Apache Spark 是领先的开源数据处理引擎,用于批处理、机器学习、流处理和大规模 SQL(结构化查询语言)。它旨在使大数据处理更快、更容易。自诞生以来,Spark 作为一个大数据处理框架获得了极大的普及,并被处理大量数据的不同行业和企业广泛使用。
这篇文章将展示可行的解决方案,通过优化 Spark 作业来最大限度地减少计算时间,而无需搜索互联网或其他知识来源。
该策略列出了不同的运行阶段,其中每个运行阶段都建立在前一个运行阶段的基础上,并通过做出新的增强和建议来改进计算时间。
我们的用例是一个复杂的信用风险资本计算器。挑战在于以更高的性能和更低的成本在极高的数据量上执行这种计算。这里提出的建议适用于 YARN 和 HDFS 集群,但也可以应用于其他基础设施。
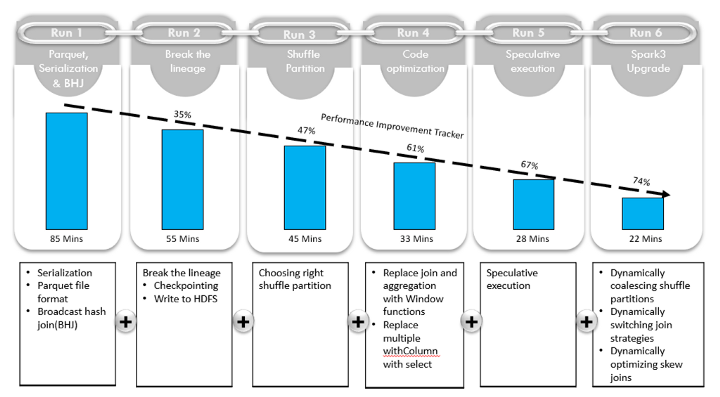
我们首先概述描述各个运行阶段和每个阶段改进的运行时间,如上所示。前五次运行在 Spark 2.4 上进行,最后一次运行在 Spark 3.1 上。
运行 1 的注意事项:序列化、Parquet 文件格式和广播
1)序列化:序列化有助于将对象转换为字节流,反之亦然。当我们进行任何类型的计算时,我们的数据都会转换为字节并通过网络传输。如果我们通过网络传输的数据较少,则执行作业所需的时间会相应减少。Spark 提供两种类型的序列化,Java 和 Kryo。
Java 序列化
- 默认提供,可以与任何扩展 java.io.Serializable 的类一起使用
- 灵活但速度很慢,并导致许多类的大型序列化格式
Kryo 序列化
- 与 Java 序列化相比更快更紧凑
- 需要提前注册课程以获得最佳性能
2) Parquet 文件格式: Apache Parquet 是一种开源的、面向列的数据文件格式,专为高效的数据存储和检索而设计。它提供了高效的数据压缩和编码方案,具有增强的性能,可以批量处理复杂的数据。
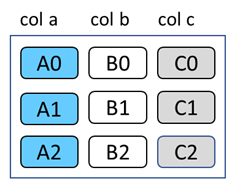

面向行的存储

面向列的存储
列式格式在文件大小和查询性能方面都很有吸引力。文件大小通常小于面向行的等效文件,因为一列中的值彼此相邻存储。此外,查询性能更好,因为查询引擎可以跳过不需要的列。
3)广播:连接两个表是Spark中的常规操作。通常,执行节点之间通过网络交换大量数据。这种交换可能会导致网络延迟。Spark 提供了几种连接策略来优化此操作。其中之一是广播哈希连接。如果其中一张表足够小(默认为 10MB,但可以达到 40MB),较小的表可以广播到集群中的每个 executor,并且可以避免 shuffle 操作。
Broadcast Hash Join 分两个阶段进行,Broadcast 和 Hash Join。
- 广播阶段:将小数据集广播给所有执行者
- Hash Join 阶段:小数据集在所有执行器中进行哈希处理,并与分区的大数据集连接
以下是关于广播的一些注意事项:
- 广播关系应该完全适合每个执行程序的内存以及驱动程序,因为后者启动数据传输。
- 当广播数据的大小很大时,你会得到 OutOfMemory 异常。
