这篇博客文章展示了如何配置Spring Kafka和Spring Boot以使用JSON发送消息并以多种格式接收它们:JSON,纯字符串或字节数组。基于此配置,您还可以将Kafka生成器从发送JSON切换到其他序列化方法。
此示例应用程序还演示了同一消费组中三个Kafka消费者的使用情况,因此消息在三者之间进行负载平衡。每个消费者实现不同的反序列化方法。
您可以了解一些Kafka概念,如Consumer Group和Topic分区。
多个消费者
要更好地理解配置,请查看下图。如您所见,我们创建了一个包含三个分区的Kafka主题。在消费者方面,只有一个应用程序,但它实现了具有相同group.id 属性的三个Kafka消费者。
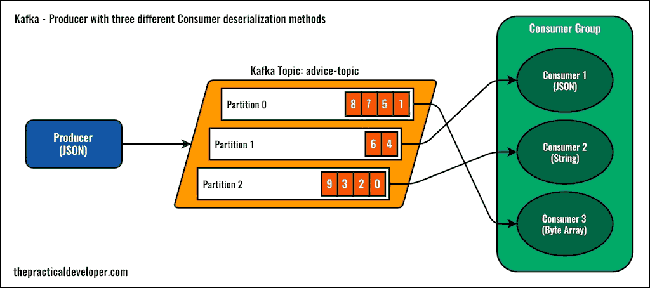
当我们启动应用程序时,Kafka会为每个消费者分配一个不同的分区。消费者组将以负载平衡的方式接收消息。在这篇文章的后面,如果我们让它们具有不同的组标识符,你会看到有什么区别(如果你熟悉Kafka,你可能知道结果)。
示例用例
我们要构建的逻辑很简单。每次我们调用指定REST端点hello,应用程序将生成可配置数量的消息,并使用序列号作为Kafka密钥将它们发送到同一主题,等待消费所有消息后返回Hello Kafka!
设置Kafka和Spring Boot
首先,您需要有一个正在运行的Kafka集群才能连接。对于这个应用程序,我将在单个节点中使用docker-compose和Kafka。这显然远不是一个生产配置,但它足以满足这篇文章的目标。
以下是docker-compose.yml配置
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false'
|
请注意,我将Kafka配置为不自动创建主题(最后一行配置)。我们将在Spring Boot应用程序创建我们的主题,因为我们想要传递一些自定义配置。如果你想玩玩这些Docker图像(例如使用多个节点),请查看wurstmeister/zookeeper图像文档
要启动Kafka和Zookeeper容器,只要在上述配置目录下运行 docker-compose up
获取SpringBoot应用程序骨架的最简单方法是到start.spring.io,使用使用YAML进行配置配置application.yml:
spring:
kafka:
consumer:
group-id: tpd-loggers
auto-offset-reset: earliest
# change this property if you are using your own
# Kafka cluster or your Docker IP is different
bootstrap-servers: localhost:9092
tpd:
topic-name: advice-topic
messages-per-request: 10
|
第一部分属性是Spring Kafka配置:
- Kafka的组标识 group-id
- auto-offset-reset 属性设置为earliest,这意味着当消费者没有发现偏移量(指针)时,消费者将开始从最早的消息中读取消息。
- 第三行用于连接Kafka的服务器,在这种情况下,如果您使用单节点配置,则是唯一可用的服务器。请注意,如果使用默认值 localhost:9092,则此属性是多余的 。
第二部分是特定于应用程序的自定义配置。我们定义Kafka主题名称以及每次执行HTTP REST请求时要发送的消息数。Message类
这是我们将用作Kafka消息的Java类。这里没有什么复杂的,只是@JsonProperty 在构造函数参数中带有注释的不可变类, 因此Jackson可以正确地反序列化它。
import com.fasterxml.jackson.annotation.JsonProperty;
public class PracticalAdvice {
private final String message;
private final int identifier;
public PracticalAdvice(@JsonProperty("message") final String message,
@JsonProperty("identifier") final int identifier) {
this.message = message;
this.identifier = identifier;
}
public String getMessage() {
return message;
}
public int getIdentifier() {
return identifier;
}
@Override
public String toString() {
return "PracticalAdvice::toString() {" +
"message='" + message + '\'' +
", identifier=" + identifier +
'}';
}
}
|
Spring Boot中的Kafka Producer配置
为了简化应用程序,我们将在Spring Boot类中添加配置。最后,我们希望在此处包含生产者和消费者配置,并使用三种不同的变体进行反序列化。请记住,您可以在GitHub存储库中找到完整的源代码。
首先,让我们关注Producer配置:
@SpringBootApplication
public class KafkaExampleApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaExampleApplication.class, args);
}
@Autowired
private KafkaProperties kafkaProperties;
@Value("${tpd.topic-name}")
private String topicName;
// Producer configuration
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props =
new HashMap<>(kafkaProperties.buildProducerProperties());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, Object> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, Object> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public NewTopic adviceTopic() {
return new NewTopic(topicName, 3, (short) 1);
