实时流处理框架Apache Flink简介
如今流处理越来越流行,例如Apache Kafka, Apache Samza, Apache Storm, Apache Spark的Streaming模块等等,云服务还有类似Google Cloud Dataflow。
Apache Flink作为一个新的流处理系统,其特点是:
1. 低延迟的流处理器
2.丰富的API能够帮助程序员快速开发流数据应用
3.灵活的操作状态和流窗口
4.高效的流与数据的容错
很多公司正在从传统的批处理架构迁移到实时流架构,在分布式系统如HDFS中静态文件和关系数据库在通过事件流得到增强,使用批处理实现的工作任务能够在流处理中以更低延迟实现。

这种转型有许多方式,首先,许多数据集和用例都是基于事件的(比如机器日志等),其次流处理在某种程度上可以处理更复杂的工作任务,流处理原则上能够以低延时执行大部分批处理的工作任务,这样,当流处理能够处理同样的工作任务时,几乎没有理由再选择使用hadoop这样的批处理框架了。最后,一些新的应用类型诸如处理敏感数据经常需要持续查询,这些应用只能使用流架构实现。
一个典型的流架构由下面三个组件组成:
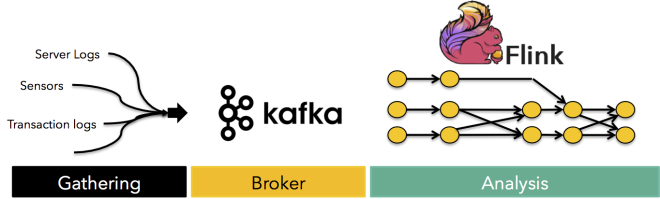
1. 一个模块组件是从各种数据源收集事件流
2. 一个模块组件集成各种流,使它们可用于直接消费。
3.一个模块组件用来分析消费这些流数据
第一步是从各种数据源收集事件,事件来自于数据库,机器产生日志,事件传感器等,这些事件需要清理 组织化到一个中心。
第二步,在一个中心集成各种流,典型工具如Apache Kafka,Kafka提供一个broker功能,以失败容错的高可靠性用来收集流 日志或缓冲数据,以及分发到各种对不同流感兴趣的消费者那里进行分析。
第三步,对流进行真正的分析,比如创建计数器 实现聚合,Map/Reduce之类计算,将各种流Join一起分析等等,提供了数据分析所需的一步到位的高级编程。Apache Flink正是这步实现。
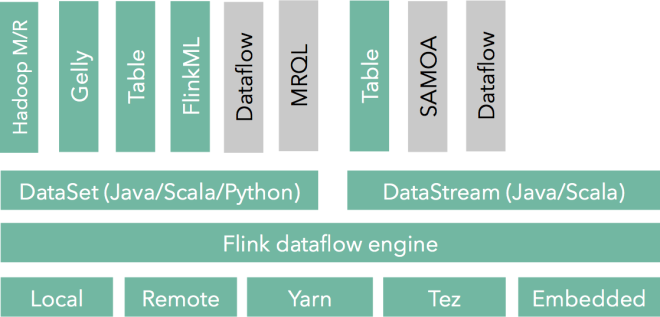
Flink能够既用来进行批处理又能用来进行流处理,也就是综合了Hadoop和Storm或Spark Streaming两者优点,需要了解详情见: