本文讨论将数据湖概念化为数据库的想法。
在这篇文章中提出的想法不是新的。但是物化视图从未被广泛采用作为构建数据管道的主要工具,这可能是由于它们的局限性和与关系数据库技术的联系。也许通过dbt和Materialize之类的新工具浪潮,我们将看到物化视图在典型数据管道中被更多地用作主要构建块。
无论我们是否看到这种广泛的变化,物化视图仍然是用于概念化构建数据管道时正在执行的操作的有用设计工具。
弄清哪些数据是主要数据,什么是衍生数据。将管道映射到包含具体化的中间数据集的转换图的概念,每个数据集均具有特定的更新触发器和更新粒度。
这项练习应该有助于给最混乱的管道带来一些概念上的秩序。
假设您经营一家在线书店,并希望建立一个数据管道来确定谁是最畅销的作者。从逻辑上讲,流水线的输入是商店中每时每刻购买的每本书籍的日志,以及每本书籍的详细信息(例如作者)。输出是每月最畅销作者的列表。
该数据管道的输出是输入的函数。换句话说,通过流水线运行输入,从输入中获得输出。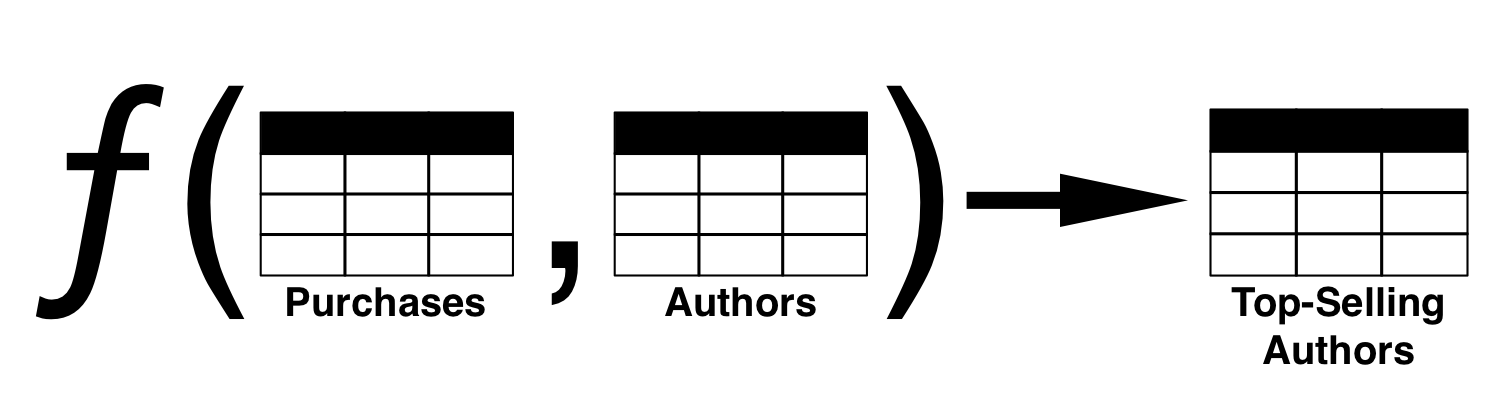
这是输出的重要特征。只要保留输入数据和管道转换(即管道代码),就可以始终重新创建输出。输入数据是主要数据;如果丢失,则无法更换。输出数据以及管道中的任何中间阶段都是导数;始终可以使用管道从原始数据中重新创建它们。
逻辑视图
让我们将我们的假设性“畅销书作者”管道表示为有向图,其中节点代表数据集,边缘代表这些数据集的变换。此外,让我们根据图表的每个数据集是主要数据还是派生数据来着色。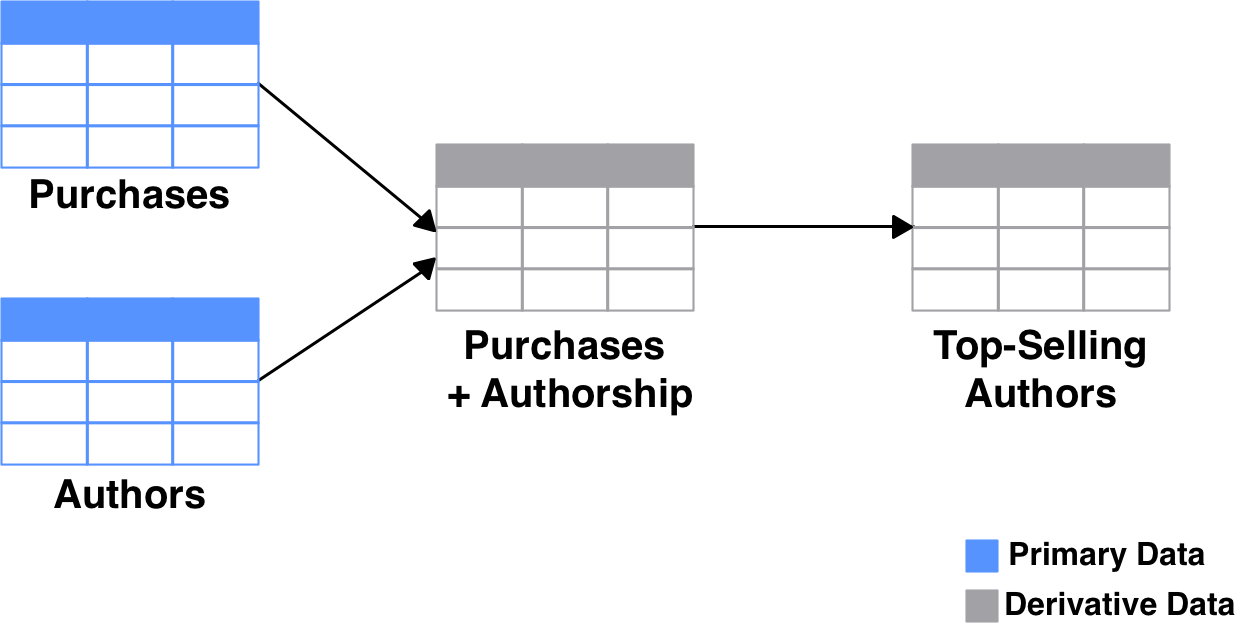
如果缩小得足够远,大多数数据管道看起来都是这样。您有一些源数据。它以各种方式被切片,切块和组合以产生一些输出。如果有人要清除此管道中的所有派生数据,则可以重新生成它而不会丢失任何数据。管道可以包括任意数量的任意步骤,例如从FTP共享复制文件或从网页抓取数据。只要在给定相同的输入时管道产生相同的输出就没有关系。
