数据复制是制作数据项的多个副本以确保可用性的过程。复制的数据通常存储在不同的数据库实例中,因此即使一个实例发生故障,我们也可以从其他实例中获取数据。
实现数据复制的一种流行架构是主从架构。
主从架构
为了理解这种架构,让我们举个例子。
认为,
- 我们有四个客户端,每个客户端都连接到一个负载均衡器。
- 然后负载平衡器将请求分发到三个应用程序服务器。
- 每台服务器都连接到一个数据库实例。
我们注意到这里有什么问题吗?
我们的数据库是单点故障。如果它崩溃了,我们的整个系统就会停止工作。
为了避免这种单点故障,我们可以使用另一个数据库(最好是不同的数据库实例)来存储原始数据的副本。现在,如果原始数据库崩溃,我们可以将请求路由到辅助数据库。
但是我们如何使辅助数据库与主数据库保持同步呢?嗯,有两种方法:
同步复制数据
- 在这种方法中,数据同时写入主存储和副本
- 数据总是一致的。即,如果数据被写入主存储,它将被写入副本
- 数据库负载高
异步复制数据
- 在这种方法中,首先将数据写入主存储,然后定期将更新写入副本
- 由于复制以固定的时间间隔发生,因此可能会丢失数据和不一致
- 数据库上的负载相对较低
获取写入请求的数据库是主数据库。副本被称为奴隶slave从节点。
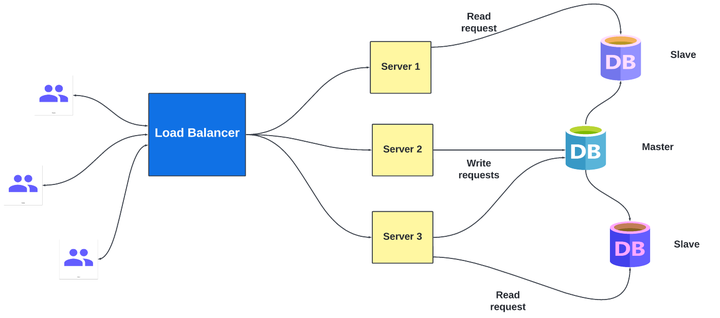
主服务器维护一个事务日志。为了更新从节点中的数据,它发送命令,从节点以相同的顺序执行这些命令。
如果服务器向从服务器发送书面请求会发生什么?
有两种方法可以处理这种情况
- 不允许对从属的写请求 从属不能写入数据库,它只是存储数据的副本。
- 允许从机写入数据。我们将允许从站写入数据。然后从服务器将更改传播给主服务器。在这种情况下,slave 已经接管了 master 的角色。所以不再是主从架构而是主主架构
Master-Master主-主架构的问题
通信故障会导致主-主架构中的数据不一致。
让我们通过一个例子来理解这一点,
假设我们有两个数据库实例,A 和 B。
- 两人都是大师。
- 他们之间的路由器出现故障。所以 A 认为 B 离线,B 认为 A 离线。
- 他们有一个数据项 X,其值最初为 100。
现在用户发送以下请求,
- 从 X 中减去 20。这个请求被路由到 A。现在 A 中 X 的值是 80。
- 从 X 中减去 80。这个请求被路由到 B(因为两者都是 master,所以写请求可以路由到任何数据库)。现在 B 中 X 的值为 20。
由于通信失败,A和B不能同步,它们的数据值不同,因此不一致。
- 现在,如果用户发出读取请求,他/她将根据他/她将连接到的数据库获得不同的值。
这个问题被称为裂脑问题。
解决脑裂问题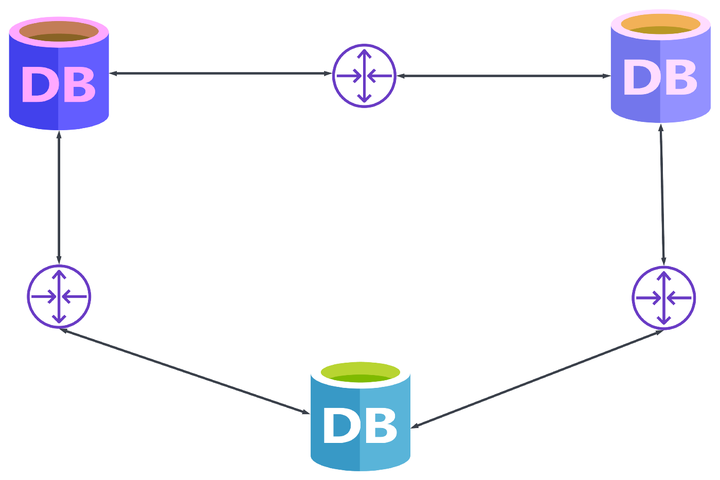
我们可以通过添加第三个节点(数据库实例)来解决脑裂问题。
在这里,我们假设一个节点崩溃并且其他两个节点之间的路由器崩溃的可能性极小。
让我们考虑三个数据库实例 A、B 和 C。
- 如果 C 崩溃,A 和 B 是 master 并且它们是同步的。所以他们处于一致的状态。当 C 在线时,他们可以从 A 或 B 读取。
- 如果 A 和 B 之间出现通信故障
- 当 A 收到书面请求时,它将其状态传播给 C。最初状态为 S0,然后移动到 Sx。所以现在 A 和 C 都有 Sx。
- 当 B 收到书面请求时,它会将其状态从 S0 移动到 Sy。它尝试将其状态传播到 C,但由于 B 的先前状态不等于 C,它失败了。现在 B 中止写请求并将其状态更新为 Sx。现在 B 可以接受写入请求并将更改传播到 C。
这被称为分布式共识。多个节点就一个特定值达成一致。在这种情况下,A、B 和 C 在最终状态下达成一致。