分布式集群教程
分布式缓存架构综述

本文研究了分布式缓存,强调了它通过改进数据访问和可扩展性对应用程序性能的影响,并提供了实用指导。什么是分布式缓存?分布式缓存是指将信息存储在多个服务器上的方法,这些服务器通常分布在不同的地理位置。与集.
Java缓存备忘大全

Java 缓存是一种用于在临时存储区域(称为缓存)中存储和管理经常访问的数据的技术,以提高应用程序性能。缓存通过保持副本随时可用,有助于减少获取或计算数据所需的时间和资源。在 Java 中,缓存可以在.
Apache Kafka – 集群架构

Apache Kafka 到目前为止已经非常适合开发可靠的互联网规模的流应用程序,这些应用程序还具有容错能力,并且能够处理实时和可扩展的需求。在本文中,我们将重点介绍 Java 中的 Kafka 集群.
SpringBoot中实现两级缓存

缓存数据意味着我们的应用程序不必访问速度较慢的存储层,从而提高其性能和响应能力。我们可以使用任何内存实现库(例如Caffeine )来实现缓存。虽然这样做提高了数据检索的性能,但如果应用程序部署到多个.
Redis 与 NCache 比较

NCache 是一个原生 .NET 开源分布式缓存,在高事务性 .NET、.NET Core 和 Java 应用程序中非常流行。 Redis 由 Redis Labs 开发,目前由 Microsoft.
Cloudflare如何仅用15个Postgres集群就支持每秒5500万次请求

这篇文章介绍了Cloudflare如何通过使用PostgreSQL、PgBouncer、HAProxy和Stolon等工具来实现高扩展性和高可用性,应对多租户数据库环境中的性能隔离和负载均衡的挑战。他.
帮助理解分布式系统复制算法的开源项目

在分布式系统中,快速编码和测试对于理解Paxos等复杂概念至关重要。这个小框架来快速编写和测试各种复制机制。可以快速实现复制算法并编写 JUnit 测试。它还提供了引入进程崩溃、网络断开、网络延迟和时.
Slack 向蜂窝架构的迁移
近年来,蜂窝架构在大型在线服务中越来越受欢迎,作为增加冗余和限制站点故障影响范围的一种方式。蜂窝架构:客户端连接到路由层。路由层使用 HTTP 重定向将客户端重定向到指定的蜂窝单元。为了实现这些目标,.
使用 Skupper 实现 Kubernetes 多集群负载均衡

在本文中,您将了解如何利用Skupper在多个 Kubernetes 集群上运行的应用程序实例之间实现负载平衡。我们将使用 Kind 在本地创建一些 Kubernetes 集群。然后我们将使用 Sku.
时钟和因果关系 - 分布式系统中的排序事件

系统事件可以根据它们发生的时间来排列。时钟计时并产生时间戳。传统时钟(例如时钟)使用通用参考来了解时间。该参考可以是内部硬件或使用 NTP 等协议提供时间的公共服务。然而,由于时钟漂移和/或网络时间延.
如何横向扩展 PostgreSQL?

水平扩展是在不影响数据完整性、事务安全性和查询性能的情况下跨多个服务器分布数据的艺术和科学。只读副本只读副本通常指的是“备用”服务器,它冗余地复制主服务器上的所有数据,持续与主服务器保持同步,并允许客.
Shopify如何对商店MySQL实现K8S的Pod分片平衡?
Shopify 的基础设施为数百万商家的创业之旅提供支持。当前基础设施的一个关键组成部分是底层的 MySQL 数据库分片,它们共同保存每个商店的关键数据。随着流量模式的变化和新商家加入平台,资源密集型.
Twitter为什么没有宕机?
五年来,我一直是 Twitter 的站点可靠性工程师 (SRE),以后四年里,我是 Cache 团队唯一的 SRE,四年来,我负责团队中的自动化、可靠性和运营。我设计并实现了大部分保持它运行的工具。缓.
本地计算、云计算、雾计算、边缘计算有什么区别?