每当有人查询管道的输出时,从逻辑上讲,这等效于他们在源数据上运行整个管道以获得所需的输出。这样,管道就是对源数据的视图。
实现视图
当然,数据管道在实践中不会以这种方式工作。如果每个查询触发一系列的计算一直延伸到原始数据,那将浪费资源并需要长时间的用户。当您要求本月最畅销的作者时,您会期望得到快速的答复。
因此,典型的现实世界管道会实现其输出,通常还会产生一些用于生成最终输出的中间数据集。实现数据集只是意味着将其保存到持久性存储中,而不是动态地重复计算它。因此,当您要求该作者列表时,回答您查询的任何系统都可以从最接近的实体化数据集开始,而不是从源数据或主要数据开始。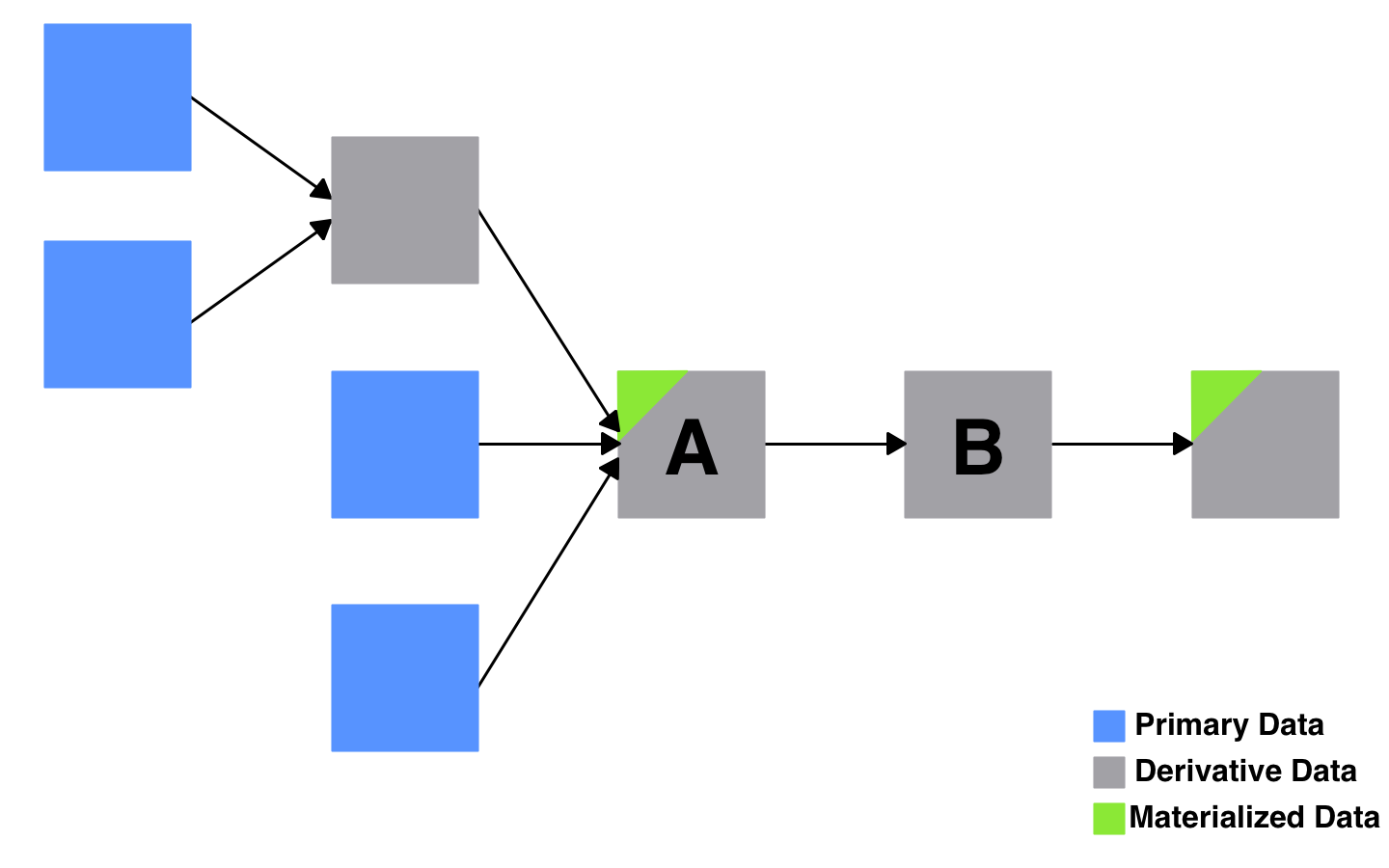
由于A已实现,因此对数据集B的查询仅需要重新计算从A开始的管道。所有派生数据集,无论是否实现,都可以丢弃,并从原始数据中重新创建。
因此,我们已将我们的视图变成了实体化视图。“视图”表示管道中表达的逻辑转换。“材料化”表示以下事实:我们缓存了管道的输出,也许还有一些中间步骤。可以通过这种方式将一组复杂的相互依存的数据管道概念化,作为实体化视图的图形。
请注意,这个概念可以广泛应用,而不仅仅是我们认为的“常规”数据管道:
- 传统的Web缓存可减轻来自主数据库的读取流量,这是事实的来源。缓存是派生的,可以随时从数据库中重新生成。缓存中的数据已实现,因此传入查询不需要一直返回数据库即可获得答案。
- 构建系统将源代码编译或组合为工件,例如可执行文件或测试报告。工件是派生的,而源代码是主要的。一遍又一遍地运行程序时,您将重用构建系统输出的工件,而不是每次都从源代码重新编译它们。
更新实例化视图
实现输出,尽管对于大多数管道来说实际上是必需的,但是却增加了管理成本。当源数据更改时,需要更新实例化视图。否则,您从视图获取的数据将是陈旧的。
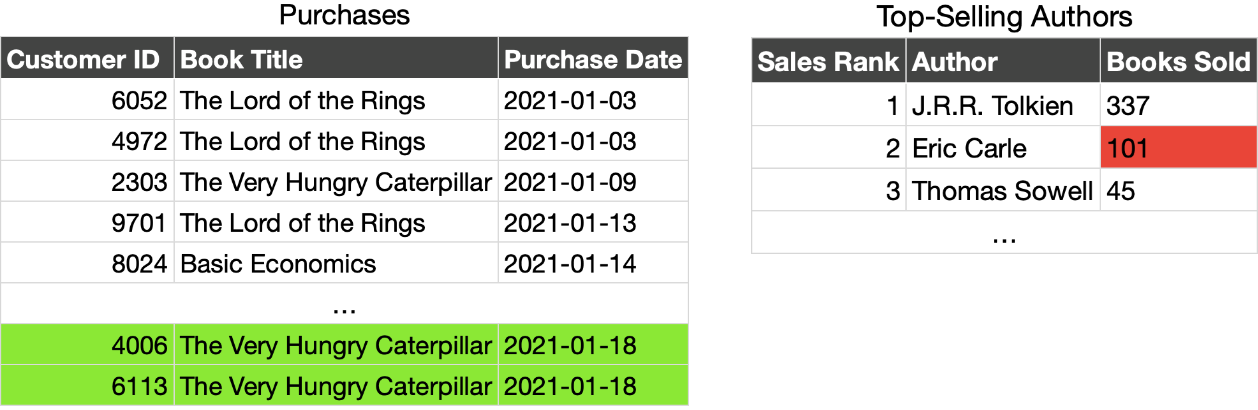
埃里克·卡尔(Eric Carle)的总销量为101辆。现在正确的值为103。
