与许多其他产品一样,WeTransfer最初是一个小型单体应用程序,但很快就变成了一个拥有太多责任和贡献者的大型单体应用程序。发布新功能变得越来越困难,技术债务也在增加。这就是为什么我们开始将一些核心逻辑分离到不同的服务中。其中一个模块是计费逻辑。
负责用户支付和订阅的计费模块是我们业务的核心服务之一。自我们第一次实施以来发生了很多变化,并且由于一切都在同一个单体中,计费代码库与其他核心模块(如传输和授权)相结合。
这篇文章将描述我们在不显着影响使用我们产品的 8000 万活跃用户的情况下解耦所有计费逻辑的不同步骤。有许多不同的方法来处理这个项目,但希望我们的学习能帮助您规划您的项目。
阶段 1:解耦单体中的计费逻辑
我们的计费逻辑与单体应用的其余部分耦合度很高,要理解其他模块与计费代码库之间的接口需要付出很多努力。所以我们的第一个方法是解耦单体中的计费逻辑。我们分两部分进行:
- 我们将所有计费类移动到新的文件夹和模块中。所以我们的大多数计费类都带有前缀Billing::(因为代码库是用 Ruby 编写的)。然后我们将我们的团队设置为这些文件夹的GitHub代码所有者,这样我们就会收到所做的任何贡献的通知。我们还借此机会与工程团队的其他成员就我们的计划进行了沟通,并且应该仔细审查任何使用计费模块的新逻辑。例如,我们不想在现有模块和计费逻辑之间添加更多依赖项。
- 我们创建了不同的Client类作为我们想要迁移的计费代码和整体的其余部分之间的中间件接口。这个想法是每次与计费逻辑的交互都需要通过这些客户端之一。例如:
