建立机器学习实战系统的十大经验教训
这是来自Netflix机器学习系统的构建经验,Netflix是机器学习应用实战的先驱之一,曾经设立百万奖金用于奖励影片推荐系统算法。最近他们又公布了在机器学习系统的十大经验教训,下面大意翻译一下:
有很多很好的介绍机器学习的教科书和课程,,甚至可以学习一些最复杂的特定的方法或算法,理解这些理论是一个非常重要的基础和起点。还有很多构建真实系统的实际问题,你可能闻所未闻。这篇文章将分享一些Netflix多年来构建大型系统放的最重要的教训,Netflix是跨许多国家支持数以百万计的用户规模。(Netflix是在线视频网站,每晚视频流量占据全美互联网流量近1/3,是亚马逊云计算的大用户。)
1.更多数据 对战 更好的模型
有很多文章已经指出获得更好的结果的关键是改善你的算法,或将更多数据用于训练你的模型。
尽管很多团队试图为模型添加额外功能以提高结果,但是没有什么进展,时隔一年以后,他们发现增加一些元数据能提高微调得很好的算法的预测精确性,有许多增加更多数据的途径,Netflix是通过增加特征的数量和类型,这样能够提高问题空间的维度,以完全不同的方式增加数据填满空间维度,然后简单地再扔给更多样本训练即可。
谷歌也曾经说:Google并没有更好的算法,只是有更多数据而已。
确实,更多数据能够形成更多训练样本,这真的行吗?其实不一定是真的,带有巨量特征的复杂模型会导致"high variance",但是在大多数情况下这还是有用的,在真实的Netflix应用场景中,增加超过2百万的训练样本几乎没有什么效果。
这就形成了我们的第一个教训,其实不是关于更多数据对决更好算法,这样的二分法是错误的,有时,你需要更多数据,有时你并不,也需要提高你的算法,有时两种没有什么区别,专注于一个则另外一个会离优化越远。
2.你并不需要所有的大数据
这个教训其实前面配套,但是值得在这里明确一下,今天,每个人似乎都需要他们的所有大数据,大数据被大量宣传,好像如果你不使用巨量数据你就做错了,事实是有许多问题你只要是少得多的数据会得到类似的结果。
想想Netflix Prize,你有0.5M用户数据集,这个数据集可以用于计算50因素的矩阵,如果使用50M而不是0.5M结果会发生很大不同吗?可能不会。
一个重要问题是如何决定你使用的数据子集?一个好的初始目标是随机从原始数据中取样,满足模型训练,以Netflix Prize为案例,用户是非常不同,表现非同质化,新用户,并没有多少等级,在数据集增加得比较稀少,而另外一个方面,他们也许有不多于老用户的行为,我们要让我们的模型捕获它,解决方式使用 stratified sampling某种形式,设置一个好的stratified sampling的Schema并不容易,因为它需要我们定义不同的strata,决定什么是样本用于训练模型的好的组合,一个定义良好的stratified取样子集也许比使用原始完整数据集更好。
Netflix认为更多数据好于更好的模型,一些学生通过添加来自IMDB元数据改进了Netflix的推荐结果。
当然不是说有很多数据是坏事,你有更多数据,你就有更多选择如何使用它们.
3.更多复杂模型虽然无济于事但不代表你一个也不需要
假设你有一个线性模型,有时你得选择和优化这个模型的特征,一天你决定用同样的特征实验一个更复杂的模型,大部分情况你没有看到任何提高。
失败以后,你改变策略,再反过来试验,使用老的模型,但是增加更具丰富的特征,试图捕获更复杂的交互,大部分情况下结果相同你没看到任何提高。
到底是怎么回事?其实一个更复杂的特征需要更复杂的模型,反之亦然,一个更复杂的模型需要更复杂的特征。
教训是:你必须并行提高你的模型和特征集合,某个时间只做其中一个可能会导致错误的结论。
4.想想你是怎么定义和训练你的数据集
如果你训练一个二进制分类器,首要任务是定义正负样本,为样本定义正负标签也许不是普通任务,联系场景考虑,比如你需要一个分类器区分显示看过的用户(正)和没有看过的(负),在这个上下文场景中,下面哪些是正负?