要更新实例化视图,通常需要关注两个高级属性:更新触发器和更新粒度。前者影响输出的新鲜度,后者影响数据的最终用户,而后者影响更新过程的性能,后者影响负责该过程的工程师或操作员。
更新触发器
更新触发器是提示刷新实例化视图的事件,例如,通过针对最新源数据运行管道。
该事件可能是文件降落在共享驱动器上,或者某些数据到达事件流,或者另一条流水线正在完成。对于某些管道,更新触发可能只是一天中的某个时间,在这种情况下,谈论更新频率比触发可能更有用。
例如,典型的批处理管道可能每天或每小时运行一次,而流传输管道可能每隔几秒钟或几分钟运行一次,或者每当通过某种事件流传递新事件时就运行一次。每当管道运行时,它都会更新其输出,并且整个过程可以看作是物化视图的刷新。
更新粒度
更新粒度是指需要修改多少实体化视图以说明对源数据的最新更改。
常见的更新粒度是完全刷新。无论对源数据的更改有多大或少,管道运行时,它都会丢弃整个输出表并从头开始重建它。
更复杂的管道可能只重建表的一个子集,例如日期分区。而且极其精确的管道可能知道如何准确更新受源数据的最新更改影响的输出行。
更新触发器和粒度是独立的。您可以有一个每秒运行一次并对其输出进行完全刷新的管道,并且您可以有一个每天运行一次但仔细地仅更新它需要更新的行的管道。
典型例子
让我们使用示例管道来探讨这两个属性,该示例管道计算当月最畅销的作者。
- 每日批次更新
每天晚上1点,自动过程都会查找前一天最新购买的商品。转储是压缩的CSV文件。
更新过程使用此转储重新计算所有作者的当月销售额。它用所有作者的全新计算替换整个输出表。自上次更新以来,许多作者的数字可能没有改变(因为在那个时间段内他们没有新的销售记录),但是尽管如此,他们全都被重新计算了。
这是批处理管道的非常典型的示例。它有一个计划的更新触发器,该更新触发器在每晚的凌晨1点进行,并且具有整个输出的更新粒度。
- 实时更新表
在我们最畅销的作者渠道的此版本中,通过Apache Kafka之类的流处理器将个人购买在发生时进行流式传输。此流上的每次购买都会触发对最畅销作者的计算方式的更新。
