mapreduce
如何在 Flink 中处理数据倾斜?

数据倾斜是指数据集的不平衡分布。这种不平衡通常是通过特定指标或领域的镜头观察到的。我们可以说一个国家的人口数据集在按人口中心分组时是有偏差的(假设更多的人住在几个大城市,而其他地方的人口较少)。这本身.
Hadoop面试题之MapReduce

什么是MapReduce?它是一种框架或编程模型,用于使用分布式编程在计算机集群上处理大型数据集。什么是“Map”和“Reduce”?“Maps”和“Reduces”是在 HDFS 中解决查询的两个阶.
Javascript的map、reduce、filter新数组使用方法

数组是编程世界中最常用的数据结构。较新的数组方法,如map(),reduce()和filter()广泛用于使用一些库/框架(如 React/Vue/Angular)构建项目。在这篇博文中,我将通过真实.
为什么纯函数式语言至今无法流行起来?

编程可以从冯诺依曼风格中解放出来吗?使用一种函数式风格及程序代数替代它?为什么纯函数式编程无法成为主流?为什么纯函数式语言无法真正解决实际问题?CS大学里那些书呆子的梦想式白日梦还是终有一天会实现?冯.
Java函数式编程中归约reduce()的使用教程

归约Reduce流运算允许我们通过对序列中的元素重复应用合并操作,从而从元素序列中产生一个单一结果。其中参与者有三者: 标识identity:代表一个元素,它是归约reduce运算的初始值,如果流为空.
Java Map的最佳实践 - tremblay

今天的主题是关于Map我在许多代码评审中看到过的错误。在Java 8中,添加了一些有用的新方法:if (map.containsKey(key)) { // one hash return ma.
使用Map.merge()替代ConcurrentHashMap
Map.merge()意味着我们可以原子地执行插入或更新操作,它是线程安全的,ConcurrentHashMap虽然也是线程安全的,但不是所有操作都是,例如get()之后再put()就不是了,这时使用.
Apache Spark编程教程
Apache Spark是一个分布式计算平台,在当今非常流行,特别是因为与Hadoop mapreduce相比性能要好得多,Spark比基于磁盘的hadoop mapreduce 快了近100倍。让我.
10个SQL技巧之三:进行总计算

至少有十几种方法可以实现运行总计。从概念上讲,运行总计很容易理解。在Microsoft Excel中,您只需计算两个先前(或后续)值的总和(或差异),然后使用有用的十字光标在整个电子表格中提取该公式。.
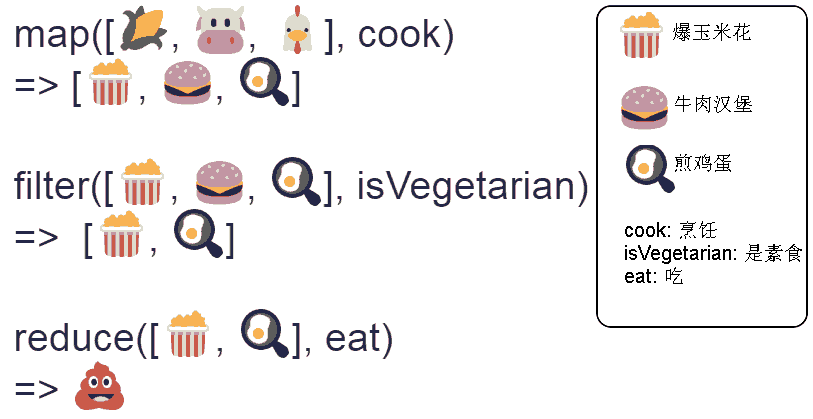
Map/Reduce的形象解释图

一张图解说Map/filter/reduce
Apche Spark的命运

Spark取代了MapReduce,同样逻辑,什么会取代Spark?Apache Spark is doomed文章提出了自己的看法。Spark将数据装入内存in-memory, 比MapReduce.
数据表每天五千四百万数据,,如何汇总
mysql数据表table1每天5千4百万数据,十张分表(或者五十张分表),目前还未确定分表数,数据量是确定了,根据表中四个字段(c1,c2,c3,c4)汇总,四个字段相同就可合为一条,累加金额。目前.
分解和组合的机器学习

转发自分解和组件的抽象方法人的这种分解和组合思维能力也可通过机器学习算法进行模拟,再配合大数据进行训练,人工智能也就应运而生。其实Hadoop的Map/reduce算法本身就是一个分解和组合的算法,通.
Orzo.js是一个可用Javascript编程的Map-Reduce多线程实现

Orzo.js是一个简单的多线程Map/Reduce的Java实现,但是可以使用Javascript编程的库包。它设计为运行在单机多核上。Orzo.js的map-reduce脚本可使用JavaScri.
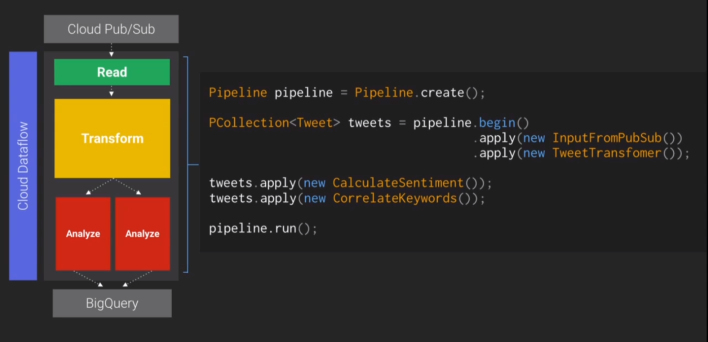
Google使用Pipeline统一了大数据批处理和流处理
使用Java 7.0的 Fork/Join框架进行并发编程