分布式有状态流处理具有挑战性,尤其是在处理故障和恢复方面。在流处理中,最常被问到的问题之一是“我的流处理系统是否保证每条记录都被处理一次且仅一次,即使在处理过程中遇到一些故障?”
通过“ exactly-once(精确一次)”语义,我的意思是每个传入事件只影响最终结果一次。即使在机器或软件出现故障的情况下,也没有重复数据,也没有未处理的数据。
我们正在使用 Apache Flink,这是一种分布式流处理引擎,长期以来一直在Flink 应用程序本身中提供exactly-once 语义:
- Flink 以固定的、可配置的时间间隔生成检查点,然后将它们写入持久存储系统,并在输入流中附加位置。
- 在从故障中恢复期间,Flink 从最近成功完成的检查点恢复处理。
- Flink 的检查点算法基于Chandy 和 Lamport在 1985 年引入的技术绘制分布式系统当前状态的一致快照,不丢失信息,不记录重复项。
但是说“端到端”我的意思是将 exactly-once 语义扩展到涉及的外部系统:Flink 在处理后发送数据。想象一个非常标准和简单的过程,它使用来自 Kafka 主题的事件,执行 1 分钟的滚动窗口,一旦窗口过期,将所有事件写入数据库。因此,事件被分组到 1m 的桶中,并通过单个批量插入操作写入。

显然,理想情况是所有传入事件最终都会出现在数据库中,但只会出现一次。
幂等写入
如果应用程序写入具有关联的一致唯一标识符的记录,则可以通过写入数据库的幂等实现来实现恰好一次。这意味着,指示数据库忽略或覆盖重复,这样即使在重新处理相同事件的情况下,也不会对外部表产生真正的影响。
回到每分钟将原始事件写入数据库一次的示例应用程序,每个事件都有一个关联的 ID,可以用作表 PK。
假设 Flink 检查点每 5 秒触发一次,则两个检查点之间可能会发生故障。
在这种情况下,Flink 将从最后一个检查点恢复并从那里重播。
实际上,来自最后一个检查点的所有消息都将被重新处理并发送到数据库(下图中红色虚线内的所有事件),但它们将被忽略,因为这是两次写入相同事件 ID 的尝试。
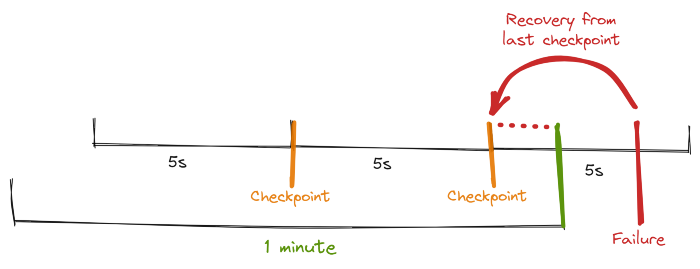
上图重新处理虚线时间线事件,但 DB 忽略它们
有人可能会争辩说,这种模式实际上是无状态事件处理,Flink 可能是一种矫枉过正的解决方案。当状态分布在多个节点上并且应该正确持久化时,复杂的 Flink 检查点机制非常有用,但是这个应用程序可以简单地由本地 Kafka 消费者/生产 API 实现,对事件进行分组,将它们写下来,然后才提交 Kafka抵消。
在任何消费者超时或重试的情况下,相同的消息将被重新处理,但不会产生实际影响。
我同意,如果每个应用程序都是确定性和幂等的,我们的生活就会容易得多(或无聊 :))。
卡夫卡事务
如果应用程序是从入站到出站主题的消费-过程-生产形式,通过 Kafka Transaction API 生产消息可能是通过原子操作消费、处理和生产消息的不错选择。
这里的关键是,任何轮询出站主题的下游 Kafka 消费者只会收到一次这些结果消息——保证不会有重复,即使数据接收器需要重试生成消息。
失败场景可能意味着原始消息被多次消费和处理(或部分处理),但这绝不会导致发布重复的出站事件。
为了利用此技术,所有这三个运算符(源、窗口和接收器)都应在同一组件上运行,以便任何出站消息的生成都将被提交消费者偏移量的同一事务所包围。以下是事务流程:
- beginTransaction发起新事务的服务调用
- 服务由生产者发布消息
- 消费者抵消也被发送到生产者以包含在同一事务中
- commitTransaction完成事务的服务调用
为了支持事务性生产,Kafka 引入了新的组件和概念,如 Consumer Coordinator、Transaction Coordinator 和 Transaction Log,这些在他们超过 60 页的设计文档中有详细描述,但重要的是要意识到作为处理的一部分发生的所有其他操作可以在重新传递原始消息的情况下,仍然会发生多次。例如,如果应用程序对其他应用程序执行 REST 调用或对数据库执行写入,这些仍然会发生多次。需要保证处理产生的事件只会被写入一次。
两阶段提交方法
还有另一种类型的应用程序从 Kafka 消费,执行一些聚合,然后将结果写入外部数据库。通常很难实现幂等性,因为聚合值可能会改变,但另一方面,它们不能真正从 Kafka 事务中受益,因为它无论如何都不受 DB 事务的限制。
让我们稍微改变一下我们原来的例子,这样它就不会写入原始事件,而是计算在 1 分钟窗口内发生的事件数,并将这个聚合值(只是数字)写入数据库。
显然,我们的主题有多个分区和并行运行的源、窗口和数据接收器操作符的多个实例。
业务不需要任何keyBy或逻辑分区,我们只是想以分钟的粒度统计事件。
试图实现幂等写入:
我们在聚合表中的记录标识符应该是什么?定义为<Sink Instance ID, minute>是有问题的,因为没有什么能保证在恢复后相同的事件将被发送到相同的操作员实例。
下图展示了一个潜在的情况,一个特定的 sink operator 实例最初处理 e45、e47 和 e52 事件,但在从最后一个检查点恢复后,它得到 e48、e49 和 e50(只是因为它现在得到了不同的 windows upstream windows operator ).