1.用户看了一部影片,投票一个颗星
2.用户又看了同样的电影(也许因为他没其他可看)
3.用户在5分钟或15分钟或1小时后退出影片
4.用户在两个片段或10片段或一季后退出TV show
5.用户增加一些东西到他的列表,但是从来没有看过。
正如你看到,决定一个案例的正负并不容易。
除了关注正负定义以外,还有很多事情在你训练数据集时必须确保正确的,一个情况是Time Traveling,Time Traveling被作为特征定义使用,这是起源于你试图预测的事件。(见原文...)
5.学会处理界面展现层的偏差( presentation bias)
用户在界面上点按,会激活你的算法已经决定展示给他们的结果,当然你的算法决定的结果是符合用户的预测,让我们假设一个新用户进来,我们决定展示给这个用户仅仅是流行的商品,一个星期后,用户也许消费了某个流行的商品,但是不意味着该用户喜欢它,只是这个商品是他唯一选择消费的机会。
解决这个问题一个方式是实现一些展现折扣机制。
另外一个方式是使用用户的浏览而不是点击商品作为训练过程的负向,如果一个用户查询,然后在结果页面上点按第三个商品,那意味着前面两个商品是坏的,不应该作为负向训练? 或者不是?前面两个比第三个好像差一点点,但是不意味着它们一直很差,比如比第四个商品,这些让你的原始模型决定的选择是没有益处的,你需要移除展现偏差。
第一种方式是引入一些随机性,这会允许收集一些非偏差用户反馈,以便决定哪个商品是好还是差。
另外一个方式是开发一些用户的“注意力模型”,这样点击或没有点击的商品都会作为权重,只要用户能够注意到它们,它们的位置可能是在页面会让人注意感兴趣的区域。
最后,你还可以通过使用一些explore/exploit方式,比如Thompson Sampling等
...
6. UI是联系算法和最重要的用户之间唯一通道
从前面案例你已经发现对展现层和用户界面进行思考在机器学习算法设计中是多么重要,一方面,界面产生用户所有的反馈,可以作为算法的输入,另外一个方面,UI是仅有的我们算法展示的地方,它不关注我们的ML算法多么智能,如果UI隐藏了或没有让用户产生反馈,我们关于模型的所有努力都是徒劳。
在用户界面的改变也许需要算法的改变,正如模型和特征之间的联系一样,在算法和展现层之间联系也同样需要注意。
7.数据和模型非常棒,但是你知道什么更重要?正确的演化路径
这可能是这些教训中最重要的,所有关于数据 模型 和基础设施都很重要,如果没有正确的自我进化的路径,这些都没有用,如果你不知道如何衡量和提高,你只能是无休止空转车轮,其实哪儿也去不了,一些我在实践中见过最大的收获确实来自模型被优化微调后的结果
那么什么是正确的进化途径,下图是演示了从起始开始离线/在线不断创新,不管你的ML算法最终目标是什么,你应该是通过两种不同方式驱动你的创新演进:离线和在线。
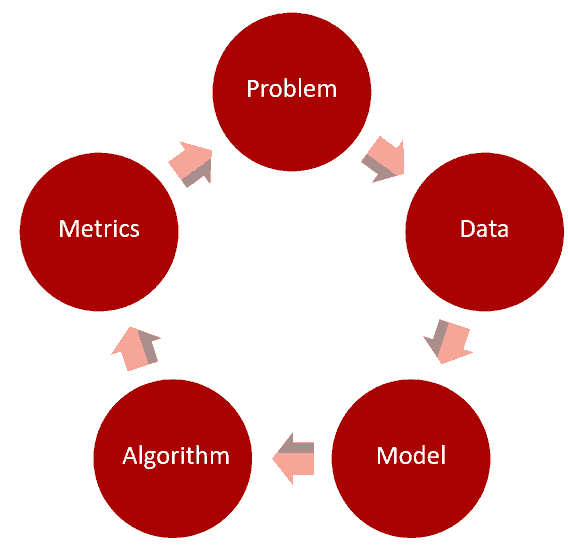
首先,你应该以离线方式遵循传统ML经验试验不同的模型和特征,训练你的模型到某个程度,你能优化参数到一个有效范围,最后在测试数据集中评估结果。在Netflix场景中,评估衡量可以是IR衡量,如精确度和recall, ROC curves, 或者排名度量如NDCG, MRR, 或FPC (Concordant Pairs的分形).....
