广告技术(Ad Tech)是一个统称,它描述用于管理和分析程序化广告活动的系统和工具。数字广告的目标是尽可能多地吸引相关受众。因此,广告技术本质上与处理大量数据有关。
在此博客文章中,我们将研究如何关联两个事件流-广告投放(所谓的展示次数)和点击次数,并计算重要的广告技术指标-点击率(CTR)。我们的计算将使用Apache Flink的水平可扩展执行引擎基于运行中的数据进行。我们将专注于获得结果,而无需使用Java或Scala编写任何代码,而是完全依赖SQL。
在典型情况下,广告的放置是通过称为实时出价的机制执行的。从本质上讲,实时竞标是一种拍卖,众多参与者竞相向特定最终用户显示横幅或视频(统称为Creative)。在此过程中,需求方平台(DSP)获得了向用户显示广告的产品,这些广告由用户的设备ID标识并用其投注进行回复。
跟踪显示的印象和单击的印象是数字广告技术的关键任务之一。
尽管放置广告的过程在很大程度上是自动化的,但广告活动经理和业务分析师通常仍会采用相当程度的手动控制。通常,活动的定义和受众的选择器(如人口统计,原籍国以及活动的绩效标准)是手动定义的。可能需要密切监视活动的绩效并调整某些参数,尤其是在发布后的早期阶段(即验证假设的时间)。
为什么要进行流处理?
传统上,通过使用批处理来解决获取大量数据的见解的任务。这种方法与数字广告业务的高度动态性相矛盾。实时获取见解至关重要-等待一个小时或更长的时间以完成一个批处理任务,以完成原始数据的处理,同时由于活动的初始参数错误而耗尽预算是非常不可取的。此外,对于依赖于关联两个后续事件的任何度量标准,对于位于批处理“临界值”相对侧的事件,批处理将无法提供正确的结果,因此将由两个不同的批处理作业进行处理。
为什么使用Flink SQL?
监视活动的任务通常由数据或业务分析师执行。由于业务的动态性质,可能会与新的数据馈送进行潜在的临时集成,向现有数据流添加新维度以及进行其他类似的调整。在这种情况下,需要消除数据分析师在执行日常任务时对数据工程师的依赖性。为了实现这一点,需要具有低采用障碍的灵活工具集。SQL是数据分析的通用语言,其知识十分广泛。在Flink中运行SQL语句使您可以利用Flink的水平可伸缩流处理引擎的功能,而无需成为Java或Scala开发人员。
示例
在我们的示例中,我们将使用两个数据流。首先,通过定义它们的模式和表选项将这些流注册为表。
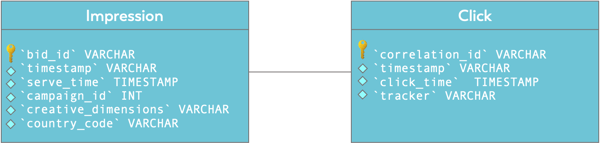
第一个流是广告展现流。这些事件中的每一个都表示在实时出价拍卖中获胜,并向用户成功展示了广告素材。它包含诸如广告素材的尺寸,国家/地区代码和广告系列ID之类的详细信息。
CREATE TEMPORARY TABLE `impressions` ( |
在此示例中,事件以JSON格式从Kafka获得数据使用。
WATERMARK FOR serve_time AS serve_time - INTERVAL '5' SECOND
意味着我们可以容忍5秒的时间外的订单交付的事件,仍然产生正确的结果。
点击广告后,我们可以在显示广告后跟踪的最重要结果之一。
CREATE TABLE TEMPORARY `clicks` ( |
的SQL
点击流的correlation_id对应于印象流的bid_id字段。这将成为连接各个数据流和计算点击率(CTR)的基础。但是在研究点击率计算之前,让我们首先从更简单的方法开始,检查所有部件是否位于正确的位置。
以下查询计算在60秒的翻转窗口中按campaign_id和creative_dimensions细分的展示次数:
SELECT |
更多点击标题见原文
结论
尽管此博客文章侧重于将Flink SQL应用于Ad Tech用例,但一般主题适用于各种场景,并且具有以下要求的任意组合:
- 实时了解发生的事件数据
- 降低组织中访问实时数据并对其执行分析的障碍
- 减轻传统数据库的负担