性能主题
线程池与ForkJoin比较
JDK 7已经发布,大多数人都听过ForkJoin的,但没有那么多时间或机会在日常工作中尝试一下。对比通常的线程池有什么不同?
下面看一下使用线程池作为任务的代码:TaskProcessorPool.java,使用的是ExecutorService:
public class TaskProcessorPool extends AbstractTaskProcessor {/*** 4 threads for a 4 core / 4 threads system 四个线程对应四核CPU*/public final int POOL_SIZE = 4;/*** Thread pool*/private ExecutorService threadPool;public TaskProcessorPool(TaskSolver taskSolver) {super(taskSolver);threadPool = Executors.newFixedThreadPool(POOL_SIZE);}@Overridepublic void process(Task task) {// As soon as we have a task we submit it to the threadpoolthreadPool.submit(new TaskRunnable(task));}@Overridepublic void shutdown() {threadPool.shutdown();}/*** Runnable solver for a task*/class TaskRunnable implements Runnable {/*** Task to be solved*/private Task task;public TaskRunnable(Task task) {this.task = task;}@Overridepublic void run() {taskSolver.solve(task);taskSolver.getTaskResultHandler().taskDone(task);}}}
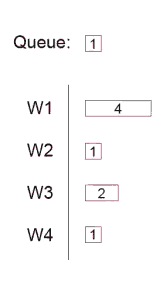
代码中设置了一个有4个worker池,当我们有一个任务需要实现,将它添加到队列Queue中。当线程池中有worker是可用的时候,就会从队列中获得那个任务并执行它。
线程池的大小设定也是有讲究的,假设这个线程池使用率是56%,也就是满负荷是16,我们使用了9个线程,这样不至于堵塞。
Fork Join
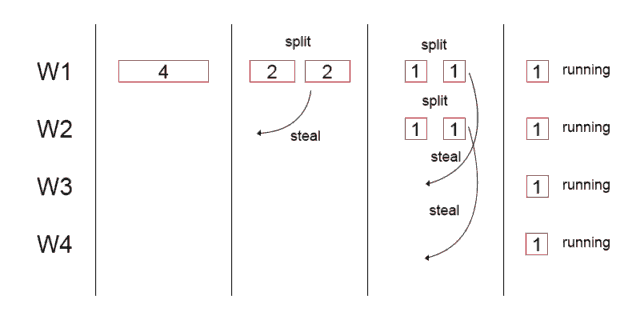
Forkjoin 只有你在将一个任务拆分成小任务时才有用处。fork-join池是是一个work-stealing工作窃取线程池。每个工作线程维护本地任务dequeue。
当执行新的任务时它可以将其拆分分成更小的任务执行,如果它是足够小,但是dequeue没有本地线程了,它的会“偷”,从一个随机线程的队列中偷窃一个并把它放在自己的队列中。但是如果任务还没有拆,他还是得完成手上一些工作。
相较于线程池,Forkjoin池里的线程不是在是等待新任务,而是主动分裂的现有任务到更小的,并帮助完成其他线程的大任务(切分以后)。
这里是Doug Lea原始论文的更详细的解释: http://gee.cs.oswego.edu/dl/papers/fj.pdf
下面看看我们的forkjoin池:TaskProcessorFJ.java
/*** This is a Fork / Join processor for tasks, using a ForkJoinPool** At the processing step it will split the task into subtasks until it reaches a threshold* Once the threshold is reached it will solve the subtask** @author florin.bunau*/public class TaskProcessorFJ extends AbstractTaskProcessor {/*** Work stealing thread pool implementation*/private ForkJoinPool forkJoinPool;public TaskProcessorFJ(TaskSolver taskSolver) {super(taskSolver);forkJoinPool = new ForkJoinPool();}@Overridepublic void process(Task task) {// Give the pool a subtask to solve. At the beginning task == subtaskforkJoinPool.invoke(new Subtask(task, 0, task.getOperations().size(), true));}/*** Wraps a task to be solved, and restricts it's extend to a subtask.** Also implements a FJ recursive action, that will split the subtask into two smaller substasks* if it's above a specified threshold*/private class Subtask extends RecursiveAction {private static final long serialVersionUID = 1L;/*** Task to be solved*/final Task task;/*** Limit the task from operation having index 'from'*/final int from;/*** to operation having index 'to'*/final int to;/*** Is this subtask == the initial task*/final boolean rootTask;public Subtask(Task task, int from, int to, boolean rootTask) {this.task = task;this.from = from;this.to = to;this.rootTask = rootTask;}@Overrideprotected void compute() {// If the subtask size is smaller than an L task. ( XS, S, M ), then go ahead and solve itif (to - from < Task.TaskType.L.getRange()) {taskSolver.solve(task, from, to);}// If it's same or larger ( L, XL, XXL ), we will break it into two smaller substasks and solve it laterelse {int mid = (from + to) / 2;invokeAll(new Subtask(this.task, from, mid, false),new Subtask(this.task, mid + 1, to, false));}// We're done solving the subtask, if it's the initial task, then signal that we are done solving the taskif (rootTask) {taskSolver.getTaskResultHandler().taskDone(task);}}}}
大多数问题具有线性序列的操作,我们需要使用一个专门的并行算法以便充分利用我们处理器多个内核。切分到多少才合适呢?一般切分到一个阈值,再切分下去就没有意义的了。
例如: (切分一个任务导致线程获得上下文切换机会要超过实际执行它)对于一个大XXL 任务,我们要做1000000查询操作。我们可以拆分成2 500000操作任务,并做平行。 500000仍然较大?是的,我们能再切分。我选择了一组10000操作作为门槛,再往下分裂没有用了,我们可以在当前线程上直接执行它们。Fork Join并不做切分这些前期工作。
性能对比:
TaskProcessorPool: 3933
TaskProcessorPool: 2906
TaskProcessorPool: 4477
TaskProcessorPool: 4160
TaskProcessorFJ: 2498
TaskProcessorFJ: 2498
TaskProcessorFJ: 2524
TaskProcessorFJ: 2511
结论:ForkJoin池要比普通线程池快。