Revolut需要记录每个与金钱有关的事件,它们都很重要的;这是一个水晶球,我们必须小心接住并处理。此类事件包括汇款,更改用户数据,任何卡操作等。与处理财务操作相关的所有事情都需要100%的一致性,金钱是非常敏感的事情。同时,我们每天必须跟上成千上万新用户的步伐。指数级放大还影响功能交付。我们一直在开发新的和现有的产品,但是新的复杂性正在出现。所有这些使我们处于需要专用解决方案的特殊位置。
为什么不使用现成的解决方案?
像Kafka这样的现成的解决方案可能已经解决了我们的一些问题,但同时也会带来维护,配置和保持可用性的复杂性。因此,我们选择投资自定义解决方案,该解决方案将随着我们要解决的问题而增长。
有了我们自己的解决方案,我们就可以控制事件的整个生命周期 -从事件作为业务交易的一部分创建到到达EventStore并通过EventStream进行流式传输。
我们添加了Kafka不支持的以下功能(至少不能以轻松满足我们需求的方式):
- 由于将事件存储在PostgreSQL中,因此可以使用SQL进行即席查询和轻松进行数据检查。
- 按事件时间查询-我们按时间戳划分事件。
- 状态更改和持久事件之间有保证的一致性,例如,状态数据库中的卡阻塞可保证CardBlocked事件。
- 关系:我们具有事件的嵌套结构(具有零个,一个或多个模型事件的动作事件),并且我们需要流式传输模型事件,而不是流事件。我们可以研究这种结构的非规范化/扁平化以适应第三方解决方案,但是作为副作用,我们将不得不面对不必要的数据冗余。
- 该系统应允许使用者基于任意有效负载过滤器查询事件,而不是处理所有事件或整个分区。
- 轻松归档旧事件。
- 在多个使用者节点上的并行事件流处理由任意分区键分割。
我们希望每个模型的事件自然顺序得到保证。
我们不希望任何可能导致事故的意外发生。Kafka需要处理角落里零星的专业知识。例如,设置其默认配置时要考虑吞吐量,而不是考虑高一致性。缺省情况下,不执行诸如fsync之类的操作,因此可能会导致生产者/消费者之间的某些数据丢失或不一致。
无论选择哪种解决方案,我们仍然需要一个数据库(例如Postgres)和一个应用程序层。尽管现成的解决方案无法替代我们的整个系统,但它可能会接管其某些功能。例如,Kafka可用于接管短期(例如7天)持久事件流的职责。从吞吐量的角度来看,有其他选择,例如Pulsar(事件流比Kafka具有更好的性能)和TimescaleDB(Postgres的时间序列数据库扩展,用于优化基于时间的存储和查询)。
业务特点
当您处理金钱并出了点问题时,您需要知道与该操作相关的每项操作。识别并记录所有货币交易,回滚以及相应的用户数据。客户服务可以使用此审核日志对问题进行适当的反应。
风险检测:一些服务插入数据到EventStream,以便后来根据需要使用这些数据。他们运行模型(通常基于机器学习算法),以评估面临不同形式的金融犯罪风险的风险。
外汇操作中的实时监控:Revolut最受欢迎的功能之一是货币兑换。我们允许客户比其他银行更便宜地进行外汇交易。因此,为了促进我们的主要功能,我们需要实时监视进入系统的所有交易。我们实时对外汇风险敞口进行自动对冲。
市场推广:我们消耗事件,观察模式和行为,并根据结果触发个性化的营销活动和促销。
我们对解决方案的期望
最初,我们所需要的只是一个交换事件并能够动态查询事件的系统。后来,随着Revolut产品的开发,我们的要求也相应地发展了,并提出了以下建议:
