Mastodon与Twitter相似:可以发布toots(短消息),这些消息对我们的追随者可见;我们可以提升(转发)帖子或收藏(喜欢)它们。
显著的区别:
Twitter是一个集中的平台,Mastodon有许多独立的实例。
每个Mastodon实例都是一个小型的Twitter,有自己的用户群、管理员和审核规则。
这些实例不是孤立的:它们相互沟通和交换数据,形成一个联合网络。
正因为如此,你可以很容易地从另一个实例中关注一个人,并在你的feed中看到他们的帖子。
从IT的角度来看,让我们高瞻远瞩地看看一个单一的Mastodon实例的架构,以及不同的实例如何通信。具体来说,我们将看看Mastodon的实例网络是如何扩展的。
单个Mastodon实例的组件
Mastodon的核心是一个使用Ruby on Rails编写的应用程序:Twitter使用的也是这种语言和框架,后来由于可扩展性问题,被Scala和一些自定义库取代。这是一个单体--你不会在这里看到任何微服务--但是,单体也可以很成功--你上次访问StackOverflow是什么时候?
事实的主要来源是一个PostgreSQL数据库(我把它缩写为PG)。这是你最不应该备份的。丢失PG数据意味着从一个没有用户或帖子的新实例开始。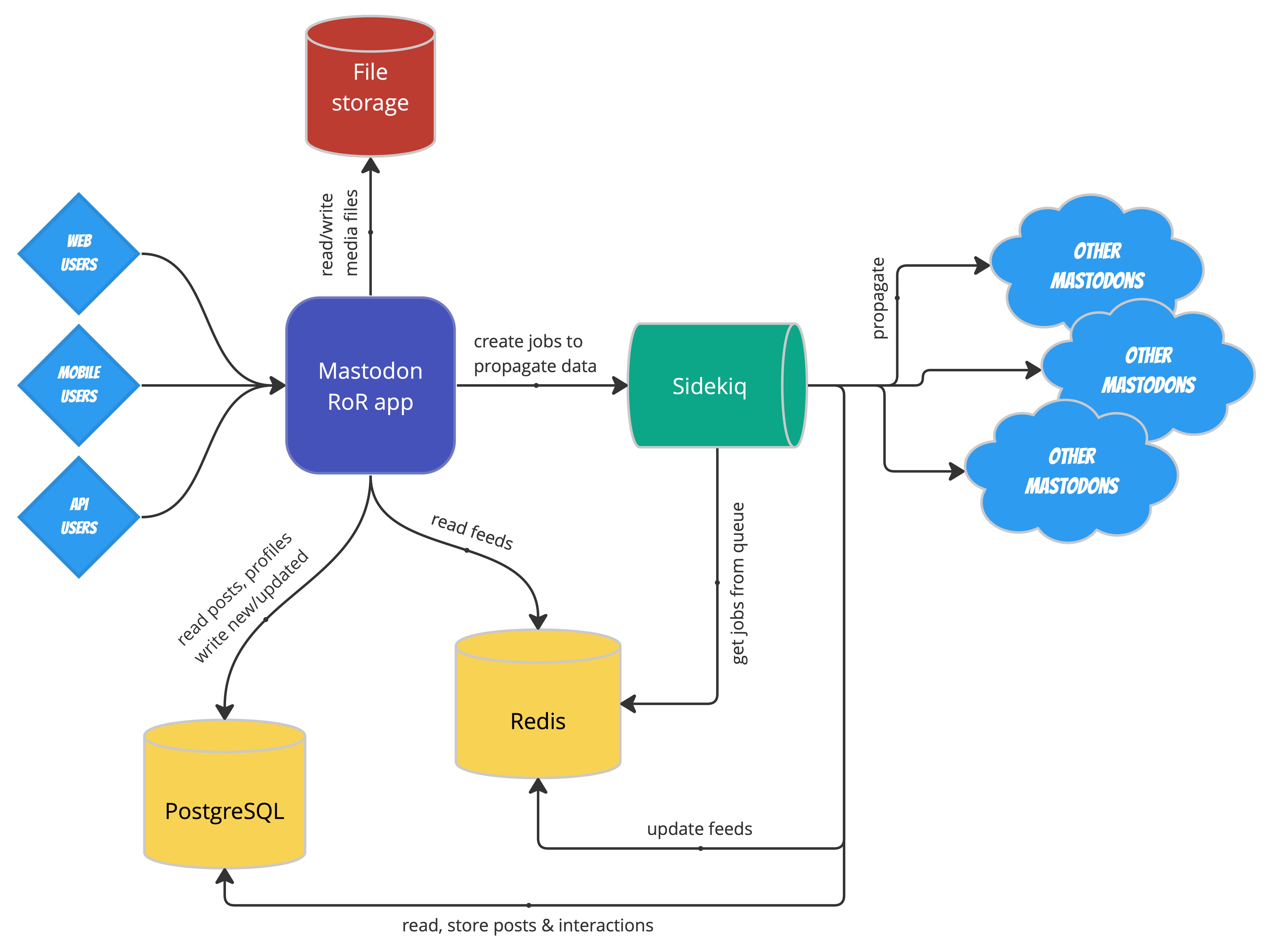
第二个关键组件是Redis服务器(一个内存数据库)。它有两个作用:作为缓存和作为Mastodon工作系统的数据存储。作业系统做了大部分有趣的工作,由Sidekiq驱动。Sidekiq宣传自己是Ruby最快的作业系统,考虑到大型Mastodon实例可以创建的作业数量,它当然有机会证明自己的价值。
可选的是,ElasticSearch可以用来索引和搜索你撰写的、被赞的或被提及的帖子。
最后,还有文件存储(个人资料图片,以及附加在帖子上的媒体),它可以是本地的(存储在文件系统上),也可以委托给S3。当涉及到耐用性和备份时,这应该是一个简单的选择!
数据流:创建一个新的帖子
当你在Mastodon上创建一个帖子时,它将被存储在PostgreSQL数据库中。此外,它还会被添加到你的本地关注者的主页上,也就是你打开Mastodon应用程序时看到的内容。
主页的内容被存储在Redis中。在这里,Redis被用作缓存(home feeds可以使用tootctlbuild重新计算,因此这些数据不需要持久化)。因为Redis在内存中存储数据,所以获得主页的速度非常快。但由于内存不是无限的,在一个可配置的时间段后(默认为一周),没有登录过的用户的主页信息将从缓存中删除。
但本地追随者只是故事的一半;你可能在其他服务器上也会有一些非本地追随者。为了在那里传播你的帖子,需要创建一个Sidekiq作业。这又是Redis的用武之地,特别是它的队列功能。传播帖子的作业会被放到你有粉丝的每台服务器的推送队列中。执行时,该作业将执行适当的HTTP调用。
