有一篇曾经被TSS推荐的关于分布式事务的课程博客:
http://natishalom.typepad.com/nati_shaloms_blog/2007/08/lessons-from-am.html
可惜这个网站被大陆封了,所以,很精彩文章看不见,我转载如下,希望给大家对分布式事务有一个很重要认识,分布式事务关系到大访问量下的数据安全,不重视,就会发生ATM机吐钱的臭事,我们程序员最好丰富自己知识以后,再根据情况决定使用,问问你的客户:给你做的这个软件系统可能有1%可能发生类似ATM吐钱事件发生,让你的客户搞定法律,让碰到这个1%的倒霉用户判它一个无期。世界就清净了。
Lessons from Pat Helland: Life Beyond Distributed Transactions
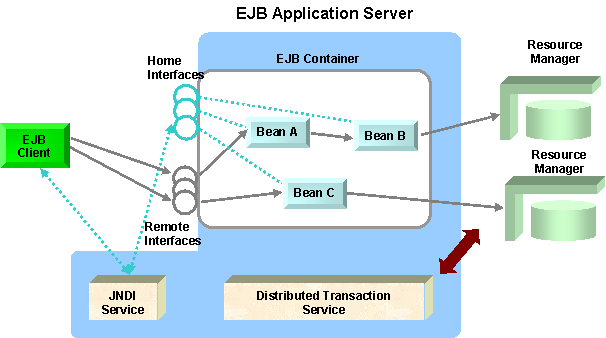
Distributed Transactions are a common pattern used to ensure ACID properties are met between distributed resources. Since the late 70s, the fIrst generation of this model has been widely used in many large-scale applications that struggle with the difficulties of multiplexing many online terminals. This led to the emergence of the 1st generation TP Monitors (TPMs), such as Tuxedo (Now owned by BEA). The emergence of web based applications in the late 90s drove the creation of 2nd generation TPMs, in the form of JEE application servers, to address similar needs using more open and modern technologies as described in the following article by Subbu Allamaraju: Nuts and Bolts of Transaction Processing. The diagram below illustrates a typical transaction flow in a JEE environment:
Transactions in EJB Application Server
(Source: Subbu Allamaraju, Nuts and Bolts of Transaction Processing)
The increased business demand for greater scalability led many to the realization that the current transaction model is a bottleneck due to its inherit centralized approach. It also makes our systems quite brittle and complex due to the tight coupling that it introduces, as described in a paper by Pat Helland of Amazon.com: Life beyond Distributed Transactions: an Apostate’s Opinion:
Today, we see new design pressures foisted onto programmers that simply want to solve business problems. Their realities are taking them into a world of almost-infinite scaling and forcing them into design problems largely unrelated to the real business at hand. Unfortunately, programmers striving to solve business goals like eCommerce, supply-chain-management, financial, and health-care applications increasingly need to think about scaling without distributed transactions. They do this because attempts to use distributed transactions are too fragile and perform poorly.
This challenge leads us to the emergence of a third generation of TPMs, or what Gartner calls Extreme Transaction Processing (XTP).
What approaches are people taking today to overcome the limitations of previous generations? From Pat:
"..Because the performance costs and fragility make distributed transaction impractical. Natural selection kicks in,... applications are built using different techniques which do not provide the same transactional guarantees but still meet the needs of their businesses"
So the question is how to achieve high transactional throughput and performance without compromising consistency and reliability?