伪共享False sharing说明JVM底层技术也不让人那么放心。
内存缓存系统中基本单元是高速缓存行(Cache lines). cpu会把数据从内存加载到高速缓存中 ,这样可以获得更好的性能,高速缓存默认大小是64 Byte为一个区域,一个区域在一个时间点只允许一个核心操作,也就是说不能有多个核心同时操作一个缓存区域。
因为高速缓存是64字节,而Hotspot JVM的对象头是两个部分组成,第一部分是由24字节的hash code和8字节的锁等状态标识组成,第二部分是指向该对象类的引用。基本类型字节如下: doubles (8) and longs (8) ints (4) and floats (4) shorts (2) and chars (2) booleans (1) and bytes (1) references (4/8)
因此,一个高速缓存64字节可以放下多个字段,如果这多个字段位于同一个高速缓存区,虽然它们是类的不同字段,如下代码:
Class A{
int x;
int y;
}
|
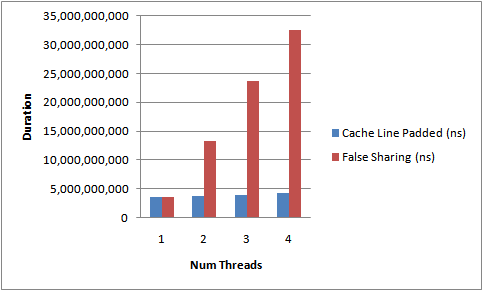
虽然两个线程修改各种独立变量,但是因为这些独立变量被放在同一个高速缓存区,性能就影响了。测试结果如后面。
当多核CPU线程同时修改在同一个高速缓存行各自独立的变量时,会不自不觉地影响性能,这就发生了伪共享False sharing,伪共享是性能的无声杀手。
解决方便是将高速缓存剩余的字节填充填满(pad),确保不发生多个字段被挤入一个高速缓存区,下面测试结果图就是和填充后性能比较。
实现字节填充的框架有 Disruptor,在RingBuffer中实现填充。关于Disruptor可见infoQ这个视频,用1毫秒的延时得到100K+ TPS吞吐量,JDK的ArrayQueue并行环境不见得是最快的,该视频后面讨论很多,让人大跌眼镜啊,开放源码多有好处啊,别人能发现你不能发现的漏洞。另外一篇解剖Disruptor
C#也有类似伪共享发生,见这里 [该贴被banq于2011-09-01 09:21修改过]