数据科学教程
Python中数据可视化三种方法

数据可视化是机器学习的关键阶段。要完全理解数据的行为和特征,您必须首先将其可视化。 Python 提供了不同的数据可视化库。1、使用 TuriCreateTuricreate 是 Python 提供的.
Python中用NumPy创建自己的通用函数
NumPy 是 Numerical Python 的缩写,是用于临床计算的 Python 环境中的基础库。它为运行大型多维数组和矩阵提供帮助,并提供广泛的数学功能以成功地对这些数组进行操作。NumPy.
Instagram短视频如何实现推荐系统?

社交媒体已成为沟通和娱乐的主要平台,需要不断寻求创新方式来保持用户的参与度和娱乐性。Instagram 是领先的社交媒体平台之一,有一个名为 Instagram Reels 的关键功能,这是一种短视频.
数据科学家学习100个SQL查询教程

点击标题 适合非计算机专业的其他领域专家通过数据获得见解。目标受众 Rachel 拥有细胞生物学硕士学位,现在在一家研究医院从事细胞分析工作。 她在本科生生物统计学课程中学习了一些 R 语言,并完成了.
Python矢量化编程

在传统的编码领域,Python 的矢量化成为一股改变游戏规则的力量。虽然循环长期以来一直是重复性任务的主力,但请将它们视为我们代码中可靠的工人蚂蚁。现在,进入 Python 的矢量化——超级英雄准备取.
使用谷歌Gemini Pro的Bard实现数据处理自动化

使用 Gemini Pro 的 Bard 已在 Arena 上超越了 GPT-4。将它与 Google Sheets 结合使用,可实现数据处理自动化。我将向你展示如何使用 Bard 管理电子表格,而无.
2024年20大数据科学工具

企业数据变得越来越具有挑战性,并且由于它在战略规划和决策中发挥着关键作用,组织被迫在从数据资产中提取有用的业务洞察所需的人员、程序和技术上投入资金。当我们深入研究 2024 年时,数据科学工具的前景已.
什么是句子嵌入、交叉编码器和重新排名

深入探讨嵌入并解释双编码器和交叉编码器之间的差异,然后,我们将深入研究检索和重新排名。什么是双编码器和交叉编码器?Sentence Transformers 支持两种类型的模型:双编码器和交叉编码器。.
Python中十大数据科学顶级库介绍
当我们了解不断发展的Python开发环境时,是时候再次关注今年引起我们注意的杰出库和工具了。1. Lite LLM — 调用任何使用OpenAI格式的 LLM 等LiteLLM 直观且非侵入式的设计允.
什么是遗传算法
遗传算法 (GA) 是更大类别的进化算法 (EA) 的子集,是计算机科学和运筹学中使用的一种元启发式算法,其灵感来自于自然选择的过程。遗传算法经常采用受生物学启发的算子,包括变异、交叉和选择,以产生优.
每个初学者都应该知道的 50 个人工智能术语

看到一个技术术语而不理解它的含义是很常见的。随着人工智能极其先进并日益进步,如果您与人工智能或任何技术工作没有直接关系,一些人工智能术语并不容易理解。因此,即使你是一个想要学习一些基本术语的初学者,或.
机器学习工程师必须具备的 10 项技能

在本文中,我们将探讨机器学习工程师必备的 10 项技能。什么是机器学习在机器学习中,计算机从数据中学习并根据该数据做出预测。就像我们用例子教孩子一样,就像我们用例子教计算机算法一样。在这个领域,我们检.
如何成为一名数据顾问?

您是否想知道谁解释了大量的全球数据并将其转化为企业可以使用的见解?这些是数据顾问,所以不要在其他地方搜索。这些专业人员利用他们的专业知识来指导组织应对数据分析的复杂性,帮助他们在信息泛滥的时代做出明智.
Marimo:Python开源反应式笔记本notebook
marimo 是 Python 的反应式笔记本notebook 。它允许您快速试验数据和模型,对笔记本的正确性充满信心地进行编码,并将笔记本生产为管道或交互式 Web 应用程序。 在 marimo 中.
为什么最简单的解释并不总是最好的

该文章讨论了降维方法在解释高维数据时的局限性。主成分分析(PCA)是一种常用的降维技术,但它可能会错过数据中存在的结构或产生幻觉的结构。作者通过示例说明了当应用PCA于时间或空间平滑信号时可能出现的振.
使用一个深度学习 pCTR 模型分析广告效果
在 Instacart Ads,我们的重点在于向客户提供最具相关性的广告,促进新颖的产品发现并增强他们的杂货购物之旅。同时,我们努力通过提高品牌认知度、增加产品销量和扩大客户范围来为广告商提供价值。在.
Java和Python中的目标堆栈规划实现
目标堆栈规划是一种简单高效的人工智能规划算法,用于解决复合目标问题。它的工作原理是**将总体目标分解为更小的子目标,然后以向后的顺序逐一解决它们。让我们考虑一个简单的例子来说明目标堆栈规划。想象一下你.
什么是数据挖掘交易
数据挖掘交易(Data mining trading 简称DMT)是指使用先进的数据分析技术从金融市场的大型数据集中提取有价值的见解和模式,然后应用这些见解来为交易决策提供信息。这就像筛选一座沙山来寻.
分层随机抽样——概述

分层随机抽样是一种用于机器学习和数据科学, 从大量群体中选择随机样本用于训练和测试数据集。当总体不够大时,随机抽样可能会引入偏差和抽样误差。分层随机抽样可确保样本充分代表整个总体。分层随机抽样通过将总.
迭代与递归比较