- 业务数据的准确性
- 高服务可用性
- 进行高级查询的能力-如按事件类型过滤交易事件
- 系统的可扩展性
- 数据的不变性
- 低延迟或具有控制延迟的能力(事件的完整处理,包括大约50-200 ms的存储和流传输)
- 可观察性-事件发生的原因和地点,是否可以预见
我们回顾了早在2016年初当时市场上可用的事件流解决方案,但找不到能同时满足我们所有需求的事件流解决方案。例如,将缺少进行临时查询的能力,或者维护第三方解决方案需要大量专业知识来处理极端情况。
因此,我们在Revolut创建了自己的事件流媒体。
我们的解决方案设计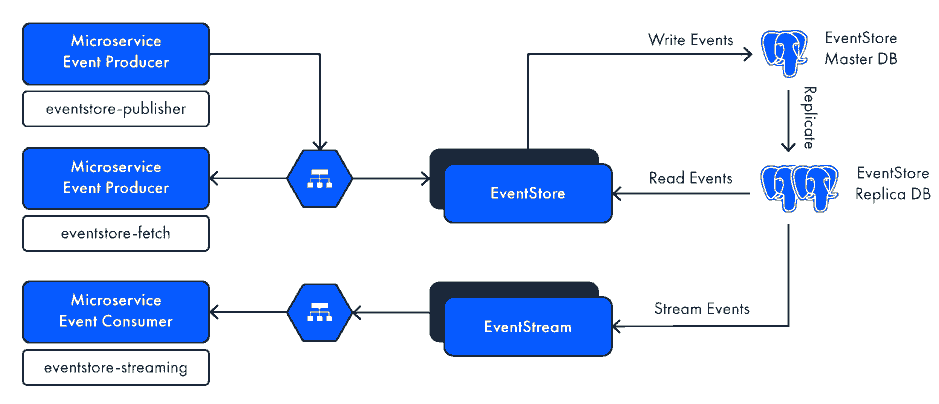
大多数Revolut服务都使用PostgreSQL 来存储数据。对于事件,我们还将PostgreSQL与listen / notify机制一起使用,因此我们可以重用来自不同团队的所有经验,从而使消费者可以对数据库进行高级查询。当我们使用PostgreSQL复制时,我们有两种数据库实例-主数据库和副本数据库。我们使用一个主机 来存储事件,并使用一个副本来进行流和获取。
我们有 EventStore 应用程序,它负责编排事件的存储和获取。由于所有事件都位于Postgres中,因此此EventStore实现是无状态的。它使用JetBrains Ktor框架和协程在Kotlin中编写。我们使用EventStore应用程序的两个实例,但根据负载,您可以拥有更多实例-它们的数量是水平缩放的。实例之间的负载由负载均衡器处理。
我们还有 EventStream 集群,它完全负责向订阅者流式传输事件。EventStream是使用RSocket在Java 11中开发的,用于处理使用者与EventStream之间的通信弹性。
我们使用Google Cloud Platform,特别是虚拟私有云来隔离系统的不同部分,并促进适当的访问管理。我们将存储与应用程序分开,而应用程序实际上是与API网关分离的。
最后,我们获得了一组微服务,这些微服务执行发布者,使用者或只是获取事件的服务的角色。我们决定开发用于服务的SDK-将客户端SDK和服务器置于一个团队的控制之下,这使我们可以最大程度地减少向后兼容性问题,抽象协议,并使REST API的更改更加容易。
实现准确性和一致性
这里有两个选择;事件溯源和事件流。
您可以在首次生成事件然后对其进行处理时选择事件源方法。但是,我们希望最终用户的体验与使用即时反馈进行同步处理一样。这就是为什么我们选择第二个选项。
我们更改模型,然后基于此更改生成事件。因此,我们有两个分开的东西:模型和事件,我们需要保持这两者一致。如果回滚一个,那么您也必须回滚另一个。如果其中一个成功,您知道另一个也成功。![]()
流程的每个步骤:每个微服务和每个EventStore都有自己的数据库。当服务产生事件时,我们不发送事件,而是更改数据库中的模型,并且为了实现一致性,我们将模型和事件都保存在同一数据库中。数据库事务保证成功或回滚,系统就将回滚模型和事件,或者将两者保存。因此,一旦我们成功完成模型更改,事件就会保存到数据库中。然后,我们异步发布事到到EventStore,(banq注:关键是如何知道事件已经保存到数据库,估计是通过查询数据库新事件),如果发送失败,进行重试,并使用保证交付的机制,使我们保持一致性。
