使用Apache Samza对数据库进行彻底的"调教"
数据库是全局的共享的可变的状态,自上世纪60年以来一直是这样,大多数有自尊的开发人员在他们代码中已经摆脱了全局变量,那么为什么我们还要容忍数据库作为一个全局变量呢?
这个谈话介绍了Apache Samza,它是一个由LinkedIn开发的分布式流处理框架,起初,它看起来像一个实时计算分析工具,但是它彻底地将数据库架构颠覆了。
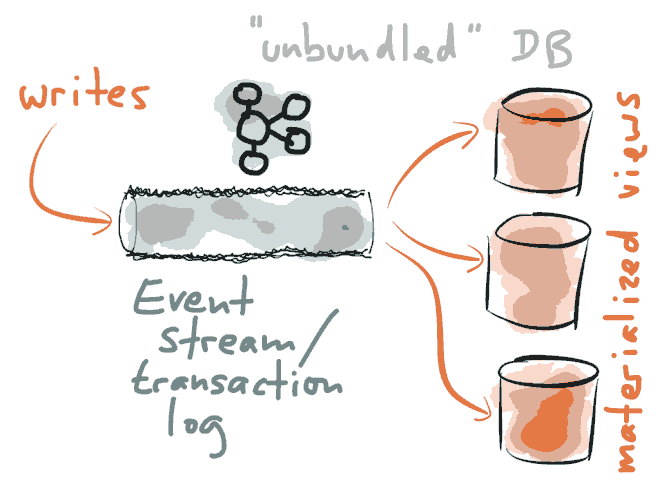
在其核心是一个分布式的持久的提交日志,由Apache Kafka实现强大的流连接和管理大量的数据可靠性。
原文:Turning the database inside-out with Apache Samza
下图是典型的Web应用框架架构:
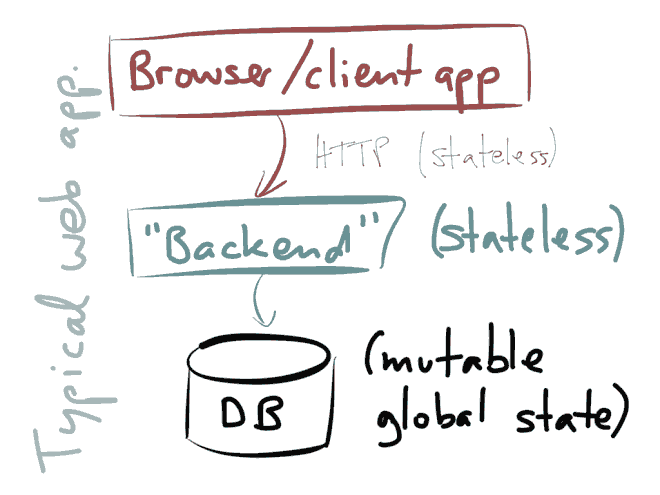
你有一个客户端比如是Web浏览器或移动应用,客户端向服务器端或者称为后端交互,后端实现一些业务逻辑,执行访问控制,接受输入,产生输出,当后端需要为将来保存一些数据,那么就存储到数据库,以后需要时查询数据库。这是目前大家非常熟悉的东西。
通常我们建立这种后端是无状态,这有很多优点:你能通过并行运行多个进程或实例来扩展后端,你能将客户端转发到多个实例服务器上,任何需要状态的请求将从数据库中查询,这通常与HTTP无状态特点吻合。
这个架构最大问题是:状态必须保存数据库中,这样导致将数据库作为一个巨大的、全球的、共享的可变状态,它是一个全局变量,在你的应用服务器之间共享。
在共享内存中进行并发是一件可怕的事情,LinkedIn已经斗争了很多年,从Actor模型 Channel gogroutine等,所有都是试图解决共享内存的并发问题,避免锁 死锁、并发修改、竞争条件等等。
我们试图摆脱共享内存的并发问题,但是数据库还是最大的共享的可变状态,那么值得思考:如果我们能在单服务器应用架构中能解决共享内存的并发问题,如果我们在整个系统级别克服这种全局的可变状态会如何呢?
在我们看来,将整个系统建立在可变的数据库系统上是习惯问题,我们几十年的架构习惯,现在我们想想有什么其他架构构建有状态的系统呢?