}
}
|
在此配置中,我们将设置应用程序的两个部分:
- KafkaTemplate实例,这是我们将使用它将消息发送到卡夫卡。我们不想使用默认版本,因此我们需要在Spring的应用程序上下文中注入我们的自定义这个实例版本。
- 我们键入(使用泛型)KafkaTemplate以具有普通的String键和Object作为值。将Object作为值的原因是我们希望使用相同的模板发送多个对象类型。KafkaTemplate接受我们在配置中创建的ProducerFactory作为参数。
- 我们使用的ProducerFactory是默认的,但是我们需要在这里显式配置,因为我们想要传递我们的自定义生成器配置。
- Producer Configuration是一个简单的键值映射。我们使用默认属性@Autowired 来获取 KafkaProperties bean,然后构建我们的map,传递生成器的默认值,并覆盖默认的Kafka键和值序列化器。生产者将使用Kafka库将键序列化为字符串,StringSerializer 并且将对值执行相同的操作,但这次使用JSON JsonSerializer,在本例中由Spring Kafka提供。
- 我们将要使用的Kafka主题。通过注入一个NewTopic 实例,我们指示Kafka的AdminClient bean(已经在上下文中)创建一个具有给定配置的主题。第一个参数是名称(advice-topic,来自app配置),第二个是分区数量(3),第三个参数是复制因子(一个,因为我们无论如何都使用单个节点)。
关于Java的Kafka Serializers和Deserializers
Strings 的核心Kafka库(javadoc)中提供了一些基本的Serializer ,所有类型的数组类和字节数组,以及Spring Kafka(javadoc)提供的JSON类。
最重要的是,您可以通过实现Serializer or ExtendedSerializer或其相应的反序列化版本来创建自己的序列化器和反序列化器。这为您提供了很大的灵活性,可以优化通过Kafka传输的数据量。正如您在这些接口中看到的那样,Kafka使用普通字节数组,因此,无论您使用何种复杂类型,都需要将其转换为byte[]。
知道这一点,你可能想知道为什么有人想要在Kafka上使用JSON。由于您将对象转换为JSON然后转换为字节数组,因此效率非常低。但是你必须考虑这样做有两个主要优点:
- JSON比人类更可读,而不是字节数组。如果您想调试或分析Kafka主题的内容,那么它将比查看裸字节更简单。
- JSON是标准,而默认字节数组序列化器依赖于编程语言实现。因此,如果要使用来自多种编程语言的消息,则需要在所有这些语言中复制(反)序列化器逻辑。
另一方面,如果您担心Kafka中的流量负载,存储或(反)序列化速度,您可能需要选择字节数组,甚至可以选择自己的串行器/解串器实现。
使用Spring Boot和Kafka发送消息
我们创建一个Rest Controller,并在KafkaTemplate 请求端点时通过注入来生成一些JSON消息。
这是控制器的第一个实现,仅包含产生消息的逻辑。
@RestController
public class HelloKafkaController {
private static final Logger logger =
LoggerFactory.getLogger(HelloKafkaController.class);
private final KafkaTemplate<String, Object> template;
private final String topicName;
private final int messagesPerRequest;
private CountDownLatch latch;
public HelloKafkaController(
final KafkaTemplate<String, Object> template,
@Value("${tpd.topic-name}") final String topicName,
@Value("${tpd.messages-per-request}") final int messagesPerRequest) {
this.template = template;
this.topicName = topicName;
this.messagesPerRequest = messagesPerRequest;
}
@GetMapping("/hello")
public String hello() throws Exception {
latch = new CountDownLatch(messagesPerRequest);
IntStream.range(0, messagesPerRequest)
.forEach(i -> this.template.send(topicName, String.valueOf(i),
new PracticalAdvice("A Practical Advice", i))
);
latch.await(60, TimeUnit.SECONDS);
logger.info("All messages received");
return "Hello Kafka!";
}
}
|
在构造函数中,我们传递一些配置参数和我们自定义的KafkaTemplate,以发送String键和JSON值。然后,当API客户端请求/hello 端点时,我们发送10条消息(这是配置值),然后我们阻止线程最多60秒。锁存器解锁后,我们将消息返回Hello Kafka! 给客户端。
这整个锁定的想法不是在实际应用程序中看到的模式,但它对于这个例子来说是好的。这样,您可以检查收到的邮件数量。如果您愿意,可以在接收消息之前删除锁存器并返回“Hello Kafka!”消息。
Kafka消费者配置
正如前面在本文中所提到的,我们希望演示使用Spring Boot和Spring Kafka进行反序列化的不同方法,同时了解当多个消费者属于同一个消费者组时,多个消费者如何以负载均衡的方式工作。
@SpringBootApplication
public class KafkaExampleApplication {
public static void main(String[] args) {
SpringApplication.run(KafkaExampleApplication.class, args);
}
@Autowired
private KafkaProperties kafkaProperties;
@Value("${tpd.topic-name}")
private String topicName;
// Producer configuration
// omitted...