解耦前: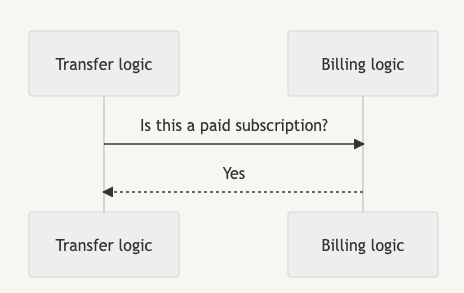
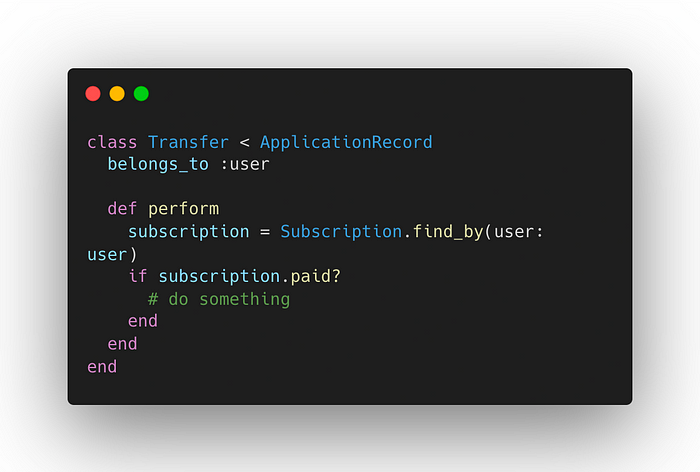
伪代码示例:Transfer直接访问订阅表:
解耦后: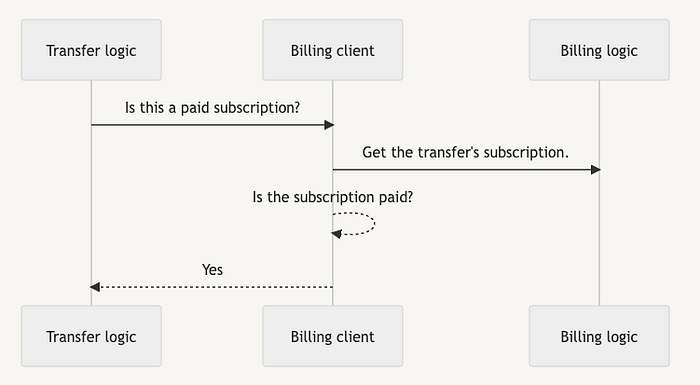
伪代码示例:Transfer通过计费客户端访问订阅:
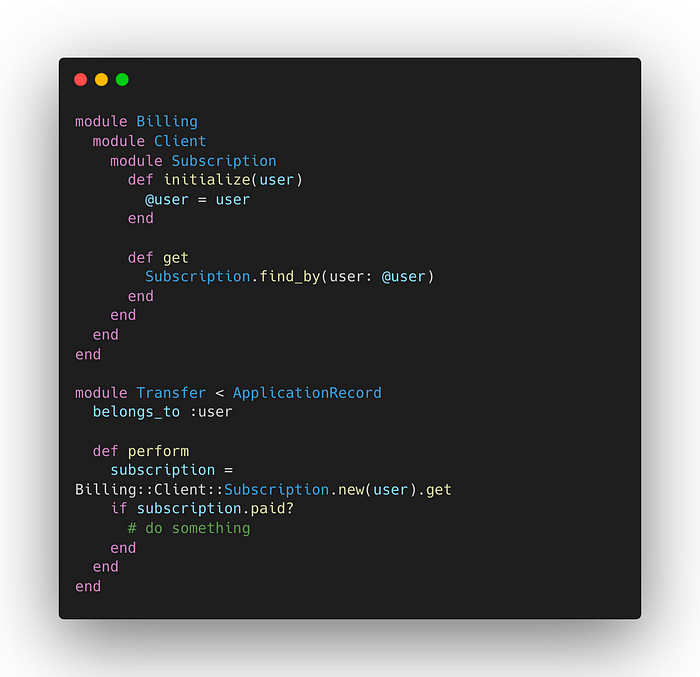
我们使用与 REST API 接口相同的格式编写计费客户端,因为在未来阶段,它将成为新计费服务的接口。在这个新客户端上工作帮助我们了解了新计费服务所需的每一次交互。我们也可以开始考虑我们需要解耦的更复杂的事情。这给了我们一个清晰的计划,说明我们必须与其他团队讨论的事情,并允许我们开始研究我们希望每个团队在未来使用的 API 规范。
在项目开始时,我们需要做很多工作才能了解完整的范围,因为代码库中有许多我们需要熟悉的模块。在这个阶段之后,范围得到了更好的定义,大部分代码已经在单体中解耦,前面的挑战也很明显。我们已准备好开始开发新的计费服务。
第 2 阶段:加入新的计费服务:Billy
计费逻辑包含四年多的开发,因此重写所有内容不在范围之内。为避免这种情况,我们使用git submodules. 我们的新代码库有一个包含所有单体文件的文件夹。这使我们能够首先专注于编写控制器,同时能够调用现有的类。