就这么简单吗? 并不是的。实际上,我们几乎没有方法发送事件以确保事件已交付。在业务操作期间,我们将事件发布到EventStore,如果发生故障,可能会重试。同时将事件存储在EventLog表中。如果事件未成功发布,则我们的后台协调流程将在EventLog中识别出该事件,并将重新发送它们,直到事件成功为止。我们将所有事件保留24小时(可配置),因此需要我们在此时间内解决所有基础架构或其他问题。
我们还进行清理以管理EventLog表的大小。如前所述,所有早于24小时的事件都将被清除,这使我们可以使EventLog表保持较小。(banq注:EventLog表类似发件箱模式中发件箱)
将成功事件保存到EventStore数据库后,我们将使用LISTEN / NOTIFY Postgres机制 :在任何时间,我们都可以通过Postgres通知EventStream发生了某些事件。因此,无论何时将事件写入数据库,PostgreSQL都会触发包含所有EventStream实例完整事件消息的事件。后来,EventStream将这些事件发布给所有以匹配条件订阅它们的使用者。(banq注:严重依赖了Postgres特有机制)
处理重新连接
假设使用者开始获取事件,但是处理速度很慢-在这种情况下,我们使用背压机制。在某个时候,队列可能已满,因此我们暂停处理,一旦使用者完成对队列的处理,它就可以开始请求更多事件。此外,对于服务的任何停机时间,使用者都可以根据PostgreSQL在插入上设置的时间戳在任何时间返回。
我们有两个部分的流媒体过程。每当进行新订阅时,它都基于脱机模式启动,因为它基于上次快照时间或上次处理的事件时间-这适用于任何副本。一旦脱机流赶上来,它将切换到联机模式,该模式使用LISTEN / NOTIFY Postgres机制-在这种情况下使用逻辑副本。
领域拆分
我们必须在分布式系统中处理的另一重要事情是域拆分-我们使用Saga模式解决它。由于所有业务事务都以“动作”表示:我们可以定义所有相关动作的Saga链,确保我们可以观察到处理状态并在发生任何失败时重试,或使用事件使用者进行恢复。使用事件使用者的后备之所以起作用,是因为每个Action都会产生事件,因此,我们可以确保在任何给定时间点都可以从事件中恢复。这就要求我们编写的每个动作都是幂等的,因为它会被处理Saga流或事件使用者(后备)调用几次。
事件协调机制
每当事件发布到EventStore时,我们都有一个后备机制![]()
假设我们在同一个应用程序有三个实例需要位于同一业务交易事务中。在业务运营期间,他们还会发送有关他们的事件。如果它们中的任何一个失败,那么未处理的事件将出现在EventLog中。现在,我们不希望所有应用程序参与协调失败的事件,因为这将导致很多不必要的工作以及更新成功事件的失败(因为其他应用程序会执行相同的工作)。为了解决重新发送失败事件的问题,我们需要其中一个应用程序成为所谓的事件协调器。发布者的这个实例将进行对帐处理-基本上是指从EventLog中读取30 s以上的未标记为已发布的事件,然后重新发送。因此,我们可以保证每个事件迟早都会发布。
结论
您可能会想到,我们拥有的解决方案非常复杂并且还在不断发展。我们仍然需要克服许多挑战,但是我们的解决方案为我们提供了所需的灵活性和性能,因此可以满足不断增长的需求。这是有关事件流平台的系列文章中的第一篇,请回来查看更多内容!