使用客户端设备的实时日志作为事件源,我们可以得出测量值,以了解和量化用户设备如何无缝地处理浏览和回放。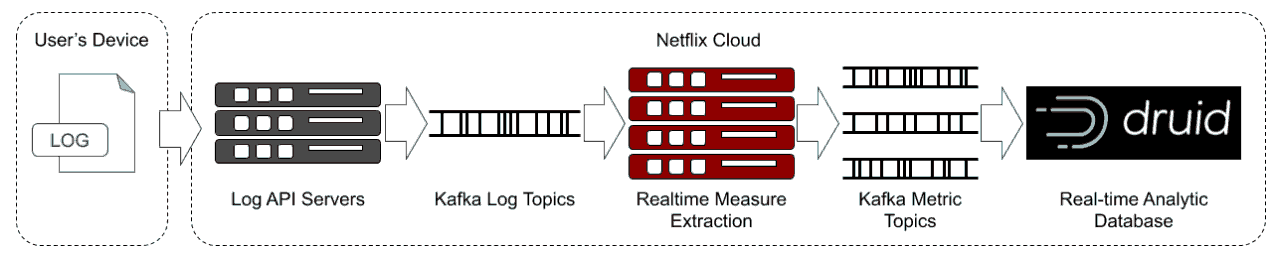 一旦有了这些度量,就将它们输入数据库。每项措施均标有关于所用设备种类的匿名详细信息,例如,设备是智能电视,iPad还是Android手机。这使我们能够根据各个方面对设备进行分类并查看数据。反过来,这又使我们能够隔离仅影响特定人群的问题,例如应用程序的版本,特定类型的设备或特定国家/地区。
一旦有了这些度量,就将它们输入数据库。每项措施均标有关于所用设备种类的匿名详细信息,例如,设备是智能电视,iPad还是Android手机。这使我们能够根据各个方面对设备进行分类并查看数据。反过来,这又使我们能够隔离仅影响特定人群的问题,例如应用程序的版本,特定类型的设备或特定国家/地区。
可以通过仪表板或临时查询立即使用此聚合数据进行查询。还会连续检查指标是否有警报信号,例如新版本是否正在影响某些用户或设备的播放或浏览。这些检查用于警告负责的团队,他们可以尽快解决该问题。
由于这些数据每秒可处理超过200万个事件,因此将其放入可以快速查询的数据库是非常艰巨的。我们需要足够的维数以使数据在隔离问题中很有用,因此,我们每天产生超过1150亿行。在Netflix,我们利用Apache Druid来帮助我们应对这一挑战。
Apache Druid是一个高性能的实时分析数据库。它是为真正需要快速查询和摄取的工作流而设计的。Druid在即时数据可见性,即席查询,运营分析和处理高并发方面表现出色。
因此,Druid非常适合我们的用例。事件数据的摄取率高,具有高基数和快速查询要求。
Druid不是关系数据库,但是某些概念是可移植的。我们有数据源,而不是表。与关系数据库一样,这些是表示为列的数据的逻辑分组。与关系数据库不同,没有连接的概念。因此,我们需要确保每个数据源中都包含我们要过滤或分组依据的任何列。
数据源中主要有三类列-时间,维度和指标。
Druid中的一切都取决于时间。每个数据源都有一个timestamp列,它是主要的分区机制。维度是可用于过滤,查询或分组依据的值。指标是可以汇总的值,几乎总是数字。
通过消除执行联接的能力,并假设数据由时间戳作为键,Druid可以对存储,分配和查询数据的方式进行一些优化,从而使我们能够将数据源扩展到数万亿行,并且仍然可以实现查询响应时间在十毫秒内。
为了达到这种级别的可伸缩性,Druid将存储的数据分为多个时间块。时间块的持续时间是可配置的。可以根据您的数据和用例选择适当的持续时间。
具体细节点击标题见原文。