- 广播仅适用于 equi('=') 连接。
- 广播适用于所有连接类型(内、左、右),完全外连接除外。
- 当其中一个连接关系的大小小于阈值(默认为 10 MB)时,Spark 会部署此连接策略。定义此阈值的 Spark 属性是 spark.sql.autoBroadcastJoinThreshold(configurable)。
运行 1 需要 85 分钟才能完成。
运行 2 的注意事项:打破Lineage血统
在我们的用例中,我们有复杂的计算,其中涉及对大量数据执行的迭代和递归算法。每次我们在 DataFrame 上应用转换时,查询计划都会增长。当这个查询计划变得庞大时,性能会急剧下降,从而导致瓶颈。
不建议在沿袭中链接大量转换,尤其是当您需要以最少的资源处理大量数据时。因此,最好是打破血统。
下面是一个带有转换和动作的计算示例。为了加快性能并简化处理,我们在步骤 E 打破了血统。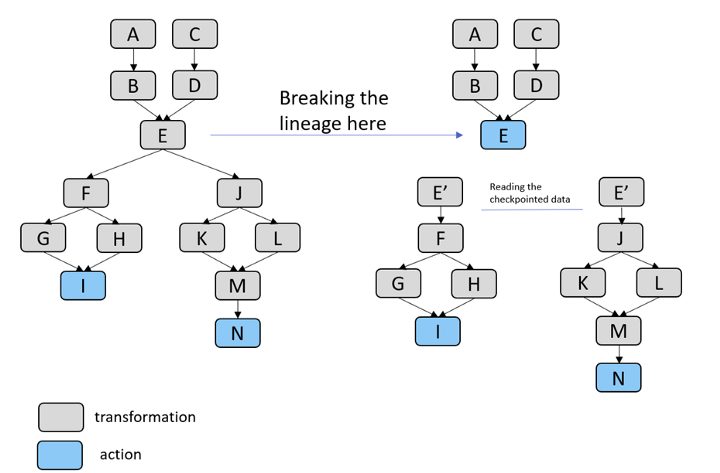
我们测试了以下三种方法来打破血统:
检查点:检查点是截断执行计划并将其保存到可靠分布式(HDFS)或本地文件系统的过程。这是 Spark 的一个特性,对高度迭代的数据算法特别有用。检查点文件可用于后续作业运行或驱动程序。
根据检查点操作符的 Eager 标志,检查点可以是急切的或懒惰的。前者是默认设置,在请求时立即发生,而后者仅在执行操作时发生。开发者可以使用这个语法:val brokenLineageDf = existingDf.checkpoint()
本地检查点:这类似于检查点,但数据不会传输到 HDFS,而是保存到执行程序的本地文件系统。如果执行器在处理过程中被杀死,数据将丢失,Spark 将无法从 DAG(有向无环图)重新创建此 DataFrame。开发者可以使用这个语法:val brokenLineageDf = existingDf.localCheckpoint()
以 parquet 方式将数据写入 HDFS:当我们检查点 RDD/DataFrame 时,会将其序列化并存储在 HDFS 中。它不以 parquet 格式存储,parquet 提供高效的数据存储。
通过在 parquet 中写入 HDFS 来打破血统,为我们提供了上述三个方面的最佳性能。
打破血统后,Run 2 用时 55 分 36 秒, 与 Run 1 的 85 分钟时间相比有了明显改善。
还需要注意的是,缓存提供了一种在不破坏血统的情况下提高性能的替代方法。两者之间的区别,以及何时使用其中一个,可以在这里阅读。
运行 3 的注意事项:右随机分区
选择正确的 shuffle 分区号有助于提高作业性能。分区决定了作业中的并行度,因为任务和分区之间存在一对一的关联(每个任务处理一个分区)。
每个分区的理想大小约为 100–200MB。较小的分区会增加并行运行的作业数量,可以提高性能,但分区太小会导致开销并增加 GC 时间。更大的分区会减少并行运行的作业数量,也会让一些核心空闲,这会增加处理时间。
在洗牌的情况下,如何选择正确数量的洗牌分区(spark.sql.shuffle.partitions)?