// Consumer configuration
// If you only need one kind of deserialization, you only need to set the
// Consumer configuration properties. Uncomment this and remove all others below.
// @Bean
// public Map<String, Object> consumerConfigs() {
// Map<String, Object> props = new HashMap<>(
// kafkaProperties.buildConsumerProperties()
// );
// props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
// StringDeserializer.class);
// props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
// JsonDeserializer.class);
// props.put(ConsumerConfig.GROUP_ID_CONFIG,
// "tpd-loggers");
//
// return props;
// }
@Bean
public ConsumerFactory<String, Object> consumerFactory() {
final JsonDeserializer<Object> jsonDeserializer = new JsonDeserializer<>();
jsonDeserializer.addTrustedPackages("*");
return new DefaultKafkaConsumerFactory<>(
kafkaProperties.buildConsumerProperties(), new StringDeserializer(), jsonDeserializer
);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Object> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
// String Consumer Configuration
@Bean
public ConsumerFactory<String, String> stringConsumerFactory() {
return new DefaultKafkaConsumerFactory<>(
kafkaProperties.buildConsumerProperties(), new StringDeserializer(), new StringDeserializer()
);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerStringContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(stringConsumerFactory());
return factory;
}
// Byte Array Consumer Configuration
@Bean
public ConsumerFactory<String, byte[]> byteArrayConsumerFactory() {
return new DefaultKafkaConsumerFactory<>(
kafkaProperties.buildConsumerProperties(), new StringDeserializer(), new ByteArrayDeserializer()
);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, byte[]> kafkaListenerByteArrayContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, byte[]> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(byteArrayConsumerFactory());
return factory;
}
}
|
这种配置可能看起来很繁琐,但考虑到为了演示这三种类型的反序列化,我们重复了三次创建ConsumerFactory和KafkaListenerContainerFactory实例,以便我们可以在消费者中切换它们。
配置消费者的基本步骤是:
- 以类似Producer的方式设置Consumer属性。我们可以跳过此步骤,因为我们需要的唯一配置是Spring Boot属性文件中指定的Group ID,以及我们将在创建自定义消费者和KafkaListener工厂,从而实现自定义的键和值反序列化器。如果您只需要一个配置,意味着始终使用相同类型的Key和Value反序列化器,那么被注释掉的代码块符合你这一需求,可将反序列化器类型调整为你要使用的类型。
- 要使用的KafkaListenerContainerFactory就要创建ConsumerFactory, 我们创建三个,在每种情况下将反序列化器切换为1)JSON反序列化器,2)字符串反序列化器和3)字节数组反序列化器。[list=1]
- 请注意,在创建JSON反序列化器之后,我们将包含一个额外的步骤来指定我们信任所有包。如果需要,您可以在应用程序中对其进行微调。如果我们不这样做,我们将收到一条错误消息,上面写着:java.lang.IllegalArgumentException: The class [] is not in the trusted packages。
使用先前配置的Consumer Factory构造KafkaListenerContainerFactory(并发容器工厂)。同样,我们这样做三次,每个实例使用不同的一个。
使用Spring Boot和Kafka以JSON,String和byte []格式接收消息
现在是时候展示Kafka消费者的样子了。我们将使用@KafkaListener 注释,因为它简化了过程并负责对传递的Java类型进行反序列化。
@RestController
public class HelloKafkaController {
private static final Logger logger =
LoggerFactory.getLogger(HelloKafkaController.class);
private final KafkaTemplate<String, Object> template;
private final String topicName;
private final int messagesPerRequest;
private CountDownLatch latch;
public HelloKafkaController(
final KafkaTemplate<String, Object> template,
@Value("${tpd.topic-name}") final String topicName,
@Value("${tpd.messages-per-request}") final int messagesPerRequest) {
this.template = template;
this.topicName = topicName;
this.messagesPerRequest = messagesPerRequest;
}
@GetMapping("/hello")
public String hello() throws Exception {
latch = new CountDownLatch(messagesPerRequest);