迭代和递归方法都是编程和算法设计中常用的问题解决技术。虽然他们最终实现了相同的目标,但他们的方法不同。选择正确的方法取决于具体情况和您想要的结果。迭代: 想象一下一次一步地爬楼梯。您循环执行相同的操作.
经典频率统计和贝叶斯统计之间关系

经典频率统计和贝叶斯统计之间存在微妙关系,特别是在 p 值和贝叶斯后验的背景下。关键点:古典频率论者:P 值: 在经典频率统计中,p 值通常用于评估反对原假设的证据。 p 值是对原假设证据强度的衡量。.
什么是财务建模以及如何构建它?
财务建模被定义为开发数学模型或企业财务表示的过程。它涉及使用电子表格、许多金融工具和定量方法来预测和分析公司的财务业绩。财务建模的主要目标是在深入了解各种情况的财务后果的基础上做出明智的公司决策。财务.
量化行业为啥看不起计算机科学博士?相比统计/数学博士
这在很大程度上取决于你面试的公司和团队。如果你是侧重于低延迟编程/GPU/FPGA 的 CS 博士,HRT 或任何 HFT 团队都会要你。2Sig 喜欢人工智能/ML(如模式识别、数据挖掘、DL、RL.
Rows.com:AI驱动的免费Excel
AI 刚刚杀死了 Excel。 不再有复杂的公式和长达 10 小时的 视频教程来学习Excel了。Rows.com 是 Excel 的 AI 版本:(100% 免费!):1.导入数据导入数据 - 文件.
新研究:AI加速复杂上下文中的问题解决

研究人员开发了一种新的数据驱动的机器学习技术,可以加速用于解决复杂优化问题的软件程序,这些问题可能有数百万个潜在的解决方案。他们的方法可以应用于许多复杂的物流挑战,例如包裹路线、疫苗分发和电网管理。问.
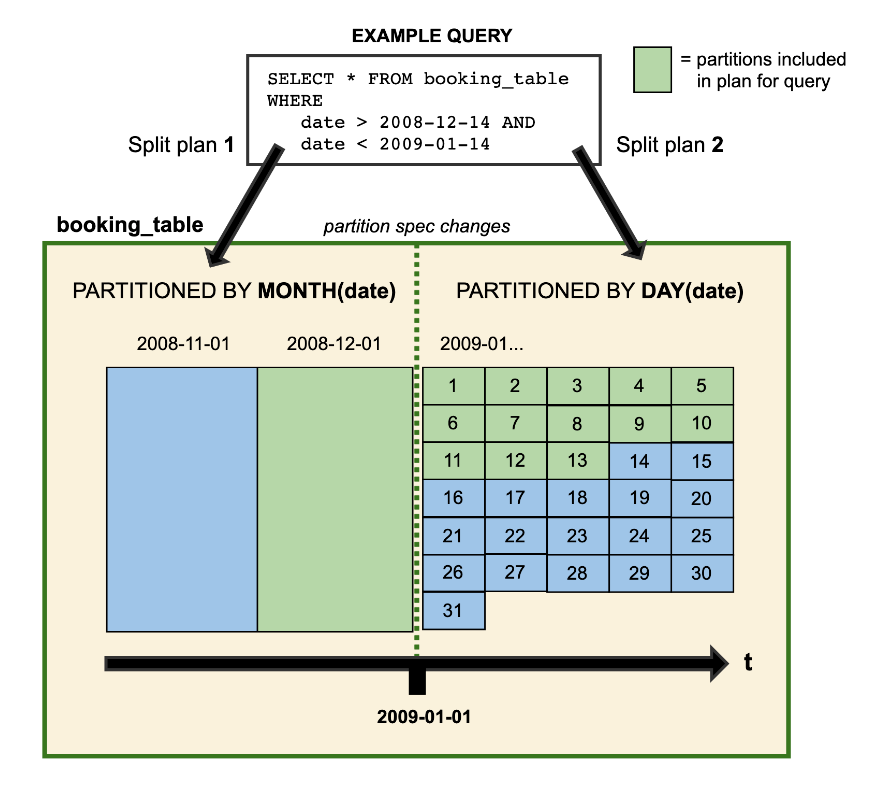
什么是开放表格式OTF?
认知哲学名词术语定义表

以下是认知和人工智能以及数据科学中常涉及的哲学术语:意识:意识这个词有十几种常见用法,而且都很有趣。常识包括:自我意识、语言认知和驾驭环境的能力。这个词的含义往往是:体验的事实,体验的存在,并且感觉像.
大模型 + 矢量数据库 + Kafka = 实时 GenAI
Apache Kafka 作为机器学习基础设施的关键任务且可扩展的实时数据结构为数千家企业提供服务。生成式人工智能 (GenAI) 与 ChatGPT 等大型语言模型 (LLM) 的发展改变了人们对智.
米其林、汉莎航空使用Kafka数据流的案例
售后销售和客户服务需要在正确的时间获得正确的信息来做出针对具体情况的决策。使用 Apache Kafka 进行数据流处理可实现真正的解耦、领域驱动设计以及跨实时和批处理系统的数据一致性。共同的业务目标.
Python中Pandas矢量化基础操作简介
在数据科学中,处理大型数据集时,效率和速度至关重要。在这方面脱颖而出的一个库是 Pandas,它是一种用 Python 构建的高级数据操作工具。经常讨论的一个关键功能是操作的矢量化(向量化),这本质上.