在我们开始比较内部部署与云计算与雾计算与边缘计算之前,我们需要退一步,使用第一原则思考,首先以逐步的方式定义这些术语。让我们从什么是计算开始? 为了我们的目的,让我们保持简单:它是由计算设备(硬件或.
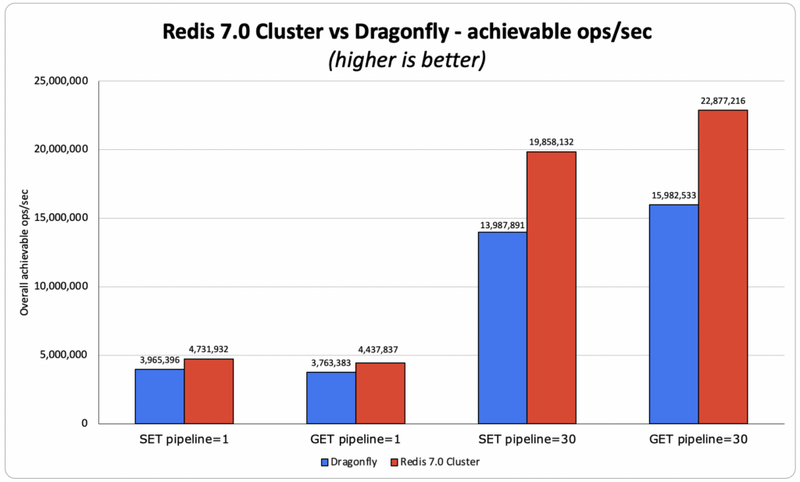
Redis老了吗?Redis与Dragonfly性能比较
RabbitMQ的脑裂踩坑 - ryanrodemoyer
我的手表嗡嗡作响,在黎明前的昏迷中,我无法辨认这是警报还是电话。时间是凌晨 4 点 45 分:我们最大的客户报告说他们的请求需要两个多小时才能返回结果。我们认为这是因为我们的RabbitMQ消息系统。.
沃尔玛针对高峰流量扩展其库存预订API处理能力 - Shanawaaz
当顾客在Walmart.com网站或移动应用程序上下订单时,会有一个库存预订电话。这捕获了对顾客购物车中的商品的需求。在感恩节假期或任何销售活动(如PS5或Xbox活动)期间,库存预订请求的数量会显著.
Wix如何零停机将将2000个微服务迁移到多集群Kafka?
为了更轻松地将 2000 个微服务的生产者和消费者迁移到多个托管的 Kafka 集群,最初的设计依赖于首先完全排空每个数据中心(DC)的流量。这种设计意味着只需将生产者和消费者的连接细节切换到他们的新.
为什么Kubernetes这么难? • Buttondown

Kubernetes 比我使用过的其他一些系统感觉更大、更可怕、更难处理。在我学习并使用它的过程中,我试图理解为什么它看起来像现在这样,以及哪些设计决策和权衡导致它看起来像现在这样。我并不声称拥有完整.
如何使用Kubernetes Cluster API和ArgoCD创建和管理多个Kubernetes集群 - Piotr

Memcached与Redis在内存机制和集群等方面的比较 - Kablamo
Memcached 创建于 2003 年,在用 C 重写之前用 perl 编写。最初是为 livejournal 创建的,它成为 Web 2.0 时代的 goto 堆栈增强之一。Youtube、Red.
Notion网站如何将单体PostgreSQL分片成一个水平分区的数据库群?
在我们不断努力提高应用程序性能的过程中,分片是一个重要的里程碑。在过去的几年里,看到越来越多的人将 Notion 应用到他们生活的方方面面,我感到欣慰和欣慰。不出所料,所有新的公司 wiki、项目跟踪.
Myntra如何设计其用户账户的数据库架构?
Myntra用户帐户服务是创建和管理帐户所需的用户属性。帐户服务将存储用户凭据、主要/次要电子邮件/电话、性别、年龄等属性(完整列表可在后续部分中找到)。所有这些属性都在帐户级别,不包含任何其他域/服.
三种使用Kafka的最佳实践方法 - antonmry
Apache Kafka于2011年初由LinkedIn开源。尽管存在所有最初的限制,但它还是取得了巨大的成功,并成为了流数据的事实上的标准。性能,重播事件的可能性以及独立的多个用户是其领先流媒体竞技.
探索无Zookeeper的新Kafka - morling

有时候,少即是多。绝对正确的一种情况是依赖项。因此,Apache Kafka社区热切地等待着对ZooKeeper服务的依赖关系的删除就不足为奇了,过去ZK主要用于存储Kafka元数据(例如,有关主题和.
Redis全方位作用总结 -Vedcraft
Redis作为开源内存数据存储不仅限于缓存,还是数据库、事件存储、消息代理、内存数据存储、AI功能存储、AI和搜索解决方案,使我们能够构建超低延迟和高吞吐量的实时应用程序。本文总结了Ofer Beng.
关于负载平衡和分片 - Tim Bray
如果您确实需要处理大量流量,则只有一种方法:分片。也就是说,根据需要将传入请求分配给尽可能多的主机(或Lambda函数,消息代理或数据流)。一旦完成这项工作,您就可以处理几乎无限的请求量。当然,您必须.
Monzo使用Cassandra与微服务架构实现大规模支付运维过程中的事故与单点风险
系统出现严重的问题,马上公开披露技术细节,而不是让民间流言替代真相,这样的分享值得点赞:7月29日从大约13:10开始,你可能会遇到Monzo的一些问题:可能无法: 登录应用程序 发送和接收付款,或从.
Kubernetes入门词汇术语解释

Spring Data Redis:Sentinel的高可用性 - Michael C. Good
为了使用Redis实现高可用性,我们可以使用Spring Data Redis对Redis Sentinel的支持。使用Sentinel,我们可以创建一个自动抵御某些故障的Redis部署。Redis .