让我们更深入地讨论在 Postgres 之上潜在的基于轮询的实现。
假设我们将使用的表结构:
CREATE TABLE publications( |
我们将存储要在此处发布的消息,然后使用以下查询在后台进程中不断轮询这些消息:
SELECT |
最后处理的位置将从订阅表中获取:
CREATE TABLE subscribers |
在处理完读取批次中的所有消息后,我们会更新特定订阅者的最后处理位置。到目前为止,一切都很好,很容易。
我们使用BIGSERIAL类型来生成单调、自动递增的位置。三个并行事务的快乐路径如下所示:
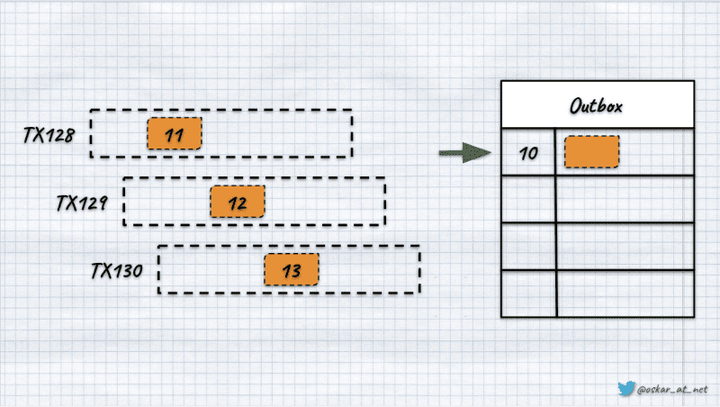
提交事务后,结果应如下所示:
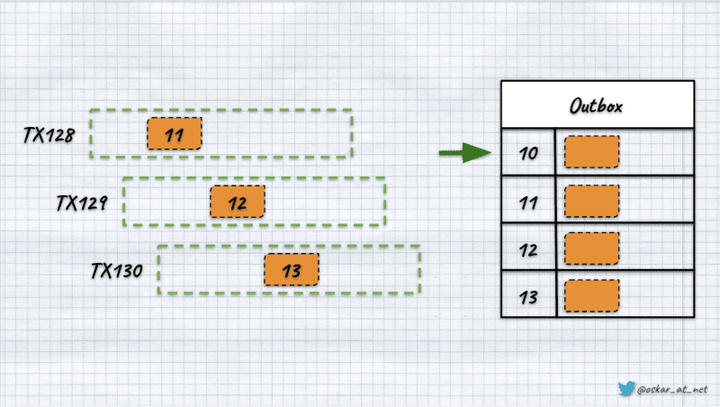
然而,由于我正在写这篇文章,你可以猜到这里可能有些奇怪。如果最后一个事务是最快的并且作为第一个事务提交怎么办。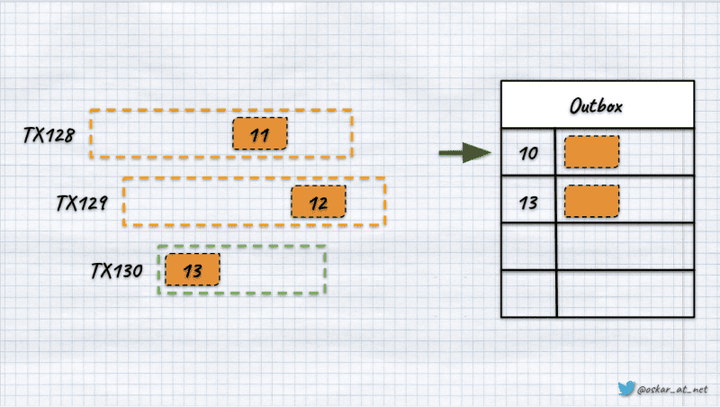
如果其余的都按照顺序,我们会看到将记录附加到表的顺序可能与位置的顺序不同。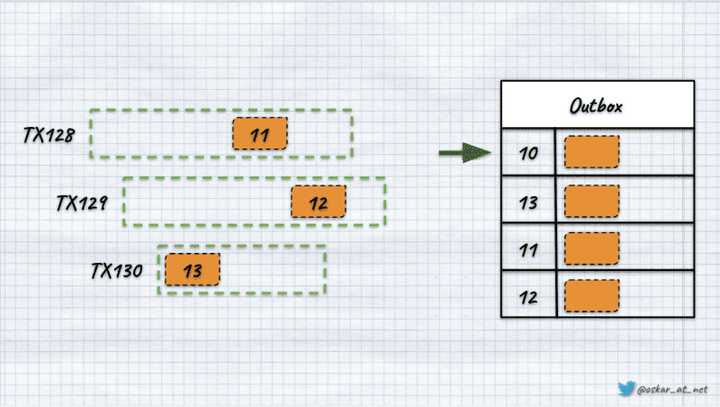
这是可能的,因为Postgres 序列的工作方式。在事务提交之前对它们进行评估。_“但我们在这里使用的是 BIGSERIAL!”。没关系。BIGSERIAL 只是自动生成的 Postgres 序列的语法糖。它只是在幕后使用它。
