检测重复消息的唯一方法是在生产者端为事件生成一个唯一标识符。只有使用这些标识符,消费者才可能知道它第二次处理同一条消息,而不是具有相同属性的不同消息。
为了防止两次处理同一条消息,常用的方法是将它们存储在指定的表中,通常命名为processed_messages或inbox。事件的唯一性可以通过事件标识符上的唯一索引来保证。在所有生产者之间生成真正唯一的标识符可能会有问题,但在单个生产者中,这是可以毫无问题地实现的。在这种情况下,我会考虑使用事件标识符和生产者标识符的组合,这可能只是一个上下文名称,例如[11153, 'orders']。
事件应该在早期阶段存储在表中——甚至在消费者向代理发送确认之前。在这种情况下,当确认没有到达代理并且它再次发送消息时,消费者尝试再次存储它,但由于违反唯一约束而失败。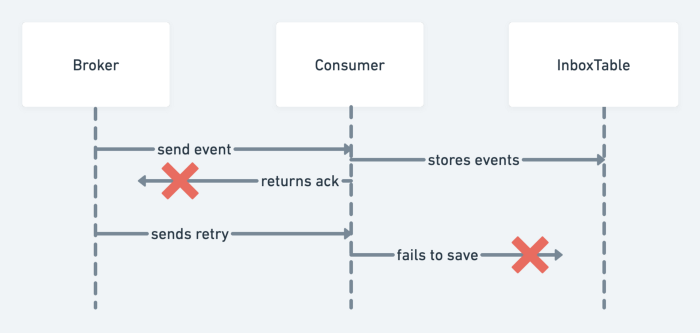
上图收件箱表无法两次保存同一事件
如果消费者成功地将确认返回给代理然后才失败,会发生什么情况?这要看情况。有时再次处理同一个事件就可以了。对于这种情况,收件箱表中有一个附加字段很有用,它表示事件的状态。例如,刚刚插入表中的事件的状态为“ pending ”。消费者更新数据库中的所有实体,并在同一事务中将事件状态更改为“已处理”。如果此事务未能提交,事件将保留在 ' pending' 状态。然后,消费者进程可以在重新启动或超时后尝试重新处理所有未决事件。但这种情况只涵盖最简单的情况。不幸的是,消费者的代码不仅可以与本地数据库一起工作,还可以向第三方系统发送一些东西。对于这种情况,从头开始执行整个过程可能是不可接受的,必须单独处理。
在某些文章中,您可以找到另一个选项 — 将消息标识符与由此消息创建或更新的实体一起存储。它应该以类似的方式工作——尝试更新此实体或创建另一个具有相同消息标识符的实体将失败,并且不会再次处理该事件。至于我,我不会推荐这种方法。首先,它混合了两种不同的数据类型:为业务逻辑目标存储的数据和为系统基础设施级别目的存储的数据。它还可能隐藏其他陷阱,尤其是当消费者逻辑很复杂并且不能归结为简单的数据库实体更新时。
选择
如果您有基于日志的消息代理,则可以应用另一种方法。此类代理使用消费者偏移量来确定消费者在事件日志中的位置。在此位置之前的所有事件都被视为已处理,因此下次消费者请求新事件时,它将从其偏移值开始接收它们。尽管如此,问题仍然存在——消费者可以处理事件,但偏移量更新失败。
上图消费者处理事件,但未能更新偏移量
解决方案与我们之前讨论的类似,但是现在消费者不必存储它处理过的所有消息,这里只需要偏移量就可以了。然而,它提出了一个新的任务来思考:这个偏移量仍然应该以某种方式转移给经纪人。例如,Kafka 建议将 Kafka Connect 作为一个选项。
结论
现在,大多数流行和广泛使用的消息代理都提供一些内置功能或至少插件来实现“恰好一次”的传递保证:
1、具有processing.guarantee=exactly_once和exactly_once_v2的 Kafka 流配置streamsconfigs_processing.guarantee>https://kafka.apache.org/documentation/streamsconfigs_processing.guarantee
2、NATS 与 NATS JetStream 的消息去重exactly-once-delivery>https://docs.nats.io/using-nats/developer/develop_jetstream/model_deep_diveexactly-once-delivery
3、RabbitMQ 有一个消息去重插件https://github.com/noxdafox/rabbitmq-message-deduplication
4、Apache Pulsar 事务 API https://streamnative.io/en/blog/release/2021-06-14-exactly-once-semantics-with-transactions-in-pulsar/
不幸的是,几乎所有这些都有一些限制或不能保证消费者只会收到一次消息。这就是为什么在我看来最好有这样一种机制,它允许您控制您的消费者如何处理传入的异步事件,而不是完全依赖您使用的消息代理的实现。