使用CQRS重新考虑架构
命令查询的责任分离Command Query Responsibility Segregation (简称CQRS)模式是一种架构体系模式,能够使改变模型的状态的命令和模型状态的查询实现分离。这属于DDD应用领域的一个模式,主要解决DDD在数据库报表输出上处理方式。
来自Rethinking architecture with CQRS一文对CQRS进行详细描述。
很多应用都需要持久层保存状态,因为这些状态不能丢失,如果只是放在内存中,而不是持久到磁盘上。状态是在领域模型中,每当模型保存到数据库以后,会有更多复杂的查询,都是使用复杂且慢的SQL语句实现的。比如如下复杂SQL语句:
|
如此复杂的SQL语句为什么不能用一句简单SQL完成呢?
|
如果你要这么做,就必须使用到CQRS模式。
Greg Young在infoQ的采访中“State Transitions in Domain-Driven Design”谈到了CQRS,Greg 解释了把领域模型分为两种:状态校验,以及状态转换,维持当前状态的一个视图。
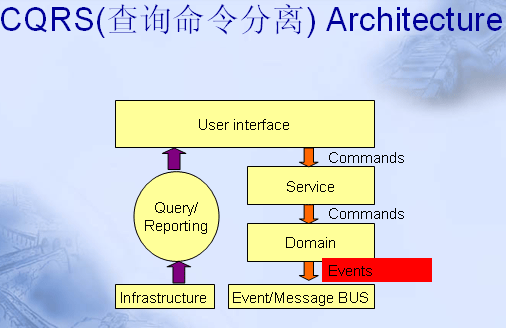
CQRS架构如下图:
在客户端就将数据的新增修改删除等动作和查询进行分离,前者称为Command,走Command bus进入Domain对模型进行操作,而查询则从另外一条路径直接对数据进行操作,比如报表输出等。
当一个Command进来时,从仓储Repository加载一个聚合aggregate对象群,然后执行其方法和行为。这样,会激发聚合对象群产生一个事件,这个事件可以分发给仓储Repository,或者分发给Event Bus事件总线,比如JavaEE的消息总线等等。事件总线将再次激活所有监听本事件的处理者。当然一些处理者会执行其他聚合对象群的操作,包括数据库的更新。
因为领域对象操作和数据库保存持久这两个动作分离,因此,数据表结构可以和领域对象松耦合(JiveJdon源码可展示领域对象和数据表不再是一对一对应依赖,这也是使用Hibernate 等ORM框架容易造成的问题),你可以优化数据表结构专门用于查询。
再者,由于事件驱动了领域模型的状态改变,如果你记录这些事件audit ,将可以将一些用户操作进行回放,从而找到重要状态改变的轨迹,而不是单纯只能依靠数据表字段显示当前状态,至于这些当前状态怎么来的,你无法得知。当你从数据库中获得聚合体时,可以将相关的事件也取出来,这些叫Event Sourcing,事件源虽然没有何时何地发生,但是可以清楚说明用户操作的意图。
虽然这种架构有些复杂,但是好处却很多,主要的是实现透明的分布式处理Transparent distributed processing,当使用事件作为状态改变的引擎时,你可以通过实现多任务并发处理,比如通过JVM并行计算或事件消息总线机制,事件能够很容易序列化,并在多个服务器之间传送,(EJB提倡贫血失血模型,实际就是为解决胖模型在多个服务器之间传送时序列化耗费性能,现在我们不序列化模型,而是改变模型数据的事件)。
你可以让聚合体(胖模型)一直驻留在特定服务器中,这样可以为不同的应用选择不同的SLA。
由于事件处理是异步的,用户就不必等待所有操作完成(同步则是所有操作完成后才返回操作结果界面给用户,异步架构符合Jdon一直提倡的异步架构),CQRS实际可以利用BASE原理(CAP定律和BASE思想),实现最终一致,取得高可伸缩性,尽管最终一致使很多程序员有些恐慌,但是分布式ACID 事务却也让他们产生怨恨,其实最终一致其实最多是几个毫秒的延迟,但是你可以充分利用这几秒的延迟做更多事情。
当你使用异步事件模式以后,可以使用Esper 等EDA工具进行事件拦截和分析,该文作者就是利用它实现 RSA Adaptive Authentication用户登录后的授权处理。
最后该文作者推荐了一个基于Spring的CQRS的框架cqrs4j,这个框架是5天前刚刚推出,不过了解Jdonframework的人也许知道,Jdon框架6.2也是可以实现CQRS,不过是在同年11月上架的,且不谈两个框架比较,单理念上Jdonframework是世界同步的,说明世界不同角落里人都想到同一个问题了,本文很多理念其实在J道网站已经倡导多时,并且通过Jdonframework的Domain Events + 异步实现了。
相关CQRS 讨论
[该贴被banq于2009-12-24 14:54修改过]