各大互联网大厂谷歌、亚马逊、脸书和京东是如何通过词法、图或神经网络的嵌入方法实现查询匹配的?
基于词法的技术是一种基本的、基于内容的方法,不需要构建知识图或大量行为数据,如果您要从头开始构建搜索系统,也许可以从这里开始。ElasticSearch和Lucene大部分都是开箱即用的。
如果您发现使用词法或基于图的方法(尤其是长尾查询)不能满足要求,请尝试使用通过自我监督的表示学习所学习的查询嵌入来增强它的价值。
搜索引擎和推荐机制有很多共同点。它们可帮助用户了解新产品,并需要在很短的时间内(<150毫秒)就对数百万种产品进行检索和排名。他们接受过类似机器学习的数据训练,拥有基于内容和行为的方法,并针对参与度(例如,点击率)和收入(例如,转化,商品总价值)进行了优化。
在本文中,我们将探讨使用查询的规范化、重写和检索(aka匹配)文档的各种方法。(尽管排名步骤也很重要,但现在我们将重点关注查询处理和匹配)。我们将比较三种主要方法:
- 基于词法的:此方法直接通过规范化,拼写检查,扩展,翻译等方式替换或扩展查询字符串。
- 基于图的:基于知识的图用于了解查询和更高级别的文档,以进行查询扩展和匹配。
- 基于嵌入的:它使用通过自我监督或监督技术学习的潜在表示形式进行扩展和匹配。
基于词法是查询处理的基础
基于词法的方法从预处理查询字符串开始。这包括归一化(例如,词干,unicode标准化,去除重音符号),拼写检查和标记化。词干尤其有助于减少针对同一查询的单词的各种形态形式。例如,“远足靴”和“远足靴”都被称为“远足靴”,从而使查询与文档的下游匹配更加容易。通常,这些预处理步骤将替换查询。
查询扩展通过添加令牌以匹配其他文档来增强查询。其他标记包括同义词(例如,“手机”可以扩展为“手机或手机或手机”)和缩写(例如,“ T恤L”可以扩展为“ T恤L或大T恤”) 。
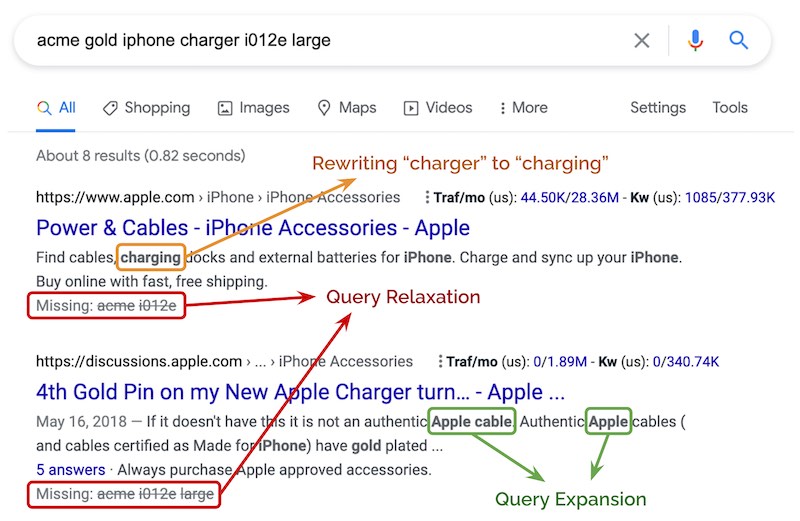
查询relaxation在某种程度上与查询扩展相反。我们改为从查询中删除令牌。这使查询的限制较少,并增加了查全率。最简单的方法是删除停用词。对于产品搜索,查询放宽可以降低颜色,进行度量(例如,小,中,大),型号,品牌和其他实体。
如“acme gold iphone charger i012e large”被抽为“ iphone charger”。尝试对完整的查询字符串进行匹配不会导致任何结果。但是在这种情况下,我们可以推断关键意图是“ iphone charger”,并放宽查询字符串以增加recall率。下面的示例还显示了“charger”被重写为“charging”,以及通过添加“apple”令牌进行的查询扩展。
查询翻译是另一种重写形式,其中文本翻译范例可用于将尾部查询(即不受欢迎的20%百分位数)转换为占大量流量的头部查询,从而有助于提高recall率。这也有助于下游排名,因为我们有更多关于头查询的行为信息(例如,点击,购买)。
