数据仓库有很多定义,现在最重要的两个是:
- Ralph Kimball对数据仓库的定义
数据仓库是专门为查询和分析而构建的事务数据的副本。
- Bill Inmon对数据仓库的定义
数据仓库是一个存储库(数据和元数据),其中包含来自不同来源的集成、清理和协调的数据,用于决策支持应用程序,重点是在线分析处理。通常,数据是多维的、历史的、非易失性的。
哪个更好?直到今天,我们也不知道哪种方法更好,似乎两者都一样好。
维度建模
维度建模是在数据仓库中组织数据的方法。
维度建模中最重要的一步是识别事实和维度。
- 事实是公司的关键衡量标准,通常可以汇总(总收入、销售的产品数量、日期、产品 ID、客户 ID)
- 维度对事实进行分类,支持对数据进行分组或过滤(产品名称、产品品牌、客户名称、客户国家/地区)
让我们看一下下面的示例销售表:
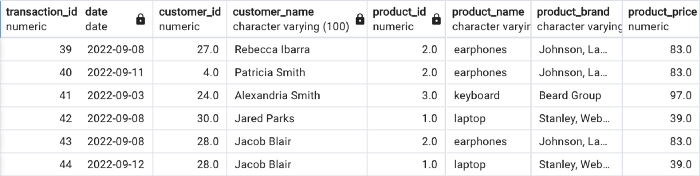
问题
您如何将此表划分为事实和维度?
解决方案
1、事实:
- transaction_id
- 日期
- 客户ID
- product_id
- 产品价格
2、维度:
- 顾客姓名
- 产品名称
- 产品品牌
但我们为什么要这样做?答案很简单——避免数据冗余。
让我举例说明一下,所以我们还是有一小部分sales 表。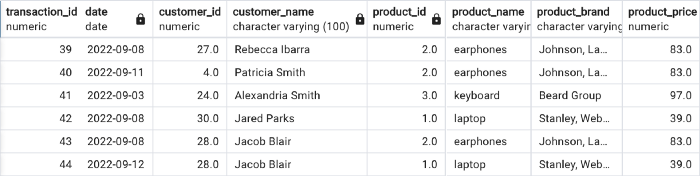
让我们关注列customer_name — 客户 Jacob Blair 有两笔交易 — 他购买了笔记本电脑和耳机。每当客户进行交易时,将客户名称存储在销售表中是非常低效的,不是吗?创建名为customerDim的维度并将所有分类客户数据保存在此处可能会更好。完成后,可以轻松地从销售表中删除列customer_name 。
这就是它现在的样子:
但我们可以做得更好。现在让我们关注列product_name - 其中有重复的值。我们可以看到,耳机往往出现 3 次,笔记本电脑出现 2 次。
再一次——将它存储在 sales 表中效率极低,我们该怎么办?
在我们做任何事情之前,请查看product_brand 列,其中也包含重复项。
由于product_name和product_brand属于描述产品的相同分类特征,我们将它们分组到一个表中,即下一个维度!让我们称它为productDim。现在可以轻松地从销售表中删除列product_name和product_brand 。
快速浏览我们的数据表: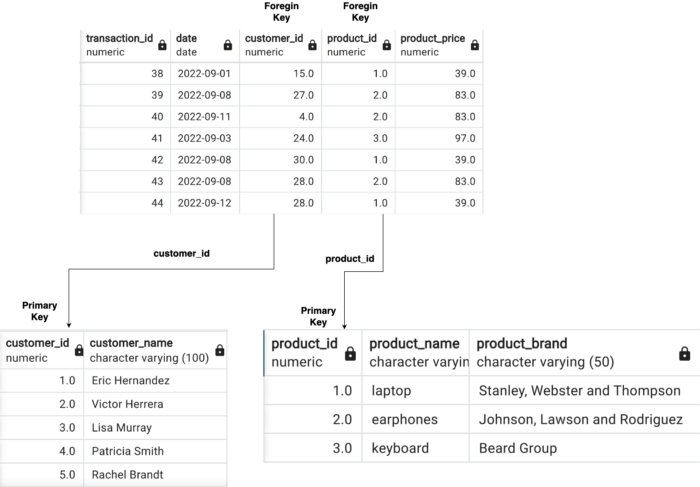
上面实现的模式称为星型模式(一个或多个事实表引用任意数量的维度表),它是雪花模式的特例。
概括
正如你所看到的,维度建模是直观的,当然我上面提出的问题很简单,但在我看来它完美地反映了本质。