IntStream.range(0, messagesPerRequest)
.forEach(i -> this.template.send(topicName, String.valueOf(i),
new PracticalAdvice("A Practical Advice", i))
);
latch.await(60, TimeUnit.SECONDS);
logger.info("All messages received");
return "Hello Kafka!";
}
@KafkaListener(topics = "advice-topic", clientIdPrefix = "json",
containerFactory = "kafkaListenerContainerFactory")
public void listenAsObject(ConsumerRecord<String, PracticalAdvice> cr,
@Payload PracticalAdvice payload) {
logger.info("Logger 1 [JSON] received key {}: Type [{}] | Payload: {} | Record: {}", cr.key(),
typeIdHeader(cr.headers()), payload, cr.toString());
latch.countDown();
}
@KafkaListener(topics = "advice-topic", clientIdPrefix = "string",
containerFactory = "kafkaListenerStringContainerFactory")
public void listenasString(ConsumerRecord<String, String> cr,
@Payload String payload) {
logger.info("Logger 2 [String] received key {}: Type [{}] | Payload: {} | Record: {}", cr.key(),
typeIdHeader(cr.headers()), payload, cr.toString());
latch.countDown();
}
@KafkaListener(topics = "advice-topic", clientIdPrefix = "bytearray",
containerFactory = "kafkaListenerByteArrayContainerFactory")
public void listenAsByteArray(ConsumerRecord<String, byte[]> cr,
@Payload byte[] payload) {
logger.info("Logger 3 [ByteArray] received key {}: Type [{}] | Payload: {} | Record: {}", cr.key(),
typeIdHeader(cr.headers()), payload, cr.toString());
latch.countDown();
}
private static String typeIdHeader(Headers headers) {
return StreamSupport.stream(headers.spliterator(), false)
.filter(header -> header.key().equals("__TypeId__"))
.findFirst().map(header -> new String(header.value())).orElse("N/A");
}
}
|
这里有三个消费者。首先,让我们描述@KafkaListener 注释的参数:
- 所有消费者都使用相同的主题advice-topic。此参数是必需的。
- 参数clientIdPrefix 是可选的。我在这里使用它,让日志更人性化。您将知道哪个消费者通过其名称前缀做什么。卡夫卡将附加一个这个前缀的数字。
- containerFactory 参数是可选的,您还可以依赖命名约定。如果不指定它,它将查找具有名称的bean kafkaListenerContainerFactory,这也是Spring Boot在自动配置Kafka时使用的默认名称。您也可以使用相同的名称覆盖它(尽管对于不了解约定的人来说它看起来很神奇)。我们需要明确地设置它,因为我们想为每个监听器使用不同的一个,以便能够使用不同的反序列化器。
请注意,传递给所有消费者的第一个参数是相同的:一个 ConsumerRecord和@Payload,如果我们使用第一个,则第二个 是多余的。我们可以访问ConsumerRecord的方法value() 获得Payload,但我这里写在这里,让你看到它是多么简单直接通过反序列化得到的Payload。
Kafka中的TypeId标头
标头 __TypeId__默认情况下由Kafka库自动设置。我这里使用工具方法typeIdHeader 获得字符串,因为从ConsumerRecord的toString() 方法只能看到字节组输出。
TypeId标头可用于反序列化,因此您可以找到要将数据映射到的类型。但是JSON反序列化却不需要它,因为这个特殊的反序列化器是由Spring团队制作,并且它们从方法的参数中推断出类型。
运行
现在我们完成了Kafka生产者和消费者,我们可以运行Kafka和Spring Boot应用程序:
$ docker-compose up -d
Starting kafka-example_zookeeper_1 ... done
Starting kafka-example_kafka_1 ... done
$ mvn spring-boot:run
pring Boot应用程序启动,消费者在Kafka中注册,Kafka为它们分配了一个分区。我们使用三个分区配置主题,因此每个消费者都会分配其中一个分区。
[Consumer clientId=string-0, groupId=tpd-loggers] Successfully joined group with generation 28
[Consumer clientId=string-0, groupId=tpd-loggers] Setting newly assigned partitions [advice-topic-2]
[Consumer clientId=bytearray-0, groupId=tpd-loggers] Successfully joined group with generation 28
[Consumer clientId=bytearray-0, groupId=tpd-loggers] Setting newly assigned partitions [advice-topic-0]
[Consumer clientId=json-0, groupId=tpd-loggers] Successfully joined group with generation 28
[Consumer clientId=json-0, groupId=tpd-loggers] Setting newly assigned partitions [advice-topic-1]
partitions assigned: [advice-topic-1]
partitions assigned: [advice-topic-2]
partitions assigned: [advice-topic-0]
|
我们现在可以尝试对服务进行HTTP调用。您可以使用浏览器curl,例如:
curl localhost:8080/hello
注意日志中的输出。
以上源码: Kafka and Spring Boot Example.
