在线食品订购和配送是一个竞争激烈的市场,速度是生存的关键。Coupang Eats(简称Eats)是韩国电商巨头Coupang的外卖子公司。
在这篇文章中,我们将详细介绍 Eats 数据平台团队如何构建通用且配置驱动的数据处理系统,通过自动化关键业务运营来加速我们的增长。
介绍
Eats 是一项相对较新的业务,于 2019 年底推出。起初,我们忙于建立业务并确保一切顺利进行。但是现在,我们正处于业务阶段,我们的重点不仅是确保应用程序稳定,还要确保它以更高效、更智能的方式运行。
这意味着使用数据自动化和复杂的机器学习 (ML) 模型以更低的工程成本为更多客户加速业务。例如,我们目前训练 ML 模型以估计交货时间,根据实时用户标签向客户自动促销,并创建动态数据服务以支持数据可视化和度量计算。
这种智能和自动化操作的基础取决于一个强大而全面的数据处理平台,该平台可以根据我们的客户增长扩展并支持我们所有的业务需求,无论是实时分析还是离线数据服务。
在我们业务的早期阶段,我们没有一个集中的数据平台。训练和服务 ML 模型和其他数据科学服务是在一个团队一个团队的基础上运行的,几乎没有协调。我们的一些痛点包括低效的特征工程、缓慢的指标监控和警报、缺乏复杂的数据可视化等等。这种低效率不仅浪费了我们的工程资源,而且还成为我们扩展工作的一大瓶颈。
Eats 数据平台架构
数据平台负责从头到尾管理数据处理流程的生命周期。典型的数据处理生命周期由以下阶段组成:
- 数据摄取是 第一阶段,从各种来源获取数据。为保证后续阶段数据流畅,在此阶段对数据进行优先排序和分类。
- 数据预处理包括填充空值、运行标准格式、检查数据质量、过滤数据等。预处理的主要目的是为数据科学和机器学习任务准备数据。
- 数据处理涉及根据复杂数据分析的需要将原始数据转换为所需的输出类型。此阶段还包括将数据下沉到适当的数据存储。
- 数据利用正在从处理过的数据中生成分析。在最后阶段,数据值被收集并输入到广泛的 DaaS 中,以帮助智能地解决业务问题。
Eats 数据平台遵循上述四个步骤,您可以在图 1 中看到其详细架构。该平台是一个一站式系统,可以高效地支持我们所有的数据处理需求。业务分析师 (BA)、数据工程师和数据科学家都使用我们灵活的平台作为集成系统,满足他们所有不同的数据需求。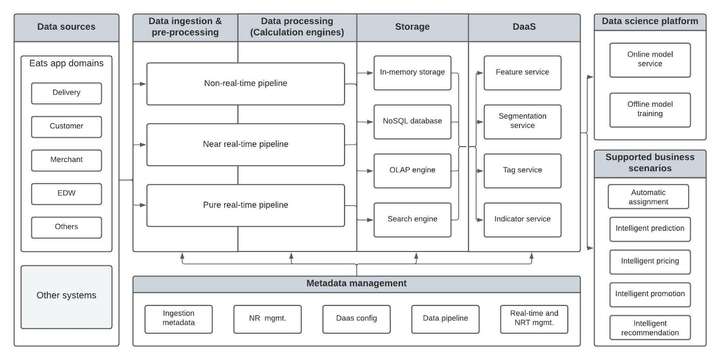
数据处理管道
食品配送是一项复杂的业务,因为它是一个由客户、Eats 配送合作伙伴 (EDP) 和商家组成的三方市场,需要许多实时计算。例如,将订单分配给交付合作伙伴必须在几秒钟内完成,才能以最快的速度交付给客户。但是,其他任务,例如针对有针对性的广告对用户进行细分,对时间不敏感,并且不必实时执行。
我们的数据平台旨在适应具有如此不同时间要求的任务。在本节中,我们将更详细地关注我们数据平台的数据处理管道。计算引擎负责非实时、近实时和实时的数据处理。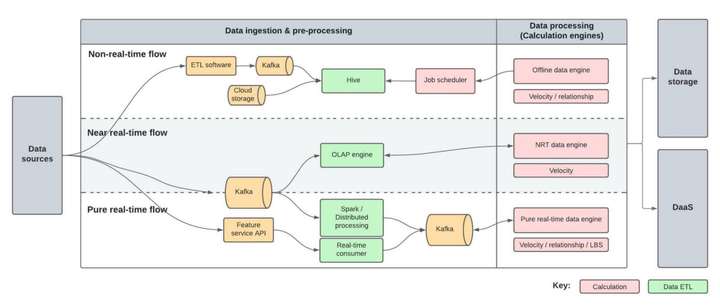
非实时
- 时间效率:至少1小时
非实时管道使用作业调度程序以批处理模式运行。该管道支持与机器学习相关的特征生产、用户分析和标签生成以及数据可视化。
在开发我们的数据平台之前,非实时管道的最大痛点是将离线功能和信号推送到在线存储。上传处理过的大量批处理数据集对我们的系统来说是缓慢、低效且成本高昂的。
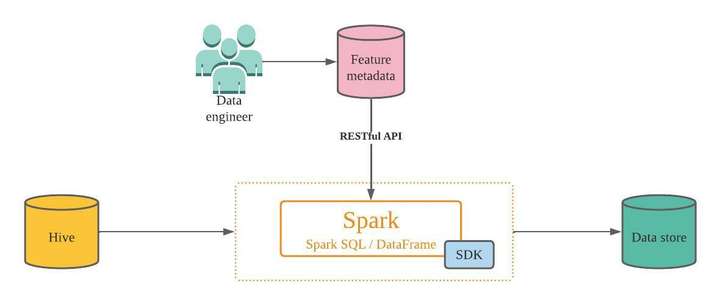
