如何构建流数据管道以捕获 MySQL 数据库更改并通过 Debezium 和 Kafka 将它们流式传输到 Apache Pinot?
Upserting意味着如果记录不存在则将其插入数据库中,或者如果存在则更新它。流数据管道末端的分析数据库可以从 upserts 中受益,以保持与源数据库的数据一致性。本文探讨了流数据管道的最小可行设置,该管道捕获来自 MySQL 的更改并通过 Debezium 和 Apache Kafka 将它们流式传输到 Apache Pinot。您可以找到多个关于同一主题的视频。但本文为您提供了开始大规模构建 CDC 管道的可靠蓝图。
为什么我们需要 upsert?
实时分析系统由几个子系统组成,这些子系统协同工作,从流经它们的事件中获得洞察力。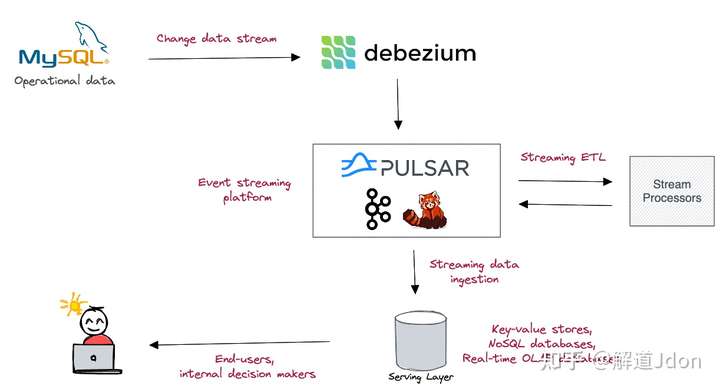
变更数据捕获 (CDC) 工具(例如Debezium )捕获事务数据库中的变更,将它们转换为事件并将它们流式传输到Kafka或Pulsar等事件流平台中。这些事件可以选择通过流式 ETL 管道进行进一步按摩,最终将进入服务层,这是一个读取优化的数据存储,可大规模提供分析服务。流经实时分析系统的事件通常具有键值对结构。通常,事件键由事件属性组成,而值由事件负荷组成。
实际上,到达流中的事件可以具有相同的键,同时随着时间的推移具有更新的值。例如,来自 ORDERS 表的变更日志流可以具有相同的键(订单 ID),但随着时间的推移,有效负载中的值可能不同。
当服务层接收到这些更改事件时,它会决定如何处理它们。
假设事件被写入服务数据库中的表,可以有两种选择:
- 追加- 具有相同键的更改事件作为新行附加到表中,捕获对源表所做的每个更改。
- Upsert - 具有相同键的更改事件被合并以反映事件的最新版本。目标表中只能有一个事件具有相同的键。
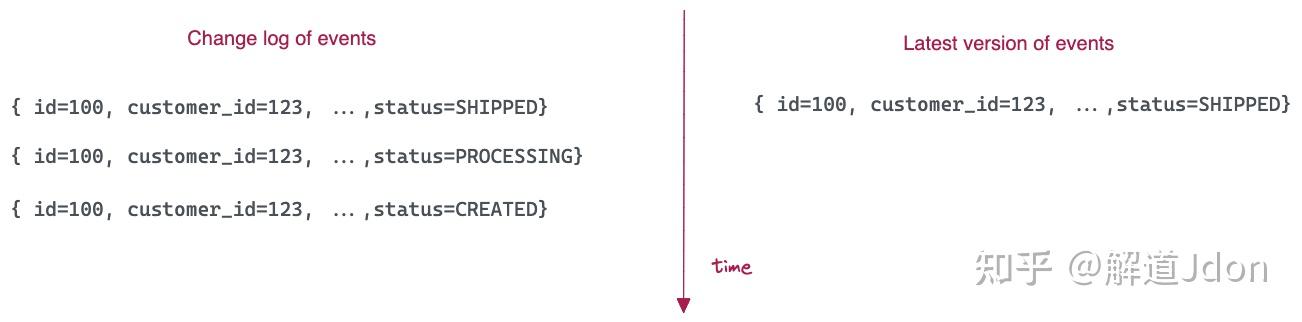
Upsert 有助于在源数据库和派生数据系统之间保持强大的数据一致性。因为,从分析的角度来看,您可能只对最新版本的事件感兴趣。
使用 Apache Pinot 进行更新
Apache Pinot是一个实时 OLAP 数据库,它可以从 Kafka 等流数据源中摄取数据,并对摄取的数据运行高吞吐量、低延迟的 OLAP 查询。由于其速度、吞吐量和保持数据新鲜度的能力,Apache Pinot 非常适合服务层。虽然 Pinot 内部的数据是不可变的,但它从0.6.0 版本开始支持 upsert ,允许您仅查询流入其中的事件的最新版本。但请记住,即使您在 Pinot 表上启用 upsert,数据也保持不变。
使用 MySQL、Debezium、Kafka 和 Pinot 更新 MVP
