LMAX Disruptor 是 Java 中最好的库之一,用于构建具有无锁队列的有界队列。Hubspot 撰写了有关 LMAX Disruptor 如何帮助构建快速、线程安全的跟踪库的文章:
HubSpot 的用例是单个进程中的多个线程需要协调以在高基数数据流中查找最频繁的项目。在这篇博文中,我们以一种快速、线程安全和内存高效的方式描述了我们的设计。
HubSpot 后端的 Web 服务都运行大量线程,用于同时处理多个 HTTP 请求。我们处理的大部分工作负载都是 I/O 绑定的,因此通常需要使用大量线程运行我们的 Web 服务才能获得充分的 CPU 利用率。
多年来,我们的 Web 服务经常遇到的一个问题是接收大量并发请求,每个请求都要求我们从后备数据库中获取同一行。这种访问模式会降低我们 API 的性能,因为所有这些请求都转到后备数据库的同一个节点,可能会使其过载。
我们将此场景称为热点,它会使我们的用户体验缓慢且不可靠。
发生这种情况时,为了缓解问题,我们需要能够跟踪哪些行被频繁访问。
换句话说,我们需要知道哪些数据行是“热的”。
我们将首先介绍热点跟踪系统的简单、幼稚设计。我们将讨论为什么这种方法不起作用,然后我们将迭代设计并进行改进,直到我们的设计达到快速、线程安全和内存高效的地方。如果您从事并发编程,尤其是在 Java 中,希望这能激发您的想象力并为您提供可以在未来应用的想法。
原始方式
假设我们有一个 Web 服务,调用者发出 HTTP 请求以获取一些资源,并且每个资源都由一个字符串唯一标识。为了处理请求资源 XYZ 的 HTTP 请求,我们做两件事:
- 记录在我们的热点跟踪器中请求资源 XYZ 的事实。这将帮助我们检测资源 XYZ 是否很热。
- 从数据库中获取资源 XYZ 的数据(例如,SELECT * from table where id = XYZ)并将该数据返回给调用者。
对于第 1 步,我们的 Web 服务的每个实例都将拥有一个 HotspotTracker 对象。这个单例 HotspotTracker 将在进程中的所有 HTTP 请求线程之间共享。一个简单的实现可能看起来像这样:
为简洁起见,此处未显示,但后台线程将每分钟运行一次并执行以下操作:
- 报告前一分钟计数最高的十个ID(即报告最热的ID)
- 清除 countsById map