另一个重要的事情是序列的数量没有被重用。这是避免交易之间发生意外数字冲突的有效方法。如果事务失败并回滚,该号码将丢失。在我们的例子中,这可能会导致位置编号出现空白。
所以现在,我们有两个问题:
- 我们可能有乱序的消息,
- 我们可能在顺序方面存在差距。
我已经写过位置对于 Event Stores 非常重要。然而,即使使用发件箱来广播消息也可能会产生严重的后果。
让我们回到竞争条件示例。
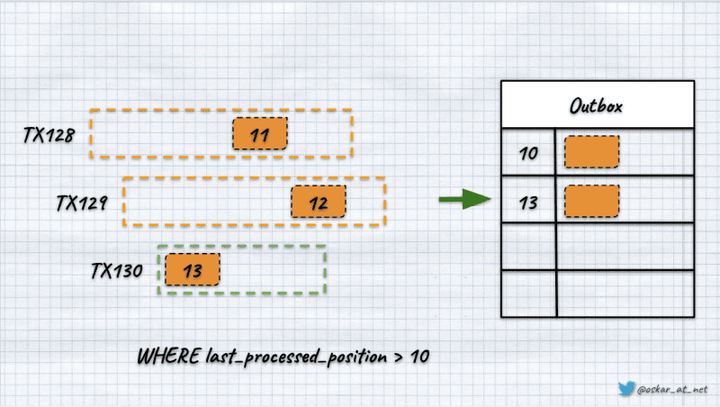
如果第 3 个事务最快,我们尝试通过第 1 个和第 2 个提交之前最后处理的位置进行查询,那么我们将不知道该间隙是由某些事务回滚还是竞争条件引起的。如果我们乐观地假设这些间隙是由回滚引起的,我们可能会丢失消息。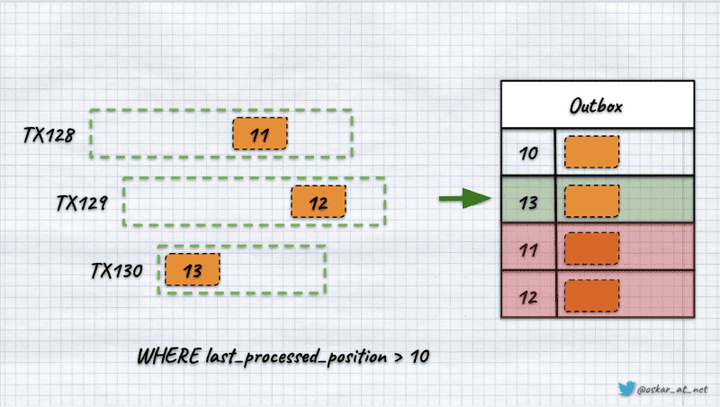
我们将使用新读取的最大值 (13) 更新位置,然后以下查询将使用它,跳过之后添加的记录(11 和 12)。
我们可以解决排序问题,但对于大多数系统来说,丢失消息是不行的。
我们能做什么?
首先是核武器选项。Laurenz Albe 在他的文章中很好地介绍了它。我们可以在“单例表”中手动生成无间隙数字。W 可以这样做:
我们能做什么?
首先是核武器选项。Laurenz Albe 在他的文章中很好地介绍了它。我们可以在“单例表”中手动生成无间隙数字。W 可以这样做:
CREATE TABLE seq (id bigint NOT NULL); |
只有当事务成功时,它才会更新表中的数字。为什么它是一个核武器选项?因为它锁定了整个seq表,使得调用这个函数的所有处理都是顺序的。这对于低吞吐量但高重要性数字可能很好,但不适用于像发件箱这样将成为通信骨干的机制。相信我,我试过了,性能下降是沟通的主干太大而无法接受。
下一个选项是像 Marten 一样进行间隙检测。如果我们通过稍等片刻来延迟消息发布,我们可以尝试假设间隙来自回滚事务。如果我们发现这样,我们可以附加“墓碑事件”,将间隙标记为已检查并锁定。一旦我们用此类事件填补了所有漏洞,我们就可以继续处理。在 Marten 中,它被称为High Water Mark。这是守护进程“知道”的最远已知事件序列,所有具有该序列或更低序列的事件都可以通过投影按顺序安全地处理。如果检测到事件序列中的未完成间隙,则高水位线通常会稍微落后于已知的最高事件序列号。
然而,编写这样的间隙检测机制并非易事。Jeremy 在 Event Sourcing Live 的演讲中解释了一些挑战。
如果我们能忍受这些差距呢?我说我们不应该,所以我在做一些绝地思维技巧吗?这就是我们提出最后一个想法的方式。有个窍门……
Postgres 具有向我们返回有关当前活动事务的信息的机制。我们可以通过调用pg_current_snapshot函数来获取这些信息。一旦我们有了它,我们就可以调用另一个函数pg_snapshot_xmin的结果,它选择最小的事务 id。
因此,如果调用pg_snapshot_xmin(pg_current_snapshot()),我们将有效地获得最小活动事务 ID。在 Postgres 中,事务是单调的、无间隙的数字,在整个集群生命周期中是唯一的。我们可以用它来满足我们的需要。我们可以在我们的发件箱表中添加一个事务 id 列,并用我们要向其附加消息的事务 id 填充它。
ALTER TABLE outbox |
我们使用xid8类型,一种 64 位的序列号类型,用于表示交易 ID。有了这个,我们可以改变我们的查询来使用它:
SELECT |
多亏了这一点,我们不会得到“Usain Bolts”,因此来自事务的消息比更早开始的事务更快。
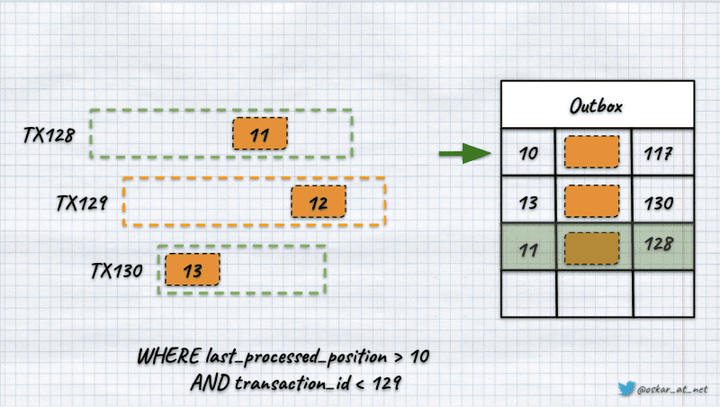
如果我们有类似上图中的场景,因为我们正在进行事务 129,那么通过我们的查询,我们将获得记录 11,因为它是在第 128 号事务中添加的。我们不会获得位置 13 的记录,因为它是由晚于正在进行的交易开始的交易添加的。
这是一个比以前的 nuke 选项更好的选择,因为我们在添加新消息时不会对性能造成影响(除了使用更多数据)。如果我们的交易持续很长时间,我们的查询可能会有点延迟,所以我们应该确保它们得到快速处理。然而,这是我们应该永远努力的事情。
总而言之,一如既往,魔鬼在于细节。好的和有用的模式并不总是很容易实现。我们应该始终确保我们预先定义了我们的预期保证并且它们是匹配的。但是,嘿,这不是我们得到报酬的原因吗?