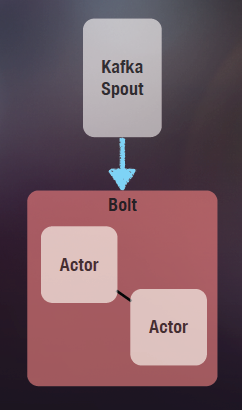
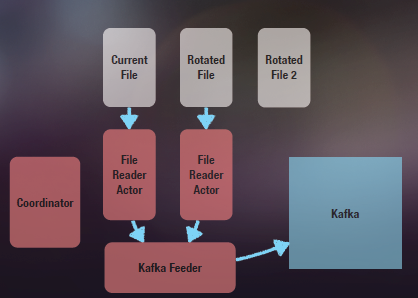
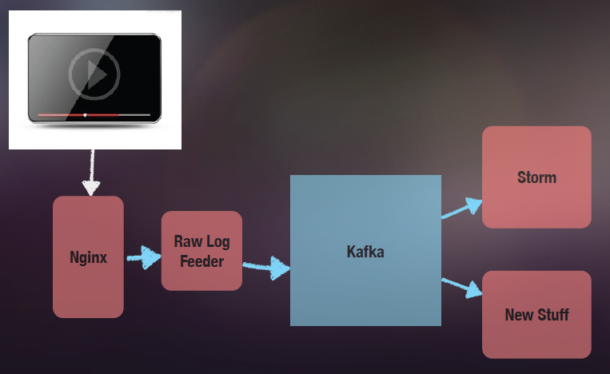
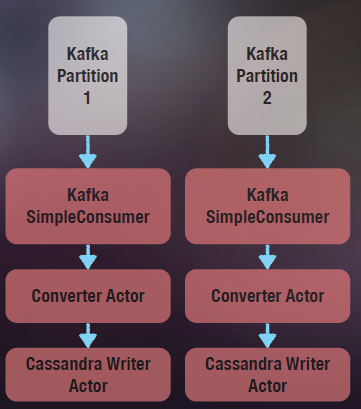
缺省Actor的邮箱大小是没有限制
•但是用一个固定大小的邮箱
• 当邮箱满了,发送消息到DeadLetters
• mailbox-push-timeout-time: 当邮箱满了要等待多长时间?
• 对于分布式Akka系统无用。
真正流程控制:拉 pull, 带确认的推
• 分布式也能行,但是需要付出劳动。
一个流程控制系统能使Actor组件的处理率(每秒处理多少消息)达成一致。
这段流程控制具体如何实施从原文无法详细得到,其控制代码:
trait TrakkarExtractor extends TrakkarBase with ActorStack {
import TrakkarUtils._
val messageIdExtractor: MessageIdExtractor = randomExtractor
override def receive: Receive = {
case x =>
lastMsgId = (messageIdExtractor orElse randomExtractor)(x)
Collector.sendEdge(sender, self, lastMsgId, x)
super.receive(x)
}
}
|
Trait 发送一个Edge(source, dest, messageInfo) 到本地Collector actor,这个聚合的edges是跨节点拓扑的。
最后他总结了akka开发经验:
不要把东西放入 Actor 构造器,如果出现这种情况,注意:
• 缺省的 supervision 策略会停止一个没有初始化的Actor,
• 用一个初始化消息替代在构造器中初始化。
把这个消息和Actor放在一起,一个命名空间最好。
最后实现一个Actor的日志 性能度量 和流程跟踪的代码:
trait InstrumentedActor extends Slf4jLogging with ActorMetrics with TrakkarExtractor
object MyWorkerActor {
case object Initialize
case class DoSomeWork(desc: String)
}
class MyWorkerActor extends InstrumentedActor {
def wrappedReceive = {
case Initialize =>
case DoSomeWork(desc) =>
}
|