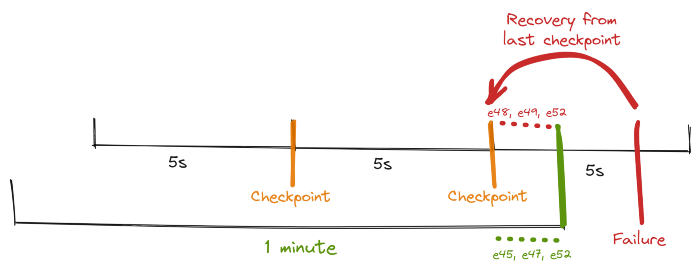
Flink 的TwoPhasedCommitSink特性非常有用。
为了在这种场景下实现 exactly-once,Flink 通过内部的 checkpoint 机制协调写入外部系统。
外部系统必须提供一种提交或回滚写入的方法,以便可以触发这些事件并与 Flink 的检查点管理协调。
在分布式系统中协调提交和回滚的一种常用方法是两阶段提交协议。
两阶段提交接收器应该实现四种不同的方法,Flink 将在检查点过程的各个阶段调用这些方法:
- beginTransaction事务捆绑两个检查点之间的所有写入,因此写入始终在事务范围内。此函数在新检查点开始时调用。所以在这里你可以打开一个数据库事务,如果你的数据库支持的话,或者在文件系统中创建一个临时文件。所有后续事件处理将使用它直到下一个检查点。
- preCommit在成功保留其内部状态后,一旦获得检查点屏障,接收器就会调用预提交。这将被每个 sink 调用,以便 Flink JobManager(协调器)只有在所有 sink 成功执行预提交后才能提交检查点。在这里,您可以刷新文件,关闭它并且再也不会写入它。或者,为属于下一个检查点的任何后续写入启动一个新的数据库事务。
- commit只有当 JobManager 通知它们检查点已完成时,每个接收器才会调用提交。在此阶段,您可以自动将预先提交的文件移动到实际目标目录,或者提交数据库事务。
- abort abort 函数将在分布式检查点已中止或中止失败后被协调器拒绝的事务时调用。在这里,例如,您可以删除临时文件或中止数据库事务。
请注意,此接收器实现本机与支持事务的数据库一起工作。但即使在接收器将聚合写入 AWS AppStream (TimeSeries DB) 的情况下,TwiPhasedCommit 函数的自定义实现也是可能的,实际的数据库写入应该推迟到commit 阶段。
需要注意的重要一点是,在成功预提交之后,必须保证提交最终成功——我们的操作员和我们的外部系统都需要做出这种保证。如果一次提交失败(例如,由于间歇性网络问题),则整个 Flink 应用程序失败,根据用户的重启策略重新启动,并进行另一次提交尝试。这个过程很关键,因为如果提交最终没有成功,就会发生数据丢失。
因此,我们可以确定所有操作员都同意检查点的最终结果:所有操作者都同意数据已提交或提交被中止并回滚。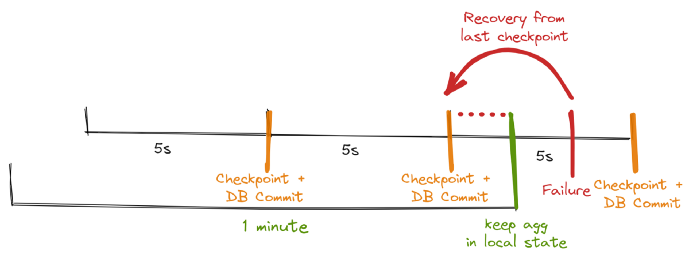
上图DB Writing依附于Checkpoint机制
所以我们最终实现的是,实际的 DB 写入是在持久化检查点和消费者偏移量的同一个“事务”中执行的。
概括
在分布式系统中处理有状态处理,尤其是当涉及不同的外部数据源或接收器(Kafka 和 DB)时,是具有挑战性的。重复消息是每个组件都可能暂时或永远失败这一事实的一个不可避免的方面。
Flink 的检查点系统作为 Flink 支持两阶段提交协议的基础,旨在提供端到端的 exactly-once 语义。
如上所述,可能会出现交易无法完成的罕见情况,Flink 将重新启动并永远重试(或者直到 AWS 解决其 AppStream 中断......)但这应该是一种非常罕见的情况。