我们遵循以下 Spark 建议并将其付诸实践:
- 如果中间数据太大,那么我们应该增加shuffle partitions,使partitions更小。
- 如果作业运行期间内核空闲,增加随机分区有助于提高作业性能。
- 如果中间分区很小(以 KB 为单位),那么减少 shuffle 分区会有所帮助
- 对于大容量的集群,分区数应该是核心数的 1 倍到 4 倍,以获得优化的性能。例如,对于 40GB 和 200 个核心的数据,将 shuffle 分区设置为 200 或 400。
- 对于容量有限的集群,可以将随机分区设置为输入数据大小/分区大小(每个分区 100-200MB)。最好的情况是将随机分区设置为核心数量的倍数,以实现最大并行度,具体取决于集群容量。例如: - 对于具有 6 个核心的 1 GB 数据(执行器核心 3,最大执行器 2)。理想的 shuffle 分区可以是 12 个(核心数的 2 倍),分区大小为 100MB。 - 对于 40 核的 20 GB 数据,将随机分区设置为 120 或 160(核的 3 倍到 4 倍),分区大小为 200MB)。
我们使用正确的 shuffle 分区运行我们的工作,完成时间为 45 分 39 秒。
运行 4 的注意事项:代码优化
对于这次运行,我们专注于在代码级别进行两项更改。
1. 用窗口函数替换连接和聚合:在我们的大多数计算中,我们必须对指定的列执行聚合。结果将存储为新列。在这种情况下,此操作由聚合和连接组成。
这里更优化的选项是使用窗口函数。通过在我们的代码中用 Window 函数替换我们的连接和聚合,我们发现了显着的改进。
可以在此处找到这两种方法的简单基准和 DAG 表示。
2. 将 withColumn 替换为 Select:对 DataFrame 的每个操作都会产生一个新的 DataFrame。在需要反复调用 withColumn 的情况下,最好使用单个 DataFrame。
不使用:
而是使用:
当我们使用带有多个 windowSpec 的 withColumn 时,DAG 还会创建不必要的随机播放:
当我们使用带有多个 windowSpec 的 withColumn 时,DAG 还会创建不必要的随机播放:
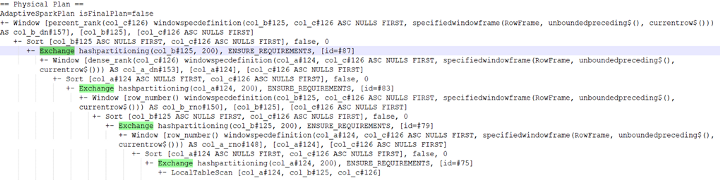
使用Select:
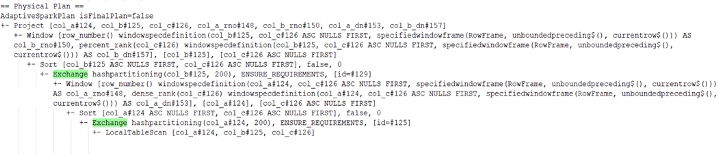
从上面的执行计划可以看出,使用 Select 是更好的选择。
运行 4 只用了 33 分 53 秒即可完成。
运行 5 的注意事项:推测执行
由于网络慢等环境问题,Apache Spark 具有推测执行功能来处理阶段中的慢任务。如果一个任务在一个阶段运行缓慢,Spark 驱动程序可以在不同的主机上为它启动一个推测任务。在常规任务和它的推测任务之间,Spark 系统会从第一个成功完成的任务中获取结果并杀死较慢的任务。
对于长时间运行的作业(其中一些任务比其他任务慢)——这可以通过监控 Spark UI 所花费的时间来识别,启用推测会有所帮助。
如果 spark.speculation 设置为 true,则根据其他任务的完成时间计算出的中值来识别运行缓慢的任务。在识别出运行缓慢的作业后,在其他节点上启动推测任务以完成作业。
启用推测导致运行 5 仅需 28 分 19 秒即可完成。
运行 6 的注意事项:启用 AQE(自适应查询执行)
对于这次运行,我们启用了 AQE,这是 Spark 3.0 的主要功能。可以通过将 SQL配置 spark.sql.adaptive.enabled设置为 true 来启用 AQE(false 是 Spark 3.0 中的默认值)。
在 Spark 3.0 中,AQE 框架具有三个特性:
1)动态合并 shuffle 分区简化甚至避免了调整 shuffle 分区的数量。用户可以在开始时设置比较多的shuffle partition,然后AQE可以在运行时将相邻的小partition合并成更大的partition。 (设置spark.sql.adaptive.coalescePartitions.enabled=true)
2)动态切换连接策略部分 避免了由于缺少统计数据和/或大小错误估计而导致的次优计划。这种自适应优化会在运行时自动将排序合并连接转换为广播哈希连接,进一步简化调整并提高性能。 (设置spark.sql.adaptive.localShuffleReader.enabled=true)
3)动态优化倾斜连接是另一个关键的性能增强,因为倾斜连接会导致工作极度不平衡并严重降低性能。在 AQE 从 shuffle 文件统计信息中检测到任何倾斜后,它可以将倾斜分区拆分为较小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理并实现更好的整体性能。 (设置spark.sql.adaptive.skewJoin.enabled=true)
升级到 Spark 3.0(在此处阅读其最新功能列表)并启用 AQE 功能后,我们的工作需要 22 分 37 秒才能完成。
结论
本文解释了在涉及复杂计算的环境中为 Spark 优化部署的各种策略。
从使用序列化、parquet 文件格式和广播的标准 Spark 方法构建到打破沿袭,使我们能够显着减少作业时间的执行。
然后,我们通过使用正确的 shuffle 分区对此进行了改进,并优化了我们的代码,并利用推测执行进一步提高了性能。
最后,我们部署了一个更新版本的 Spark,它使我们能够使用 AQE 功能(在 Spark 2.x 中不可用),这进一步减少了执行时间。
我希望本文对您的 Spark 优化之旅有所帮助,在此过程中,上述策略的组合可以在资源有限的情况下提供最佳性能。毕竟,它使我们的性能提高了 70% 以上。从 85 分钟缩短到 22 分 37 秒。