解释
Kafka对消息的key进行哈希化(key是一个简单的字符串标识符),并根据key将消息放入不同的分区。每个使用者在其分配的分区中获取消息,并使用其反序列化器将其转换为Java对象。请记住,我们的生产者总是发送JSON值。
正如您在日志中看到的,每个反序列化器都设法完成其任务,因此String消费者打印原始JSON消息,字节数组消费者显示JSON字符串的字节表示,JSON反序列化器使用Java类型映射器进行转换到原来的类PracticalAdvice。您可以查看记录的ConsumerRecord,您将看到标题,指定的分区,偏移量等。
这就是你如何使用Spring Boot和Kafka发送和接收JSON消息。我希望您发现本指南很有用,下面您有一些代码变体,以便您可以更多地了解Kafka的工作原理。
多次请求/hello
发出一些请求,然后查看消息如何跨分区分布。具有相同密钥的Kafka消息始终放在相同的分区中。当您希望确保指定用户、进程或正在处理的任何逻辑的所有消息都由同一消费者以与生成时相同的顺序接收时,此功能非常有用(在事件溯源EventSourcing时实现事件顺序,从而实现事务一致性很需要),这里就不考虑负载平衡了。
减少分区数量
首先,确保重新启动Kafka,这样您就可以放弃以前的配置。
然后,在应用程序中重新定义主题,使其只有2个分区:
@Bean
public NewTopic adviceTopic() {
return new NewTopic(topicName, 2, (short) 1);
}
|
现在,再次运行应用程序并向/hello 端点发出请求。
结果:其中一个消费者没有收到任何消息。这是预期的行为,因为同一消费者组中没有可用的分区(我们只设置了2个分区)。
更改一个消费者的组标识符
保留上一个案例的更改,该主题现在只有2个分区。我们现在正在改变我们的一个消费者的群组ID。
@KafkaListener(topics = "advice-topic", clientIdPrefix = "bytearray",
containerFactory = "kafkaListenerByteArrayContainerFactory",
groupId = "tpd-loggers-2")
public void listenAsByteArray(ConsumerRecord<String, byte[]> cr,
@Payload byte[] payload) {
logger.info("Logger 3 [ByteArray] received a payload with size {}", payload.length);
latch.countDown();
|
请注意,我们还更改了记录的消息。现在,这个消费者负责打印payload有效载荷的大小。此外,我们需要更改CountDownLatch 它,因此它需要两倍的消息数。
latch = new CountDownLatch(messagesPerRequest * 2);
为什么?这一次,让我们解释在运行应用程序之前会发生什么。正如我在本文开头所描述的那样,当消费者属于同一个消费者群体时,他们(在概念上)正在处理同一个任务。我们正在实现一种负载均衡机制,其中并发工作程序从会不同分区获取消息,处理的消息是彼此隔离的。
在这个例子中,我还改变了最后一个消费者的“任务”,以便更好地理解这一点:它打印的是不同的东西。由于我们更改了组ID,因此该消费者将独立工作,Kafka将为其分配两个分区。字节数组消费者将接收所有消息,与其他两个消息分开工作。