在另一个Mastodon实例中,当收到一个请求时,一个在本地创建帖子副本的工作将被放到入口队列中。在执行时,将在PostgreSQL数据库和Redis主页中进行适当的修改。
因此,创建一个帖子意味着一个本地数据库的变化,加上尽可能多的网络调用,因为在你的追随者中有不同的服务器。
数据流:回复、提升和收藏
每次有人通过创建回复、提升(转发)或收藏(喜欢)与你的帖子互动,这都需要传播到其他服务器(你的关注者所在的地方)。
如果互动本身发生在另一个服务器上,而不是最初创建帖子的地方,我们首先需要通知原服务器,然后才执行传播。
假设你写了一篇文章,而你的粉丝分布在50个服务器上。因此,在始发服务器上创建了50个Sidekiq作业。现在,如果有人回复帖子,我们就有1个Sidekiq作业将其传播到原始服务器(如果需要),然后再有50个。如果你有10个回复,那就有超过500个工作。
扩大Mastodon实例的规模
如果你的实例变得流行(或者如果你正在运行mastodon.social、fosstodon.org或mas.to),你可能想扩大规模以处理负载。你有什么选择?(当然,第一件事是识别瓶颈,但我们假设你已经做了这个)。
有三个组件可以进行扩展:
第一个也是最明显的一个是PostgreSQL数据库。虽然你不能扩展写的路径(除了PG服务器本身的垂直扩展),但你可以通过提供热读副本来扩展读的路径(在许多Web应用程序中,这是更频繁的路径)。但是请注意,Sidekiq作业需要从主节点执行读和写,因此扩展的服务器只是为了其他客户(网络、移动、流媒体)。
第二个组件是Redis内存数据库。在这里,我们可以创建单独的实例来支持Sidekiq作业,并且需要是持久性的(这样我们就不会丢失,或者至少在服务器之间传播帖子和互动的作业在发生故障时损失最小)。另一方面,Redis实例是用来缓存主页的,可以是不稳定的,不需要持久化。
Redis本身可以使用Redis Sentinel或Redis Cluster进行扩展。对于Sidekiq来说,只有Sentinel选项是可行的,因为Sidekiq使用少量频繁更新的键。使用Sentinel,我们可以获得故障转移,但我们不会增加服务器的吞吐量。对于首页的缓存,我们可以使用Redis Cluster,它将把许多缓存的键分布在可用的节点上。
最后,我们还有文件存储。但在这里,如果我们想扩展,让我们直接转移到S3,把问题委托给别人。
到目前为止,我们已经涵盖了大部分关于横向扩展的选项。然而,Mastodon应用程序和它本身使用的中间件有很多微调。例如,Sidekiq有一个可配置的线程数量,用于处理队列中的作业。在某些情况下,创建专门的Sidekiq进程是有意义的,每个进程优先处理来自某个队列的作业。当然,PostgreSQL也提供了相当多的调整参数。
扩大联合网络的规模