对于那些想要快速设置和试验 Pinot 如何与 Apache Pinot 生态系统一起工作的人,我将一个 Docker 组合在一起,组成了一个项目,该项目只带来了最小但必不可少的组件。不耐烦的读者可以继续从下面克隆 Git 存储库:
GitHub - dunithd/edu-samples: This repository contains the source code for samples featured in eventdrivenutopia.com
在接下来的部分中,我将向您介绍每个项目组件。用例该项目模仿了一个使用 MySQL 作为事务数据库的在线电子商务商店。电子商务订单orders通过以下模式在 MySQL 表中捕获。如果不存在,则创建表 fakeshop.orders
CREATE TABLE IF NOT EXISTS fakeshop.orders |
当订单经历其生命周期阶段时,该status字段应从 OPEN 过渡到 PROCESSING 到 SHIPPED。目标是捕获对 MySQL 中订单表所做的更改并将它们发送到 Apache Pinot,以便我们可以对订单进行实时分析。我们将使用 Debezium 和 Apache Kafka 来构建这个实时数据管道。Debezium 捕获对订单表所做的更改并将它们流式传输到 Kafka,从而允许 Pinot 实时摄取它们。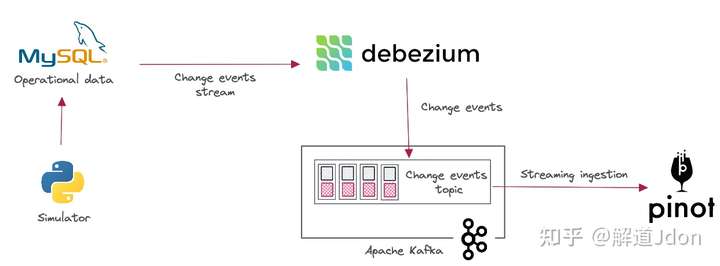
设置项目
该项目以Docker Compose项目的形式出现,并且处于准备运行状态。首先,确保您的机器上安装了Docker Compose ,并为 Docker 引擎分配至少6 个 CPU 内核和8 GB内存。克隆以下 Git 存储库并更改为pinot-upserts文件夹。
git clone git@github.com :dunithd/edu-samples.git |
您将在docker-compose.yml捆绑以下容器的项目根目录中找到该文件。
- MySQL database
- Zookeeper
- Kafka
- Debezium
- Pinot Controller
- Pinot Broker
- Pinot Server
- Order simulator
详细步骤点击标题
概括
在源数据库和派生数据库之间保持强大的数据一致性对于基于 CDC 的流数据管道至关重要。随着数据的快速变化,目标数据库必须反映对源数据库所做的最新更改。像 Apache Pinot 这样的实时 OLAP 数据库利用其 upsert 功能来提供强大的端到端数据一致性。Upserts 确保摄取的数据集始终准确并保持最新以反映上游更改。