离线经验是很棒的,因为一旦你有正确的数据和正确的测量,那么你就容易获得以很少资源运行很多的经验,不幸的是,成功的离线经验也会被用于错误的在线测试,很多公司正在投入以发现离线和在线的结果的相关性,这还是一个未解决的问题,需要更多研究。
在线经验通常是A/B测试(其他 Multiarmed Bandit Testing 或 Interleaved Testing正在逐步流行),A/B测试目标是量化跨同一个集合不同算法的区别不同的程度。
选择适当的评估方式很重要,它确保产品中所有决定并不都是数据驱动的。
大多数人民有不同的跟踪AB测试的度量方式,最重要是搞清楚Overall Evaluation Criteria (OEC)
....
8.分布式算法?是的,但是在什么层次?
分布式算法需要很多资源,主要决定于你在哪个层次分发:
Netflix在三个层次分发:
1.基于整个数据的每个独立子集
2.混合参数的每个组合
3.每个训练数据集的所有分区
第一层为不同地区 不同语言的用户定义不同的训练数据集,训练能够无需协调或数据联系情况下分布。
(此处省去几段介绍如何在三层分布的细节...)
Netflix是通过亚马逊AWS云分布器人工神经网络,对于第一层,不同AWS区域使用不同机器实例,对于2层,在同样区域使用不同机器,设立一个中央点用于协调,使用Condor进行集群协调(其他选项是StarCluster Mesos甚至Spark),第三层优化使用在GPU上定制的CUDA代码。
9.对混合参数Hyperparameters的付出总会有回报
建立你的ML系统最重要是微调混合参数,大部分情况下,算法总是有一些混合参数需要微调:
矩阵分解(matrix factorization)的学习率,逻辑回归(LR:logistic regression)的正则lambda,
神经网络的隐藏层数量,gradient boosted decision trees(GBDT)的损率等等,这些都有参数需要微调到有效数据。
(此处略去详细微调介绍....)
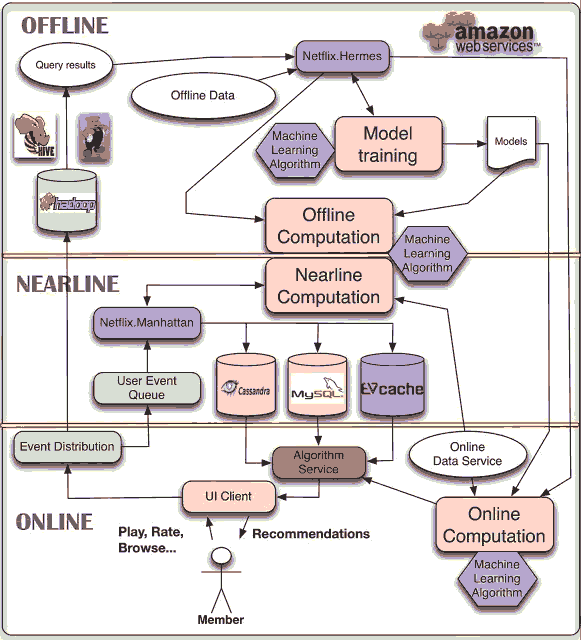
10. 有些事情你能离线完成,也有不能的,可选择在离线和在线之间的Nearline.
之前我们讨论了数据 模型 UI和度量的重要性,现在应该是聚焦系统和架构,当你的ML模型最终目标是在生产环节有重要影响,你有必要得思考正确的系统架构。
在延时和复杂性之间权衡很重要,一些计算需要实时,尽快响应给用户反馈,另外复杂的ML模型需要大量数据,需要长时间才能计算好,还有一些近乎在线NearLine,操作不保证实时发生,但是最好尽可能快地执行。
总结:
1.思考你的数据
2.理解数据和模型的依赖
3.选择正确的度量
4.只优化重要的
原文
[该贴被banq于2014-12-30 16:37修改过]