从单体应用程序迁移时,微服务起着至关重要的作用。它们有助于提高应用程序的可扩展性、可管理性、敏捷性或交付速度。但是,使用微服务存在一些挑战,例如状态处理。作为开发人员,我们必须知道如何克服这些问题以最大限度地利用微服务。对于大多数这些问题,使用事件溯源是一个很好的解决方案。因此,在本文中,我将讨论为什么我们应该在微服务中使用事件溯源以及使用它的优势。
什么是事件溯源
事件溯源是一种持久化数据的替代方法。与其他状态持久化方法(如面向状态的持久化)相比,事件溯源将所有状态突变存储为称为事件的单独记录。例如,当客户将商品放入在线购买平台中的购物车时,事件溯源会将购物车中的所有状态更改保存为状态更改事件列表。每当实体的状态发生变化时,都会将新事件附加到事件列表中。
1. 从领域驱动设计的平滑过渡
在项目的设计阶段,开发人员和设计师分析领域并进行事件风暴/事件建模。这里的目标是从纯粹的设计角度来识别项目。但是,对话的一部分是高度面向事件的。因此,努力的结果是开发人员将构建的微服务。因此,命令和事件进入这些不同的微服务。事件溯源进入实施阶段。首先,代码和系统的数据流是使用事件溯源实现的,因为设计是使用事件思维方式完成的。
2. 减少耦合
假设两个微服务松散耦合的场景。如果在一个微服务中发生设计、实现或行为更改,则不会导致另一次更改。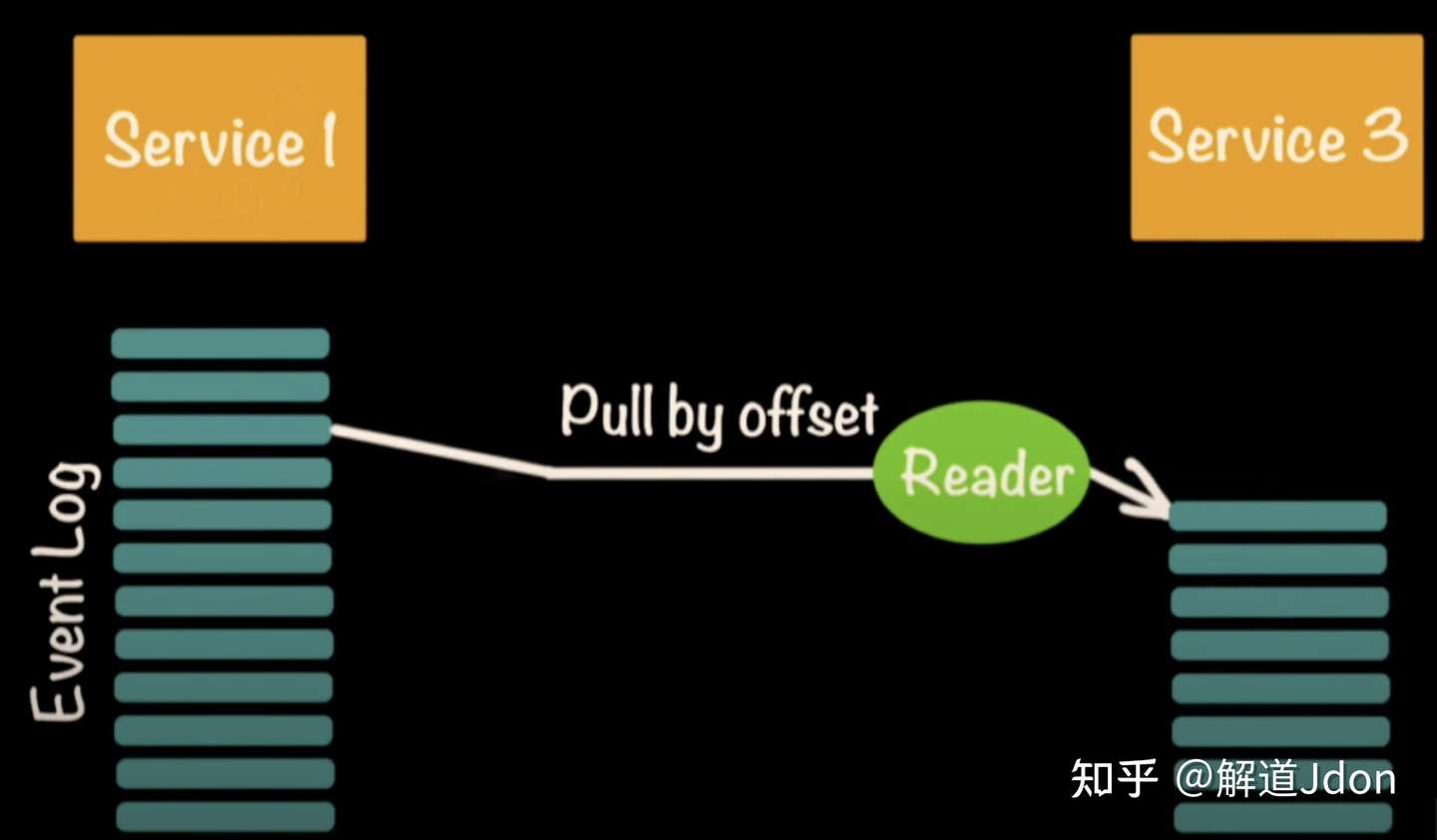
但是,当涉及到微服务时,可能会发生耦合。例如,如果对微服务进行更改,它将导致所有其他微服务直接或间接与第一个微服务协作。
3. 优化读写性能瓶颈
想象一个典型的系统,其中包含许多可能是多年来构建并由单个数据库管理的操作。但是,在执行 CRUD 操作时,可以针对读取和写入优化数据库。但这始终是一种权衡。如果您针对读取进行优化,则会以写入为代价。如果您针对写入进行优化,则会带来昂贵的读取。因此,存在明显的、重大的权衡取舍。然而,事件溯源解决了这个问题。在事件溯源方面,它使用隔离持久性。也就是说,我们得到了正在插入事件的事件存储。所有的 CRUD 操作都变成了存储和事件。所有这些事件都聚合到开发人员需要执行的当前操作状态。这里事件存储的真正优势在于用户的开销,读写操作的瓶颈会减少。
4. 提升并发障碍
在大型企业应用程序中出现流量峰值的可能性更大。这种情况会影响应用程序数据库,解决它们可能会很痛苦。是的,这些问题可以通过花费三到四个星期来解决。但是,您仍然会遇到数据库刚刚被推到极限的情况。
这是事件溯源越来越成为一种流行方法的另一个原因。事件溯源通过将峰值中的记录写入事件日志并将其插入事件日志而不让读取端等待来处理此问题。
5. 简化和强化消息传递
微服务中消息传递的语义可以分为三类。
- In most once — 消息可能无法送达的情况,在某些情况下您会丢失消息。在考虑我们构建的微服务时,这不是一个可接受的特性。
- 至少一次——该类别是最容易实现的。在这种情况下,一条消息至少可以传递一次。另一方面,某条消息可以传递两次以上。
- 恰好一次——一种相当神秘的方法,难以实施,但从消费者的角度来看仍然可行。
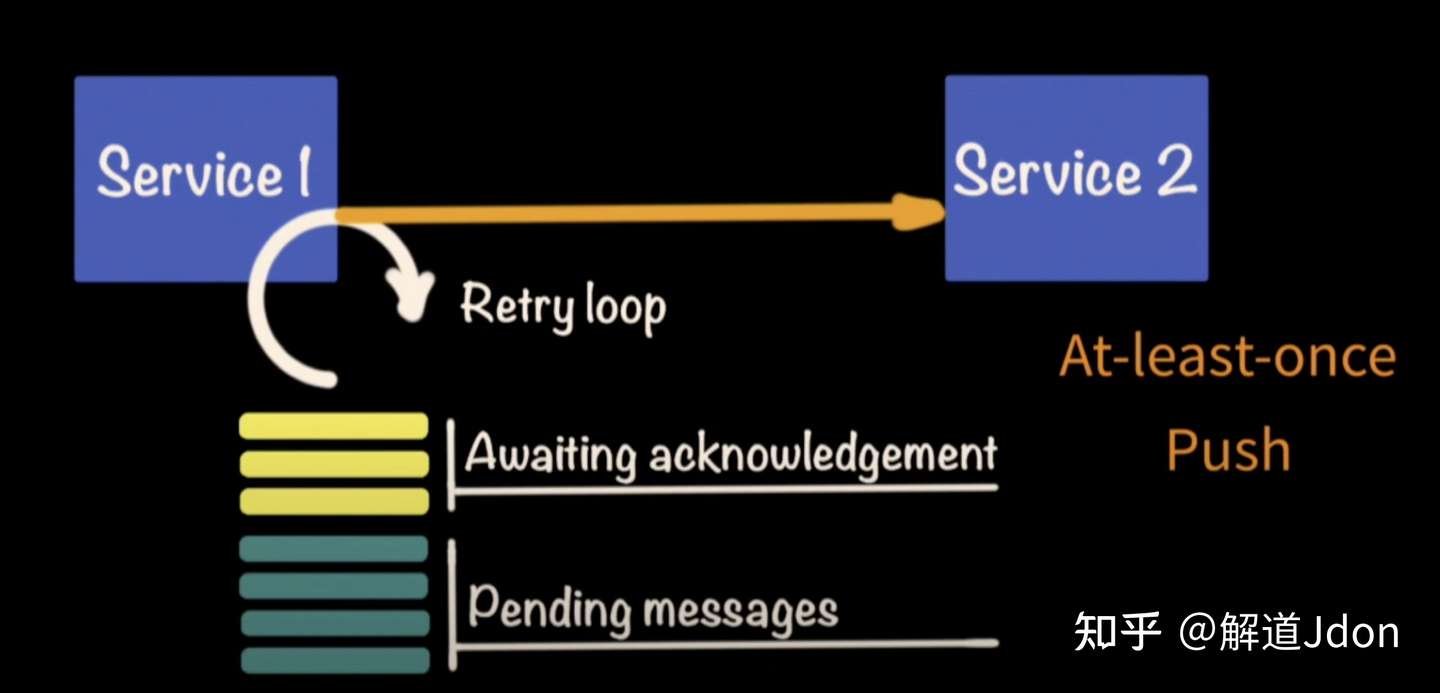
在某些情况下,消息不会第一次传递。因此解决方案将实施重试逻辑。当开发人员实现重试逻辑时,他们必须开始考虑像生产者服务试图发布数据这样的情况。它必须能够处于某些消息尚未传递的模式。此外,服务等案例也会下降。当该服务返回时,它能否从中断的地方继续并继续重试发送这些消息?这种情况给生产者带来了很大的复杂性。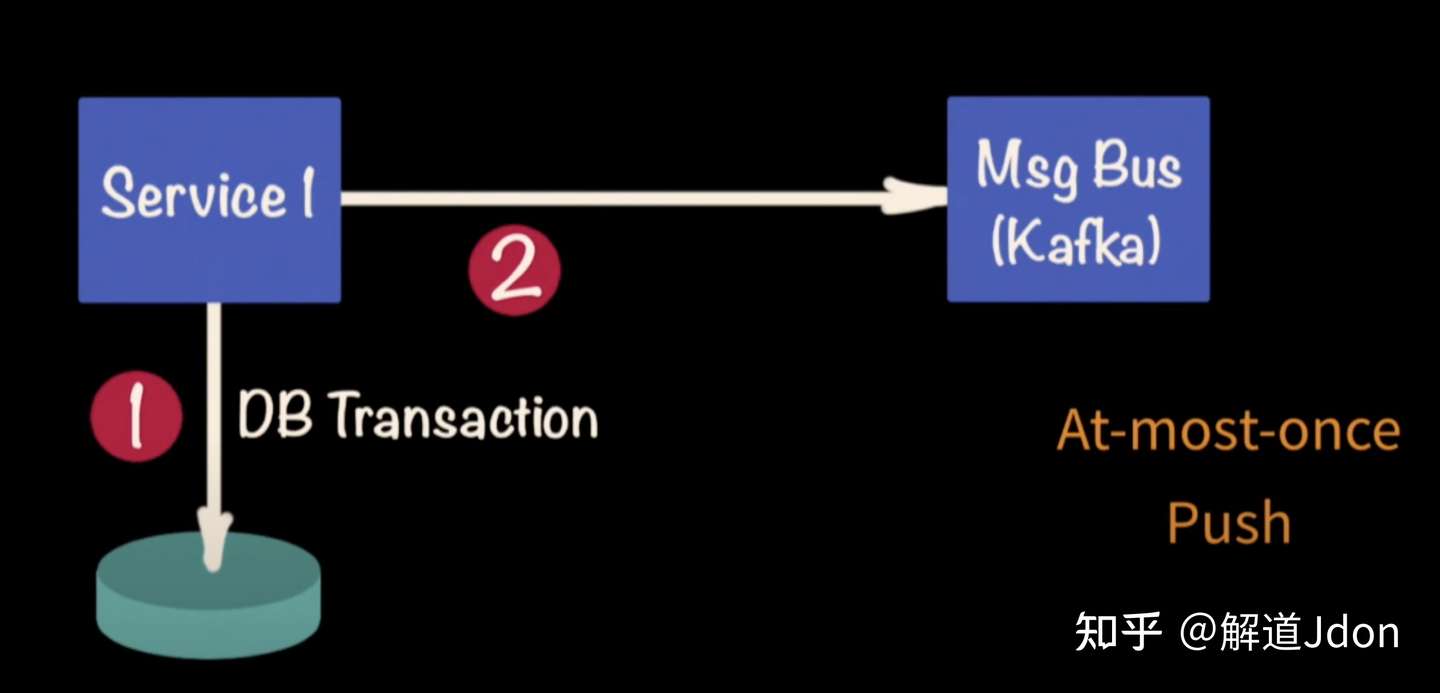
另外,想象一下服务首先执行数据库事务,然后调用 Kafka 的场景。由于这是两个独立的事务,首先会发生数据库事务。但是,Kafka 中的消息不会通过。所以这是管道泄漏,消费者有潜在的脆弱性。当服务在该暴露期间出现故障时,消息将丢失。使用事件溯源时,开发人员无需担心消息失败。所以在这里,消息不会推送给 Kafka 消费者。Kafka 消费者拉取,并且更容易实现这种拉取模式。
6.消除服务耦合
想象一下我们有客户服务帮助其他一些服务的情况。如果客户服务下降,其他服务也会下降。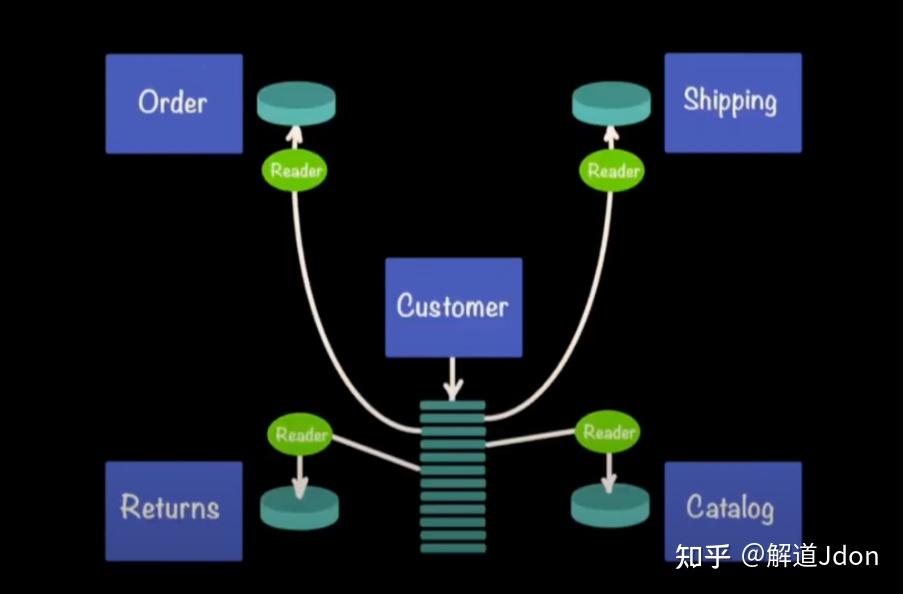
使用事件溯源时,方法是客户发布,其他服务消费。在这种情况下,如果客户服务出去了,直到它回来才没有伤害。
结论
微服务架构是后端开发中常用的架构之一。但是,了解如何以优化和轻松的方式使用它至关重要。在这篇文章中,我解释了为什么你应该使用事件源和微服务来避免常见的陷阱的 6 个原因。我希望本文能帮助您以更优化的方式开发微服务。感谢您的阅读。