日本黄瓜农场主如何使用深度学习和TensorFlow
毫不夸张地说机器学习和深度学习不只是限定在图像等领域,大概一年前,日本自动化移动工业的嵌入系统设计者Makoto Koike
开始帮助他的父母的黄瓜农场,将黄瓜按大小 形状和颜色等属性排序分类。
笔直且厚带有鲜艳颜色的、表面有许多突起的黄瓜被认为是好黄瓜,能卖出高价格。(banq注:有一个个小突起的黄瓜反而卖得好,奇怪了,是买来吃得吗?)
Makoto很快意识到,将黄瓜按这种标准进行分类排序是非常难的,特别是在黄瓜生长期间,每个黄瓜都有不同颜色、形状、质量和新鲜度。
在日本,每个农场都有自己的分类标准,并没有工业界统一标准,在Makoto的农场,他们将黄瓜分类到九个不同类别,这是由其母亲做的,收获季节每天花费8小时做这件事。
排序分类并不容易学习,你不仅要看大小和厚度,还有颜色、表面,小痕迹,是否弯曲,是否有突起,你花费数月时间学习,在繁忙季节也很难雇佣到兼职工人。
市场上有一些自动排序分类者,但是总是在性能和成本方面有限制,小农场不会使用。
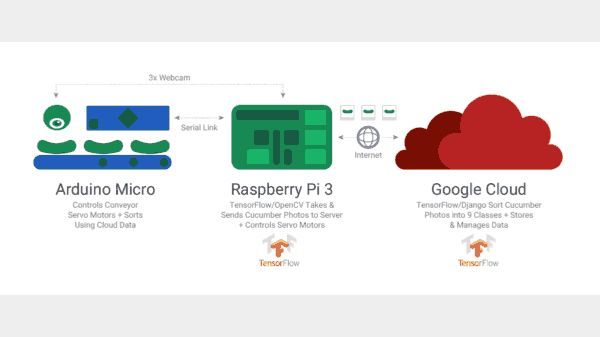
Makoto决定自己建立这样一个机器学习分类系统,下面是他黄瓜排序分类系统的流程图:
Raspberry Pi3作为主要控制器,通过摄像头获取黄瓜的图片,然后运行一个基于TensorFlow的小型神经元网络,用来检测抓取的图像是否是一个黄瓜?然后将图像发送到大型TensorFlow神经网络,这是运行在一个Linx服务器上,能够执行更细节的分类。
Makoto使用TensorFlow案例代码Deep MNIST for Experts,只需要对卷积,Pooling池化和最终层进行很小修改,改变网络设计适应黄瓜图像的像素格式和黄瓜类型数量。
Makoto花费三个月使用7000个由他母亲挑选好的黄瓜图片进行数据集训练,但是显然不够,进行训练时,识别准确率超过95%,但是实际应用时,降低到70%,一开始他以为这是神经网络的overfitting,也就是神经网络中一些模型只能适合小数据集。
第二个挑战是,深度学习消耗很大计算机资源,当前排序这是有传统的windows桌面PC来训练神经网络模型,尽管将黄瓜图片已经转换到80x80的低分辨率图片,针对7000个图片还是花费了两三天完成训练模型。降低分辨率就不能识别颜色和表面情况,增加分辨率会导致训练时间延长。
为了提高深度学习,一些大型企业已经开始启动大规模分布式训练,但是服务器成本相当高,Google提供的Cloud ML,这是一种低成本云平台用于训练和预测,可以定制数百个云服务器使用TensorFlow进行训练,你只要按需付费即可。这使得普通开发人员更方便进行深度学习开发。
Makoto热切等待Cloud ML,这样可以使用更高分辨率图片,使用更多黄瓜数据进行训练,能够改变神经网络各种配置参数和算法提高识别精确度了。
How a Japanese cucumber farmer is using deep learn