为了试图找出我们可以采取什么样的解决路线,我们先看看目前数据库做的四个事情,这四个例子也许为我们指明方向。
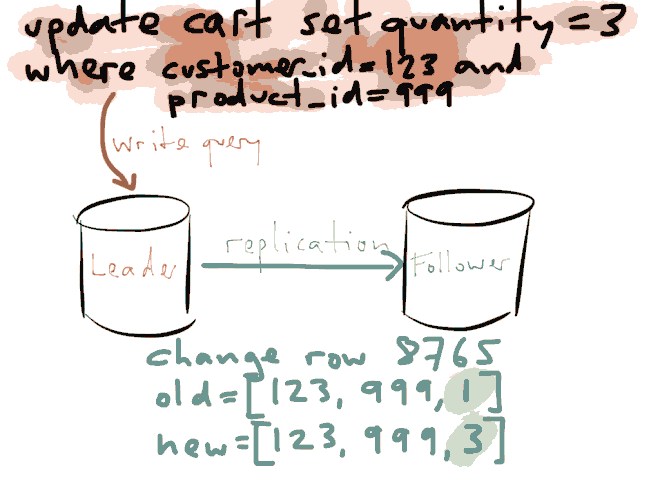
1.复制。数据库是在主从服务器之间复制数据,看看下面购物车案例:

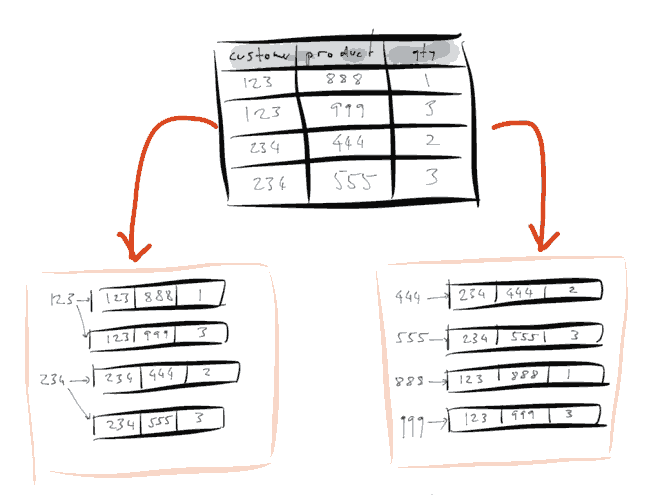
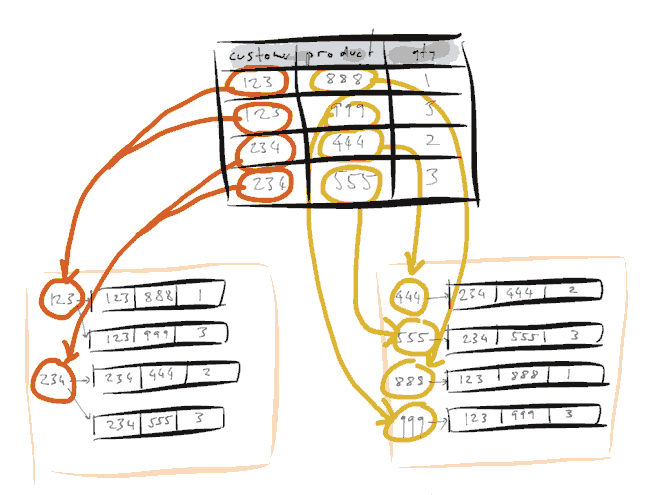
这是一个关系数据库数据模型,这是一个通用模型,有一个表,表中有一些列等等,每行代表一组记录。
假设客户123改变主意,不需要一个产品999,而是需要3个,那么我们会更新到数据库。
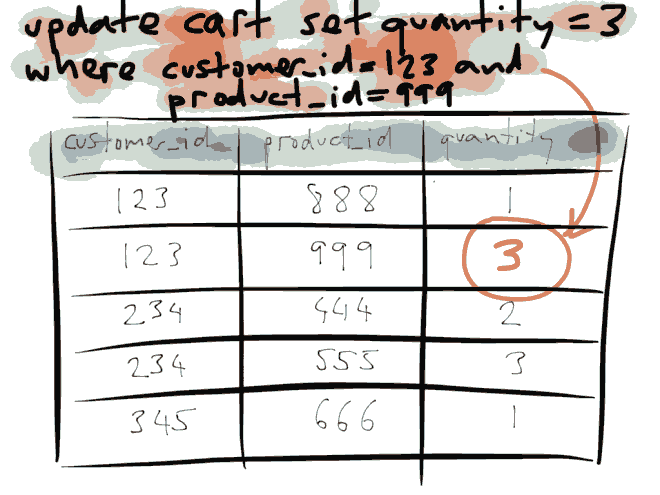
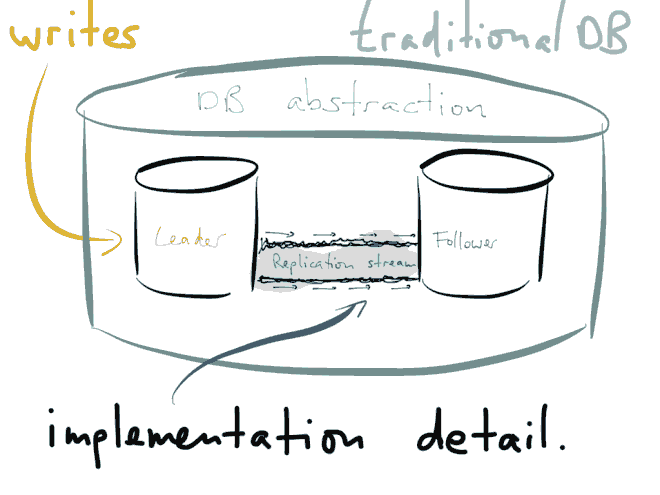
那么对于复制来说,这些写操作都要从主服务器复制到从服务器上。