我们还决定重用与单体数据库相同的数据库。我们知道,一旦我们开始从事这个项目,我们就需要尽快清理单体中的代码;否则,它可能会延迟依赖它的其他项目。所以我们的重点是首先准备好 API,然后我们将专注于 Billy 中的实际代码和数据库。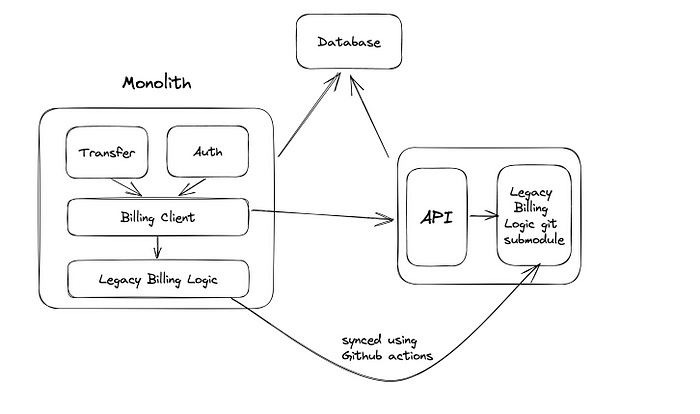
上图新的计费服务架构与整体共享数据库并使用 git 子模块
一旦设置准备就绪,我们就开始重构单体中的计费客户端,以便对 Billy 进行 HTTP 调用: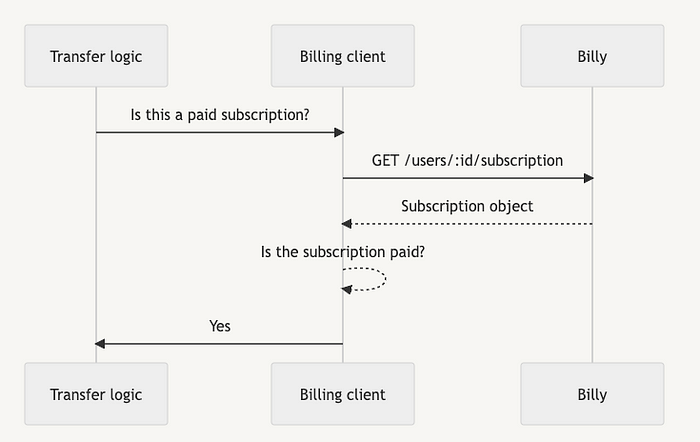
伪代码示例:重构计费客户端以对 Billy 进行 HTTP 调用。传输逻辑没有改变: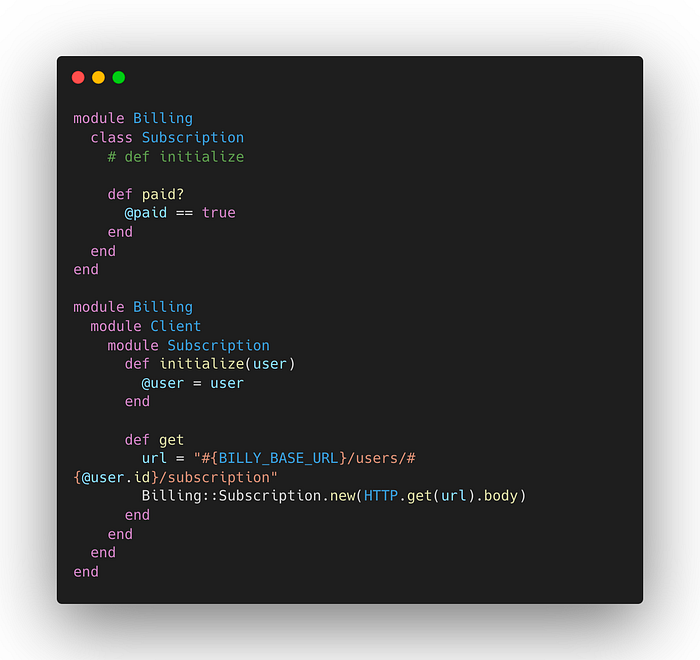
功能标志和监控
一旦最终确定了一些端点,就该开始将它们发布到生产环境中了。由于这些端点对其余产品至关重要,因此必须避免停机并制定回滚策略以防出现任何问题。为此,我们依靠功能标志允许我们对某些用户进行百分比部署,并在有任何未按预期工作时回滚。
我们需要一个良好的监控设置来了解事情是否按预期进行。我们将Datadog用于我们的所有服务,使我们能够监控基础设施指标并跟踪我们产品的踪迹。我们可以很容易地跟踪 Billy 的传入吞吐量以及其他服务的处理情况。
- 延迟是否可以接受?
- 我们的断路器是否按预期工作?
- 单体是否正确处理错误响应?
