Netflix分享Node.js性能调优
Netflix最近分享了它们使用Node.js建设新一代Netflix.com的Web应用过程中的性能调优心得
首先注意到的是Node.JS的请求延迟,JS应用程序随着时间增加,其耗费CPU也是超预期的,称为燃烧CPU,从而带来了高延迟。不断重启作为临时解决方案,然后在Linux EC2使用新的性能分析工具迅速找到问题根源。
具体来说,一些端点服务器会有1毫秒延迟,并且随着每小时增加10ms,同时还看到CPU使用量增加:
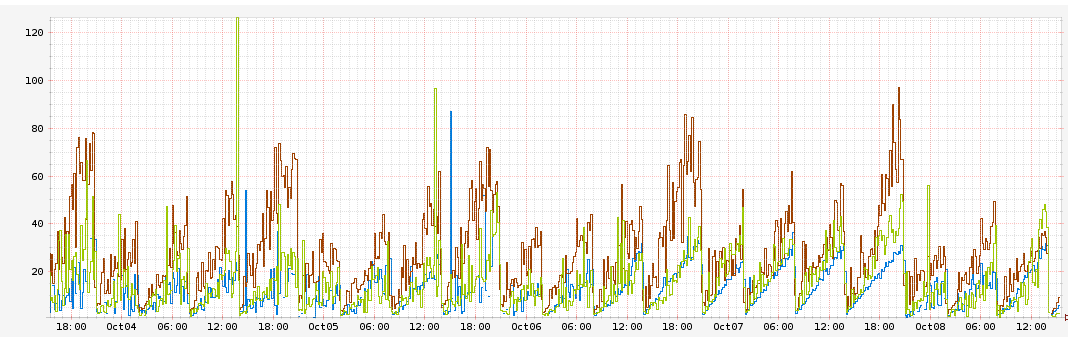
该图为每个地区的请求延迟发生时间,每种颜色对应不同AWS,你可以看到延迟每小时稳步递增10ms,峰值大概在60ms。
最初推测,自己的请求处理程序可能有一些错误,比如内存泄漏导致延迟。 我们隔离测试了应用程序,js堆大小增加到32 gb,添加了对应用程序对每个请求处理的延迟和总体请求延迟等指标测量。
我们看到应用程序对每个请求处理的延迟一直保持不变,进程堆的大小也基本保持不变,大概是1.2GB,但是总体请求延迟和CPU使用率在上升。这就撇清了我们自己的应用程序的责任,将问题根源指向堆栈等更深层次。
一些服务会额外需要60ms,我们需要CPU消耗使用率的校验调校虚拟图即火焰图。
对于那些不熟悉火焰图,最好读布兰登格雷格优秀的文章,这里进行大概总结:
1.每个框代表一个在堆栈(堆栈帧)中的函数
2.y轴显示堆栈深度(堆栈上的帧数),顶部框显示了占据cpu的函数。 而下面的一切都是起源。 下面的函数是上上面函数的“父母”,就像前面所示的堆栈跟踪。
3.x轴跨越样本标本。 它不像大多数图那样显示从左到右时间的流逝, 从左到右排序没有意义(这是按照字母顺序排列)。
4.框宽度显示对CPU使用时间,宽框代表的函数慢于窄框代表的函数。
5.如果采取多线程并发运行和取样,取样数量会超过运行时间。
6.颜色不重要,这里随机选择暖色,代表CPU有多热。
下面这张JS火焰图是使用DTrace取样得到,取样方法见:Profiling Node.js,,Google v8团队最近添加perf_events支持v8,它允许在Linux上采取的JavaScript堆栈分析。 Node.js 0.11.13版本支持,具体细节参考:node.js Flame Graphs on Linux。
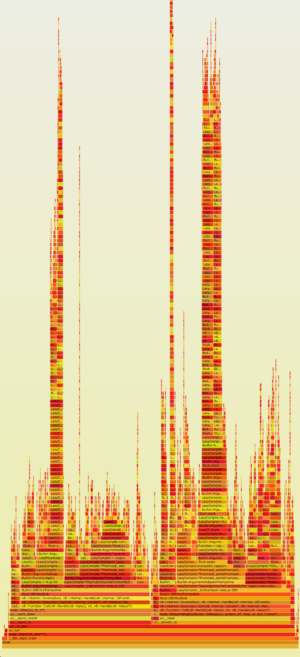
这里有火焰图的原始SVG,我们看到应用程序达到最高的栈见Y轴,而从X轴看到也在这些栈花费了很多时间,堆栈帧stack frame是由所有指向Express.js的路由器处理router.handle和 router.handle.next 函数。Express源码有一些有趣的特点:
1.路由处理程序将所有端点保存在一个全局的数组中。
2.Express采取递归遍历直至找到正确路由处理器并调用处理器。
{kind=link}
全局数组不是理想的数据结构,不知Express为什么不采取一个时间不变的数据结构如map来存储它们的应用处理器,每个请求都需要昂贵的O(n)查找数组路线,更有甚者,数组是递归遍历,这就解释了为什么我们看见如此高高堆起的火焰图。
最要命的是Express.js允许你为同一个路由设置相同的路由处理器,你可以设置一个请求链(banq注:职责链模式确实浪费性能)。如下:
[a, b, c, c, c, c, d, e, f, g, h]
里面有四个相同处理器C,程序会在数组中第一个C出现的位置终止,而d处理器只会在数组位置6地方结束,就不必要花费时间跨越a b和多个c了,下面通过应用验证:
|
上面增加两个相同的路由/foo。运行堆栈信息是:
|
这里有两个相同的路由处理器,当路由处理链中出现两个相同的处理器时JS会抛出错误。
这也解释了随着时间增加延迟增加的原因,最有可能的泄漏是在我们应用代码中,出现了相同重复的路由处理器,添加额外日志观察路由处理器数组,发现每小时增加10个处理器元素,这些处理器都是相同的。
|
添加相同的Express路由, js一个小时会增加10倍处理时间。 进一步的基准测试显示仅仅是遍历每一个处理程序实例成本约1毫秒的CPU时间。 这解释了为什么响应延迟每小时增加10 ms。
当我们停止增加相同的路由处理器以后,延迟和CPU耗费陡然就下降了。最后问题解决了。
[该贴被admin于2014-11-20 22:26修改过]