更新过程使用每个单独的购买来递增地重新计算相关作者的总销售额。如果作者在给定的更新间隔内没有新的销售量,则不会重新计算其销售总额(尽管他们在畅销书中的排名可能需要更新)。
这是一个精确流传输管道的示例。更新触发器是流式传输的购买事件,更新粒度是单个作者的销售总额。
声明式数据湖
前面我们讨论了将数据湖概念化为数据库的想法。在这里,我们展示了如何将数据管道概念化为实例化视图。
但是,如果我们不仅可以将其作为一种概念工具,还可以进一步推广该想法?如果您实际上可以将数据管道实现为实例化视图的图形怎么办?
远远地讲,这种想法的希望将是建立一个声明性的数据湖,其中管理该湖的代码更多地集中在定义数据集是什么上,而不是如何机械地构建或更新它们。
两个相对较新的项目以清晰但不同的方式表达了这一愿景的各个方面,在这里值得进行一些讨论:dbt和Materialize。
- dbt:管道作为批处理更新的SQL查询
dbt的核心是用于构建SQL查询图的引擎。可以使用模板语言(Jinja)动态生成任何给定查询的一部分,并且查询可以引用其他查询。
每个查询都有配置的实现策略,该策略定义查询结果是否提前生成,如果是,则如何存储和更新它们。
如果实现了结果,则可以通过完全刷新或增量更新来进行更新,尽管对于可以增量执行的更新类型有一些限制。通常会按计划触发更新。
- 实现:将管道作为实时更新的实现视图
Materialize是一个引擎,用于从Apache Kafka等流媒体源构建实时的,增量更新的实例化视图。一个视图可以引用其他实时更新的视图以及固定表。
创建这些视图的主要界面简洁明了:一条CREATE MATERIALIZED VIEWSQL语句。
从概念上讲,这与传统 关系 数据库中可用的语句大致相同 。然而,Materialize的实现允许针对非常灵活和富有表现力的查询进行非常高效的增量更新。Materialize的功能基于其创建者所做的相对较新的研究。