Hashnode 有许多事件驱动的用例,在这篇文章中使用的一个用例是发布一篇文章。如果用户发布帖子,则会启动多个服务:
- 将此帖子转换为音频帖子
- 将此帖子备份到用户的 GitHub
- 向所有订阅者发送时事通讯
- 添加用户活动
- 更新文章圈子
什么是事件驱动架构?
首先,让我们看看EDA到底是什么,没有它我们会面临哪些问题。
事件驱动架构 (EDA) 通过引入一个称为事件的新实体将服务彼此分离。
事件是一些对象(您可以将其想象为一个简单的 JSON 文档),它将被发送到负责将事件发送给多个消费者的协调器(事件总线)。
对于在 hashnode 的发布,我们可以想象这个事件,例如:
{ |
架构组件
EDA 解耦系统,为此,我们需要有几个组件。这里的主要组件是: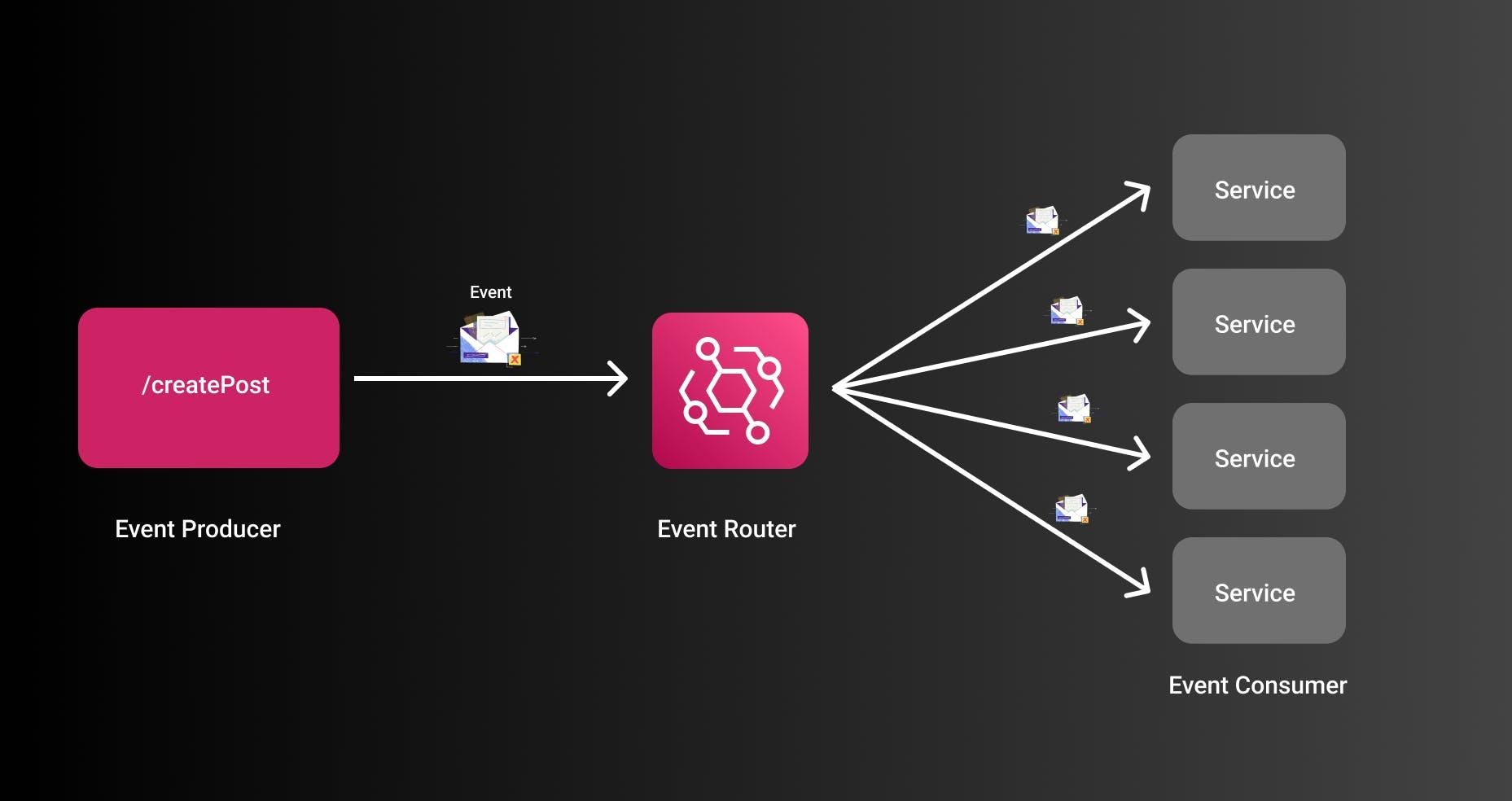
- 事件生产者:发送事件的系统 -> 例如 REST API
- 事件路由器:编排所有事件并启动所需服务的系统
- 事件消费者:消费事件的服务
- 事件:消费者正在处理的实际事件
为什么我们需要事件驱动架构?