这种每分钟一次的热 ID 报告可以记录下来供工程师稍后查看,或者它也可以暴露给应用程序的其他部分,因此我们可以对热 ID 应用特殊处理(如这里)。
如果你熟悉 Java 中的并发编程,你就会知道上面的设计是行不通的,因为 HashMap 不是线程安全的。并发运行的 HTTP 请求需要安全地共享这个 HotSpotTracker,所以我们需要使用线程安全的数据结构。更正确的实现可能如下所示:
public class HotspotTracker { |
ConcurrentHashMap 和 AtomicLong 是线程安全的,因此这种设计更好,但这种方法存在一个主要缺陷。
这个类的内存使用是无限的。尽管我们每分钟都在清除countsById映射,但我们的 Web 服务的每个实例每秒都可以接收数千个请求,并且这些请求中的每一个都可能提供与其他请求不同的 ID。在一分钟的过程中,映射可能会积累大量的条目,如果 ID 字符串很大,我们的进程很容易耗尽内存。我们需要一种使用有限内存来跟踪热 ID 的方法。
public class HotspotTracker { |
StreamSummary
为了限制HotSpotTracker的内存使用,我们将用StreamSummary替换我们的countsById映射。
StreamSummary 是一种数据结构,来自一个名为stream-lib的流行开源项目。它基于本文提出的算法,非常适合我们的用例。如论文中所述,StreamSummary“节省空间,并报告前 k 个元素和频繁出现的元素,并严格保证错误”。
与HyperLogLogs等概率数据结构类似,StreamSummary 是一种数据结构,它允许我们通过仅近似热 ID 的计数来显着减少内存使用。存储每个 ID 的准确计数需要使用与唯一 ID 数量成比例的内存量。但是通过允许热 ID 的近似(但仍然非常接近)计数而不是所有 ID 的精确计数,我们可以设置内存使用的上限。所以现在我们的设计可能是这样的:
public class HotspotTracker { |
现在我们已经解决了无限的内存使用问题。
但不幸的是,在这样做的过程中,我们引入了另一个问题。StreamSummary 不是线程安全的,所以类似于这篇博文中提出的第一个设计,这个设计被打破了。
如果我们查看 StreamSummary 的内部实现细节,我们会看到它使用像 HashMap 这样的非线程安全类来管理状态。
stream-lib 确实提供了一个名为 ConcurrentStreamSummary 的线程安全类,它具有类似的接口。但是,实现方式很不一样,性能不够,所以我们不能使用它。我们需要找到一种方法在多个 HTTP 请求线程之间安全地共享这个非线程安全的 StreamSummary。
使对 StreamSummary 的共享访问安全的一种简单方法是同步synchronized 对它的所有访问:
public class HotspotTracker { |
如果我们同步对该代码的所有访问,多个线程可以安全地共享非线程安全代码。所以现在我们的程序既是内存高效的又是线程安全的。
那么我们完成了吗?还没有。
synchronized 关键字导致每个调用track方法的线程在执行 HotspotTracker 对象之前获取它的锁,因此我们的程序现在比以前慢得多。我们的 Web 服务同时处理许多 HTTP 请求,以便利用它们运行的多核处理器。通过同步对 HotspotTracker 的所有访问,我们将在原本高度并行化的进程中添加一个单点争用,并且性能会受到影响。
队列
这些问题通常通过使用内存队列来解决。与其让我们所有的 HTTP 请求线程直接将项目添加到 StreamSummary,它们可以将项目放置到共享的内存队列中,然后单个后台线程可以连续消耗队列中的项目并更新 StreamSummary:
public class HotspotTracker { |
为简洁起见,我们省略了启动后台线程的代码,该线程消耗队列中的项目。在这篇文章中,我们将只关注将项目推入队列的代码。从视觉上看,这个设计看起来像这样: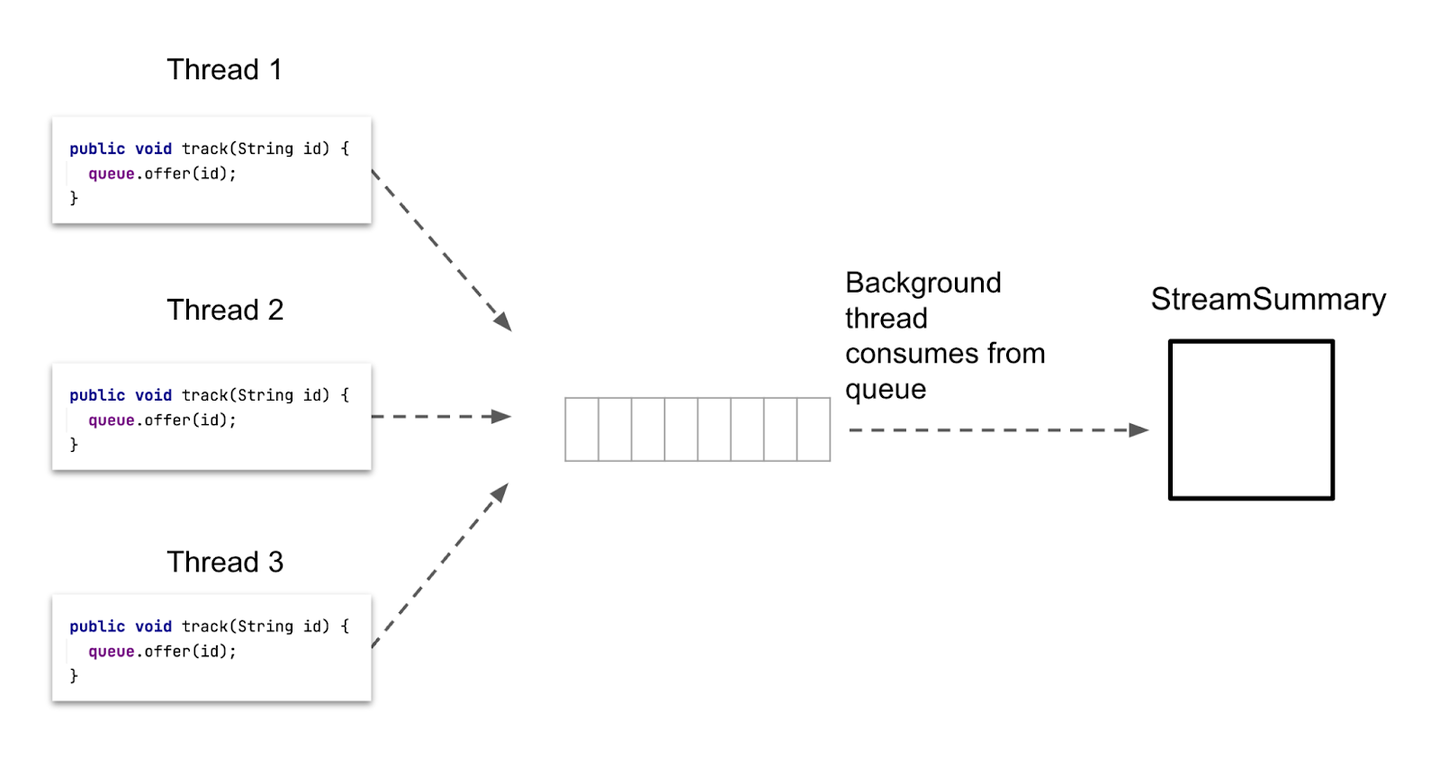
在这个设计中,因为只有一个线程更新 StreamSummary,所以 StreamSummary 不是线程安全的也没关系。
使用 ConcurrentLinkedQueue 作为我们的队列实现的一个好处是它使用无锁算法将项目推入队列。因此,即使多个线程同时将项目添加到队列中,竞争也很小,程序也很快。
不幸的是,ConcurrentLinkedQueue 有一个主要缺点。它是无限的,并且没有固定时间的方式来询问队列的当前大小,所以如果我们的 HTTP 请求线程将项目添加到队列中的速度比我们的后台线程处理它们的速度快,那么队列将无限增长,我们的进程将内存不足。