我们可以扩展一个单一的Mastodon实例:主要是纵向的,通过给Redis实例添加更多的RAM,这样可以缓存更多用户的信息。或者通过给PostgreSQL实例添加更多的RAM,这样就可以在内存中处理更多的查询。还有一些横向扩展的选择,比如添加更多的网络服务器或添加热流PostgreSQL复制。
但在某些时候,我们会遇到一个极限,即单个服务器不能再扩展了。这就是mastodon.social的情况--它不再接受新用户了。那该怎么办呢?
Mastodon有一个答案:联盟federation:
它不是一个集中的网络,相反,负载可以分散到多个Mastodon实例上。每个实例本身就是一个小世界。实例的本地流量越多越好。
然而,一旦我们得到越来越多的节点间关系,这种联合的解决方案可能会遇到问题。那就是当一个实例的人开始关注其他实例的人。在这种情况下,数据必须从一个服务器复制到另一个服务器。而这个流量会被互动的数量所乘。
由 "普通 "用户产生的流量,即拥有合理数量的追随者,并获得合理数量的互动,不是一个问题。但也有一些用户,他们获得了大量的追随者,他们的帖子引发了许多互动。让我们想象一下,一个拥有50万粉丝的人分布在,比方说,10k个服务器上。这样的人所发的每一个帖子都会产生10k个Sidekiq工作。每次互动--又是10k个Sidekiq工作。如果该帖子在短时间内受到欢迎并获得1千次收藏(相当于该人总粉丝数的1/500),我们就会讨论到10M个Sidekiq工作。而所有这些都需要由一台服务器来协调。
我们还没有看到事情在实践中折戟沉沙,但它以前已经造成了麻烦,所以我怀疑我们可能会看到更多这样的问题。一两个这样的名人可能不是问题。但推特上相对来说充满了拥有大量追随者的名人。目前的设计似乎还没有为这种负载做好准备。
所有的帖子最终会在mastodon.social上结束吗?
另一个问题是,与大型服务器,如mastodon.social。鉴于它聚集了一大群兴趣迥异的人(它是一个 "通用 "的Mastodon服务器,不为任何特定的社区服务),难道其他服务器的大部分帖子最终不会被复制到那里吗?只要有一个追随者,一个帖子就会被传播。
即使乐观地假设其他Mastodon实例将承载大部分独立的社区,其中大部分流量将在节点内进行,也只是将问题推到了未来。让我们假设1/10的帖子最终出现在最大的节点上。如果Mastodon成为Twitter的替代品,这仍然是一个巨大的数据量。
让我们开始吧!
Mastodon证明了一个事实,即你可以用传统的webapp走得很远。没有Kafka或Pulsar,Cassandra或Mongo,也不需要分布式共识或集群协调。然而,这样的设计可能会遇到它的极限。但是,这个应用程序现在表现得很好,联合网络也运作得很好。大量用户的涌入可能是一个很好的冲动,可以改善内容的传播方式,为名人用户提供更好的支持,并提高扩展性。
还有一些社会或用户体验的障碍需要解决。例如,人们是否愿意采取额外的步骤,选择一个实例,而不是 "直接加入 "并获得你感兴趣的帖子?艰难的选择可能会让人气馁还有一些长期未解决的技术问题,如回填新用户的信息。