现在我们知道了事件驱动架构的组成部分。但是,我们需要迁移到 EDA 所面临的问题是什么? 让我们看一下为什么要在 hashnode 上实现适当的 EDA 的前 3 个原因。
性能和后台任务
用户在使用 hashnode 时应该有惊人的体验。其中一个方面当然是性能。这种情况下的性能是一个端点的执行时间。
例如,单击“发布帖子”按钮与您的帖子实际发布之间的时间。
为了理解这一点,了解同步和异步处理之间的区别至关重要。同步处理通常是典型的 REST API。用户单击按钮Publish Post,只要 API 正在处理(进行 DB 调用、标记为 HTML 等),浏览器就会显示加载指示器。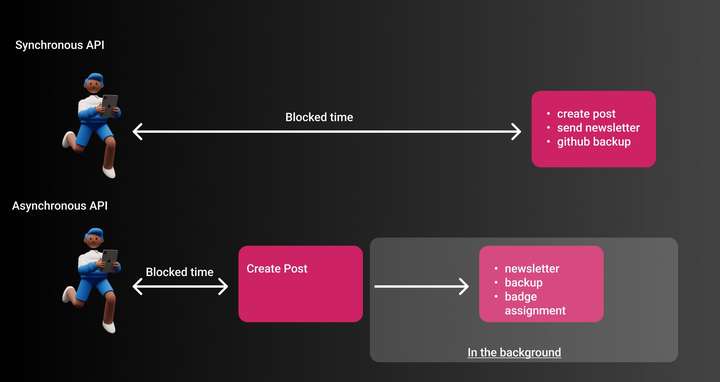
异步处理通常也称为后台处理。用户可以再次与您的应用程序交互,并且不会被阻止继续在您的网站上工作。所有其他任务将在后台处理。 如果我们要添加所有可选服务,例如
- GitHub 备份
- 徽章分配
- 发送通讯
对于我们的同步端点,实际帖子发布并且用户看到它需要很长时间。但是,如果我们只做用户需要的最关键的部分,即发布帖子,并将所有其他任务置于后台,我们将拥有更好的用户体验。 通过引入 EDA,我们允许系统异步处理这些任务,并且完全独立于实际的面向用户的 API。
解耦