我们需要一个有界队列,而 Java 平台就是这样。我们可以使用 ArrayBlockingQueue 代替 ConcurrentLinkedQueue:
public class HotspotTracker { |
现在,如果从队列中消费项目的线程跟不上,队列就不会无限增长。如果队列已满,我们的 HTTP 请求线程将无法将项目添加到队列中,并且我们不会跟踪该请求。在这种情况下,我们的热点跟踪会失去一些准确性,但这比内存不足和进程崩溃要好得多。
我们的程序现在是线程安全和内存高效的,但是我们又一次让我们的程序变慢了。ArrayBlockingQueue 的实现方式是线程需要在将项目放入队列之前获取队列上的锁。与之前同步所有对 StreamSummary 的访问的方法类似,我们引入了单点争用,这将降低程序可以运行的并行度,并且性能会受到影响。
我们需要 HotspotTracker 快速、线程安全和内存高效。
在迄今为止的所有设计中,我们最多只能满足这三个要求中的两个。
为了满足这三个要求,我们需要标准 Java 平台之外的一些帮助。
最终设计
Java 平台标准队列的问题是它们要么是有界的,要么是无锁的,但不是两者兼而有之。
幸运的是,有一个解决这个问题的灵丹妙药,LMAX Disruptor。这个流行的开源库为我们提供了我们所需要的东西:具有无锁队列的有界队列。
正如他们在技术论文中所描述的那样,由于 LMAX Disruptor 不使用锁,因此它比 ArrayBlockingQueue 快得多,这使其成为构建高性能并发应用程序的非常有用的工具。
将 ArrayBlockingQueue 换成 LMAX Disruptor,我们的设计现在看起来像这样: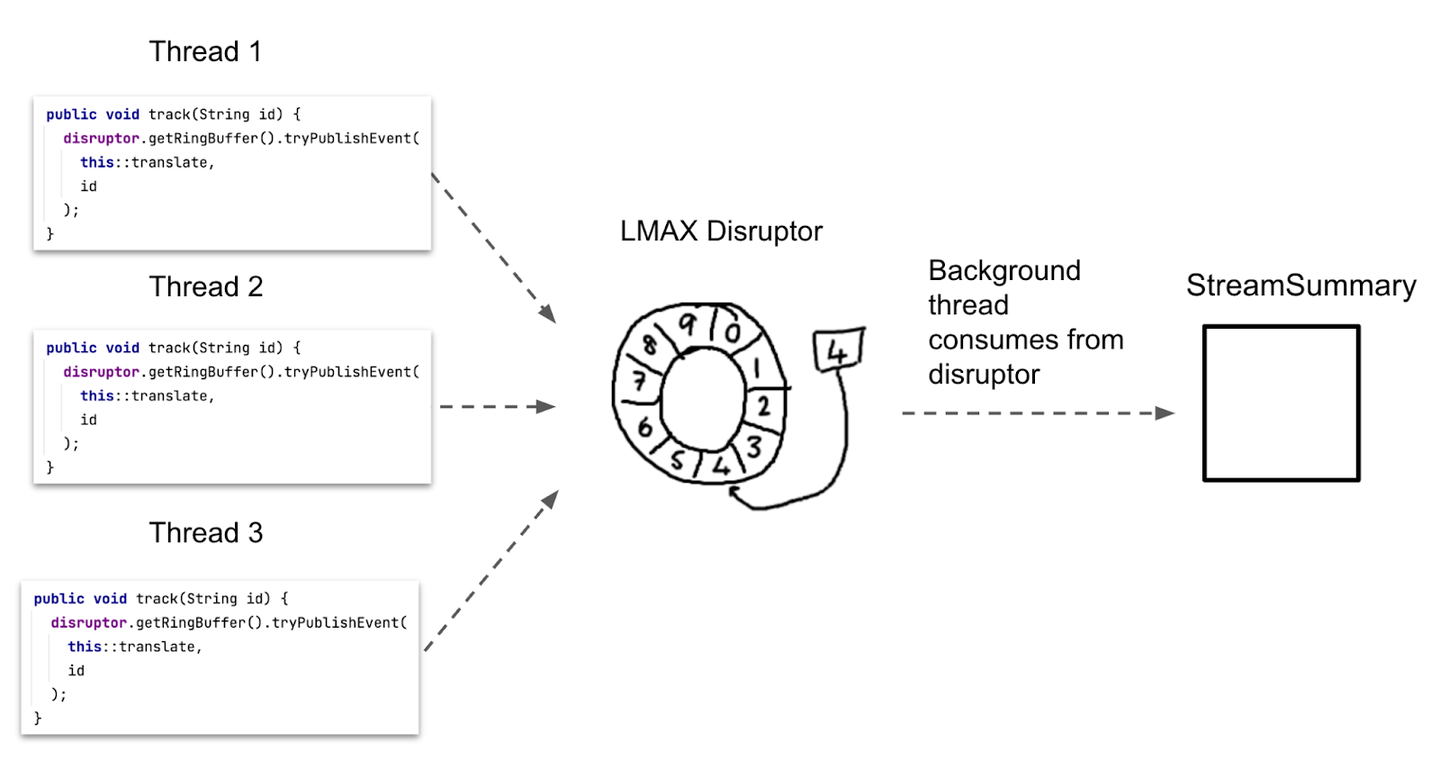
与 Java 平台的标准队列不同,LMAX Disruptor 的 API 有点令人困惑。
使用它涉及很多样板,因此我们省略了本文中的大部分代码。
但是,从概念上讲,您可以将其视为就像 ArrayBlockingQueue,只是速度更快。
结论
这是我们对 HotspotTracker 的最终设计。它快速、线程安全且内存高效。
引入并发可以显着提高应用程序的性能,但正如我们在这篇博文中所见,它也迫使我们仔细考虑线程安全和锁争用等问题。