为了解决这个痛点,我们开发了一个配置驱动的管道来加速这个过程。借助配置驱动的方法,工程师可以简单地定义新配置以添加新数据源,从而使流程变得简单且无需手动操作。事实上,它只需要下面定义的三个简单步骤。
- 在我们的元数据管理系统中定义数据同步信息。我们甚至可以定义一个完整的特性组,其中可以包含许多针对特定业务场景的预定义特性以及特性与Hive表列之间的映射关系。
- 提供一个通用的Spark SDK,它将根据元数据和映射的预定义配置读取 Hive 数据并将特征同步到在线特征存储。
- 在作业调度器中创建一个 Spark 作业,并参考 SDK 将数据自动同步到我们的在线存储。
近实时 (NRT)
- 时间效率:≥30秒
尽管各种应用程序都支持实时数据流,但它对数据基础架构的负载很重,并且需要很高的技术专业知识进行配置。实时数据流还缺乏支持不断变化的业务需求的灵活性。
由于这些缺点,我们设计了一个利用高性能 OLAP 引擎的近实时 (NRT) 管道。NRT 管道可以通过执行 SQL 脚本的计划作业生成接近实时的信号。NRT 管道支持用于 ML 预测的实时特征生成、实时用户标签构建以及实时业务指标仪表板和警报。
NRT 引擎是配置驱动的通用管道,与非实时管道类似。该代码可以通过 SQL 支持各种类型的业务,SQL 是一种数据工程师、数据科学家和 BA 熟悉的语言。自从为 NRT 流水线服务半年多以来,我们的特征制作效率显着提高。
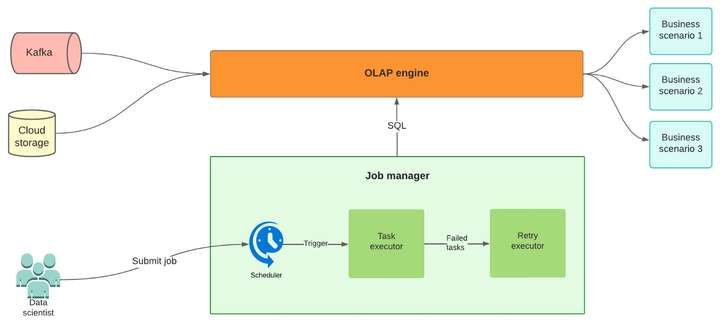
以下是我们的内部用户使用 NRT 管道的方式:
- 将上游Kafka消息摄取到 OLAP 引擎或读取云存储中的 Hive 表数据。
- 以预定的时间间隔(30 秒到 1 小时)执行 OLAP 引擎 SQL。在此步骤中,通过连接从 Kafka 或云存储中提取的多个表源来创建宽表,这两个表源都存储实时数据。
- 使用上一步生成的宽表,数据科学家创建计划的 OLAP 引擎 SQL 作业以生成近乎实时的指标和信号。
- 作业调度程序将按照定义的时间间隔执行 SQL,并将生成的信号发送到 Kafka 以供下游作业使用或写入数据存储。
纯实时
- 时间效率:<1秒
NRT 管道可以覆盖我们生产中约 80% 的实时功能用例。但是,它无法支持洪水检测和风险控制等非常高效率和低延迟的场景。
此类紧急任务依赖于纯实时数据。但是,纯实时管道使用 Spark 和另一个分布式处理引擎。考虑到大多数数据用户不熟悉编写 Spark 流代码,期望他们能够持续为实时数据任务编写按需代码是不切实际的。
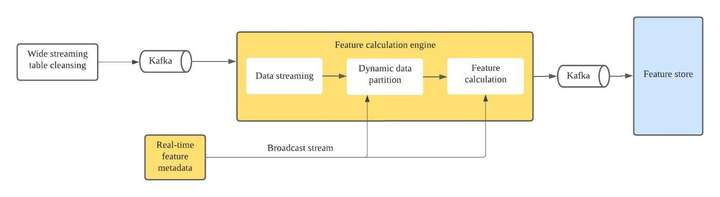
同样,我们开发了一个配置驱动的管道,可以很容易地被所有用户用于实时数据处理。下面是对其过程的描述。
- 将必要的数据提取到 Kafka 主题中。
- 根据实时特征元配置,通过广播系统将事件数据动态划分给不同的下游运营商。
- 根据特征元数据的定义,计算基于不同预实现聚合器的实时特征值。立即或定期将计算值输出到 Kafka 或下游操作员。
纯实时流水线目前支持SUM、COUNT、UNIQUE COUNT、TOPN等十种左右常用的统计函数。此外,管道支持多维统计功能。使用这种纯实时管道,我们可以以无代码方式定义数据流。这大大降低了计算实时特征的成本并提高了我们的效率。
结论
我们检查了 Eats 数据平台的整体架构及其数据处理管道。由于我们的业务需求在时间敏感性方面不同,我们为非实时、近实时和纯实时数据需求设置了三个管道。这些数据管道都是为配置驱动而构建的,即使是代码经验最少的用户也可以无缝地使用它。