第二个主要原因是解耦脱钩。 衡量两个例程或模块的紧密程度 解耦意味着系统和团队可以彼此独立工作,而无需了解更多的接口或 API 规范。 耦合不仅仅是指软件模块,它还可以指许多不同的东西。在此处查看一些示例:
类型例子 |
哈希节点当前状态耦合的一个非常糟糕的情况是事件生产者,即 REST API 需要知道在什么情况下调用哪些服务。
例如,如果在团队博客中发布了一篇文章,并且该博客启用了 GitHub 备份,则 API 需要调用 GitHub 备份服务。
虽然这很简单,但首先,它不能很好地扩展,因为有更多的服务要调用,而且团队中没有更多的开发人员应该拥有他们的服务。 在耦合架构中,它看起来像这样: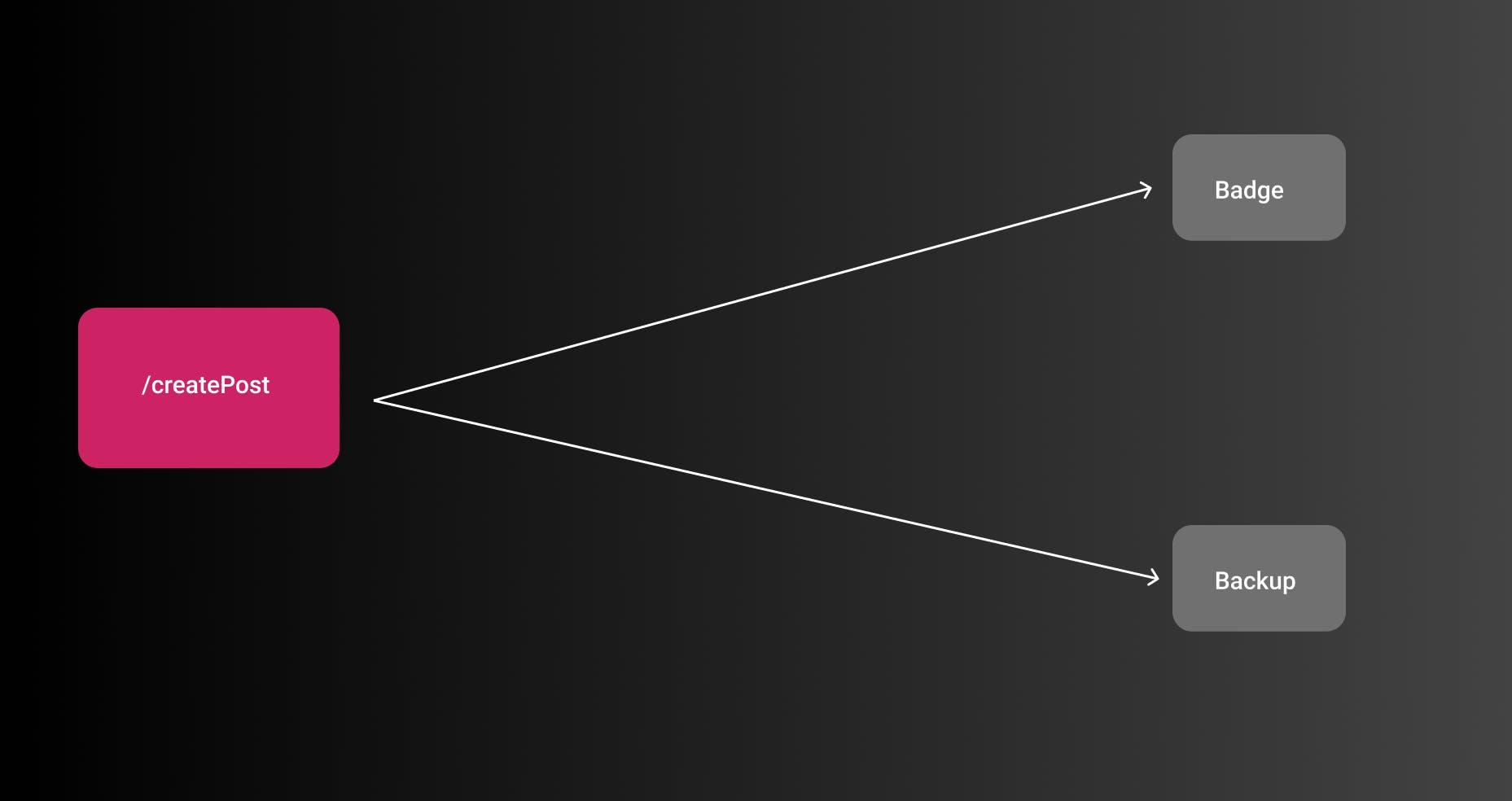
虽然这对于一两个服务来说看起来很容易,但随着功能的增加,这将变得越来越复杂。一段时间后,出现很多子模块相互依赖或在某些情况下必须重试的情况。这应该是考虑解耦架构的重点。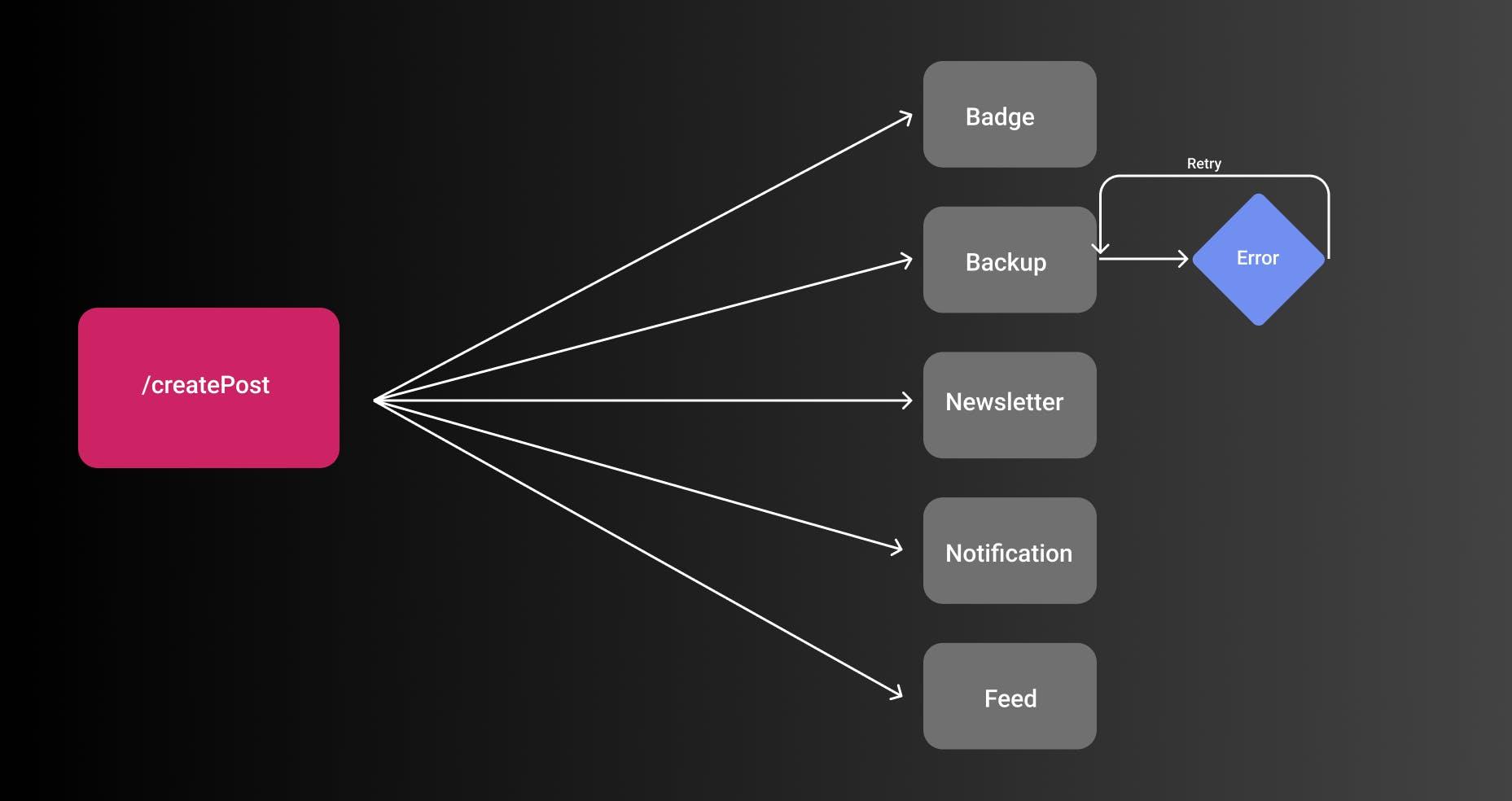
使用适当的 EDA,通过让事件的消费者(例如 GitHub 备份服务)订阅某些事件,这会容易得多。让我们看一个例子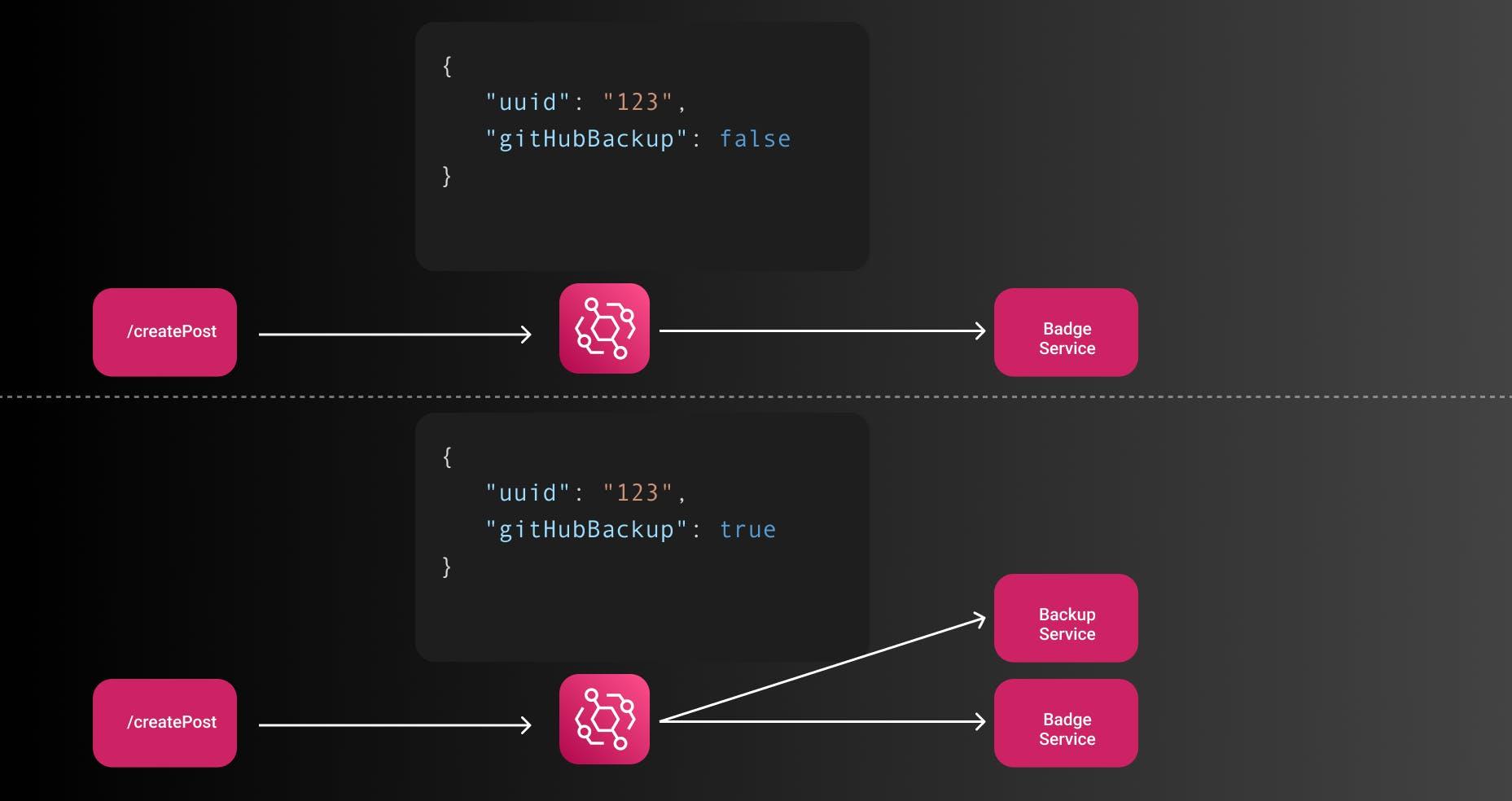
对于所有帖子,徽章分配将开始,因为涉及更多的业务逻辑。
GitHub 备份取决于用户是否在其博客中启用了它。 如果您查看第一个事件,则标志gitHubBackup为false。这意味着该服务不会监听该事件,也不会开始实际备份帖子。
