱表,您不能只是永远插入行并期望整个过程正常工作。
为了防止发件箱表变大,您需要在确保成功发送到Kafka之后删除每一行。问题是,删除行会导致膨胀,从而导致性能问题(查询缓慢、Kafka 滞后)。幸运的是,可以通过监控膨胀并在每次膨胀超过一定限度时执行真空分析来轻松解决此问题。
这如何使它具有事务性
在深入研究使我们的解决方案具有事务性之前,我们需要建立一个共同的理解基础,它就像一组公理,可以帮助我们构建和理解更复杂的表达式:
- 如果成功发送消息到 Kafka,消息最终会被消费(当然你需要确保消息被所有副本复制,并且保留时间足以让消息在删除前被消费)。
- 如果您成功将消息保存到发件箱表,该消息将被发送到 Kafka。
- 从上面的两个表达式中,我们可以安全地假设:如果一条消息被保存到发件箱表中,它将被消费。
话虽如此,了解我们的解决方案如何是事务性的可以很简单:
1、原子性
一切都被视为一个单一的单元,它要么完全成功,要么完全失败。在我们的例子中,我们在同一事务中在 order 表中插入一行,在 outbox 表中插入一行,如果我们考虑到 outbox 表中的事件将被发送并最终被支付服务消费,这就足够了。如果事务回滚,则不会在发件箱表中插入任何数据,因此不会向 Kafka 发送任何事件。
2、一致性
我们的数据整体是一致的,虽然我们创建了一个订单没有更新卖家余额,但是我们在发件箱表中添加了负责更新卖家余额的事件,所以一旦事件被消费,卖家的余额最终会是更新。
3、隔离
在我们的例子中,我们的数据库保证的隔离级别就足够了,因为我们不会在 order-service 中从 Kafka 读取数据。换句话说,如果两个事务试图购买最后剩下的书,那么只有一个会成功,因为隔离是由数据库保证的。
4、耐用性
Kafka 将跨复制分区的多个副本中的记录保存到基于磁盘的文件系统中。这意味着如果系统崩溃,我们的数据不会丢失。
概括
在微服务时代,系统故障是不可避免的。作为开发人员,我们必须使我们的设计适应这种恶劣的环境,并始终牢记系统故障。在本文中,我描述了可靠消息传递的问题,使用 Kafka 传递语义的局限性,以及如何使用发件箱模式来解决这个问题,发件箱模式需要以下组件功能齐全:
- 至少包含两列的发件箱表(id UUID,有效负载:jsonb)
- 将事件保存到发件箱表的生产者
- 从发件箱表中删除事件并使用至少一次策略将它们发送到 Kafka 的过程
- 监控和修复膨胀问题的过程
- 消费事件的幂等消费者