第 3 阶段:清理
一旦端点被实现并投入生产,我们就可以删除 git 子模块并将文件从单体移动到 Billy。对于某些文件,它只是复制粘贴;对于其他人来说,这是进行改进的绝佳机会。有些改进不可能立即解决,因此我们创建了一个Jira Epic,其中包含我们希望在完成解耦项目后处理的不同内容。这已经显示了在单体之外拥有计费逻辑的优势。突然之间,一些听起来很难实现的想法变成了我们可以在新代码库中快速实现的东西。
到这个阶段结束时,单体中将不再有计费文件,它们现在都将存在于 Billy 中,并具有新的名称、接口、测试套件和文档。
阶段 4:数据库拆分
Billy 是一个独立的服务,但我们仍然使用单体数据库,作为第一种方法效果很好。但是,我们依赖于他们的迁移过程;任何事件或停机时间仍可能影响我们。
我们使用AWS Database Migration Service进行了迁移,这使我们能够将表从整体同步到 Billy 的新数据库,这意味着我们将在两个数据库中拥有相同的数据。我们所要做的就是切换我们的服务以指向新数据库。在切换之前,我们停止了所有 cronjob 或后台作业并禁用了写入以确保我们没有遗漏任何数据。我们计划在一天中的低吞吐量期间,并且由于仍然可以进行读取,因此影响很小,在切换后成功恢复。
学到的
- 如果有的话,请依赖回归测试。由于在解耦期间不应影响任何功能,因此产品中的任何回归测试都应该通过。
- 定期与您的团队一起检查,并将您的挑战作为具有明确行动要点和范围的小计划进行跟踪。
- 在此过程中,您会发现许多改进和重构。确保你跟踪那些以备后用。这是去耦的一大胜利,所以使用它。在重构期间,您可能会想着手解决这些问题,这对于小事情来说可能没问题,但要小心范围蔓延,这可能会导致分心和延迟。
- 如果需要回滚,则必须在单体和 Billy 中实现一些功能。这很耗时,因此必须快速从整体中删除该代码并 100% 依赖 Billy。
- 在重写期间,测试需要大量工作来维护。不要低估它可能需要的时间;有一个明确的策略来保持简单,以避免修复您将不得不重写的测试。
- 如果您有另一个不太重要的客户端使用您的 API,请先集成并测试它。我们使用仅在内部使用的管理工具来完成此操作。
我们本可以做不同的事情:
- 我们低估了其他团队所需的努力,而且我们开始进行一些对话的时间太晚了。例如,在我们切换到新数据库之前,数据团队需要修改他们的管道。我们在项目结束时解决了这个问题,在最后阶段造成了一些障碍。
- 我们快速交付了一些重构,而没有花时间准备评估一切是否仍在正常运行所需的指标。我们本可以事先设置指标,以便在发布后发现任何异常情况。
- 在项目开始时,我们可以定义较小的里程碑,以防项目被搁置。当范围更清晰并且事情更容易估计时,在项目的后期更容易做到这一点。
结论
一个大的解耦项目需要大量的计划、时间和投资,而且对企业来说好处并不总是显而易见的。此外,如果代码库太大并且您的团队不熟悉所有移动部分,很多事情都可能出错。你会发现很多障碍,你需要确保找到一个很好的解决方法才能成功;否则,几个月的工作可能会永远搁置。
在我们的案例中,该项目花费的时间比最初计划的要长,但它是成功的。这些是我们可以衡量的主要好处:
- 32918+ 行代码从单体中删除并在 Billy 中重构。这意味着在单体应用中引入新功能要容易得多,耦合度更低,并且更容易理解如何与计费逻辑交互。
- 我们团队的生产力:CI/CD 现在对我们来说快了四倍。由于我们的新服务的贡献者较少,因此发布和回滚新功能也容易得多。这也是改善我们的开发体验的绝佳机会。我们可以实施三年来积压的改进。
- 可用性:单体中的事件不再影响我们的计费。我们还可以更轻松地从新版本引起的任何事件中恢复,并实施特定于 Billy 的 SLO。
当然,当您在同一服务上运行所有内容时,诸如延迟之类的事情可能会好很多,但在这种情况下,解耦服务被证明是一种很好的方法,我们采用的方法对其成功至关重要发生。如果您发现自己处于相同的情况,我希望我们的一些经验对您有所帮助!