第二个博客已启用gitHubBackup,因此启动了备份服务。 虽然这看起来非常微不足道,但它正确地将事件的生产者和消费者解耦了。作为消费者服务,您可以简单地检查哪些属性可用并为它们创建规则。目标是一个端点简单地触发一个事件postPublished,传递一组预定义的数据,EventBus 和事件消费者订阅这个事件并处理其余的事情。发布者不需要知道任何事情。
可扩展性
第三个原因是可扩展性。
每个在高速增长环境中工作的人都知道这不一定是正确的。 通过解耦系统并实现共享事件类型和添加新事件的适当工作流,实现只监听某些事件类型的服务将变得更加容易。这对于出色的开发体验非常重要。
低耦合 -> 更多开发人员 -> 更好的 DevXP -> 将交付更多
但是通过解耦架构,较小的团队或开发人员可以真正拥有服务,而无需在 6 个不同的地方更改代码。 如果有人想基于某个事件开发服务,那么他们本身并不负责更改整个 API 端点。
好的,我们明白了,EDA 是有道理的。请记住,一切都有取舍。通过引入这种架构,您需要了解如何跨许多不同系统跟踪事件,以便能够了解正在发生的事情。
Hashnode 的当前状态 为了更好地理解 Hashnode 的观点,我想让您了解一下我们当前的架构。
Hashnode 已经并且仍然有巨大的增长。随着巨大的增长和许多新功能,技术债务将自动引入。那也行。但承认这一点并努力应对这些挑战也很重要。
hashnode 的主要 API 是一个运行在虚拟机上的 JavaScript Express Server。 我们已经在使用某种“EDA”,但目前它与实际的 REST API 高度耦合。
对于事件处理,我们使用 Express 的事件功能。
// controlles/post.controller.js |
在事件方面,我们有一个globalEventListener监听请求:
ee.on('publication.post.published', async function (eventData) { |
虽然这不是很糟糕,但我们天生就有紧密的耦合。
在实际的 API 中,我们检查帖子是否是发表时,检查它是否附加了附件。
如果有,我们会发出事件,在事件监听publication.post.published器中,我们执行该函数内的所有业务逻辑。
在消费者中,我们需要检查是否设置了某些标志,例如音频博客功能并根据它们采取行动。
引入EDA消息总线以后,API 只要发布一个具有预定义类型的事件,即PostPublishedEvent,并告诉 EventBus:“嘿,我发布了一个 ID 为 123 的帖子”。而已!其他一切都会得到照顾。
banq注:其实
post.controller.js中 |