查询处理后,可以用来检索相关文档。对于词汇方法,它主要涉及将查询中的标记和n-gram匹配到文档字段,例如标题,描述,类别,属性等。
DoorDash的搜索系统在通过“对称删除”拼写校正算法进行拼写校正之前,先进行基本处理(例如,删除多余的空格,降低大小写,扩展收缩)。然后,通过手动策划的同义词词典对更新的查询令牌进行标准化。例如,“ Poulet Frit Kentucky”,“ KFZ”和“ KFC”被归一化为“ kfc”。
但是,特定且有效的查询(例如“ Chick'n”)已被拼写更正为“ Chicken”。(其目录中有很多商品的名称可能不会出现在英语词典中,并且与常规单词的编辑距离很低。)为避免这些无效的更正,它们仅在最初的匹配尝试未返回任何拼写检查之后才应用拼写检查结果。
雅虎分享了他们的文本翻译方法来重写查询。目的是要解决对冷启动查询进行匹配和排序的问题(在点击日志中看不到)。为了实现这一目标,他们使用双向点击图中的查询文档对构建了翻译模型。(二部图是其中节点可以分为两个不相交的集合(例如查询和文档)的图。)翻译模型学习短语级别的翻译,例如单词对齐,短语提取和短语评分。在查询时,模型将每个查询细分为短语,然后翻译每个短语。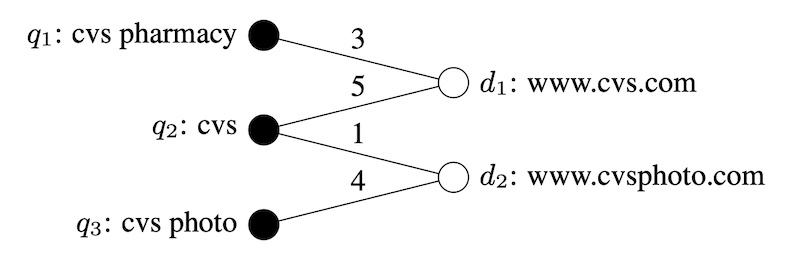
每个查询通常被翻译成数百个候选。根据三组特征对候选人进行评分:查询特征(例如,查询中标记的数量,停用词的数量,语言模型得分),翻译后的查询特征(与查询特征相同)以及原始查询和翻译后的查询之间的相似性(例如,共享网址之间的Jaccard相似度,词级余弦相似度等)。发现相似性特征是最重要的。
最后,原始查询和得分最高的翻译查询都用于检索文档。最终结果集是匹配任一查询的文档的并集。对于同时符合两个查询的文档,将使用其最大分数。
基于图:添加概念和关系
基于图的方法涉及构建和使用知识图来扩展查询和改善检索。知识图谱中最著名的示例可能是Google,大约10年前就推出了。它具有用于人员,地点,事物等的节点,以及将它们连接在一起的边。Google通过这种方式提供搜索结果摘要,有时会得出有趣的发现。
在查询期间,将对查询进行解析并将其标记为知识图中的相关概念(即节点)。然后,可以通过在知识图中找到最接近的节点来扩展查询(包括相关概念)。
建立知识图很费力。但是,我们可以使用WordNet(一个词之间的语义关系的词汇数据库(提供200多种语言!)或ConceptNet(一个语义网络,其中边缘是概念之间的常识断言)来引导用户。“用于”,“由...制成”)。另一种方法是挖掘Wikipedia重定向。
优步分享了他们如何使用知识图进行搜索。首先,他们开发了一种本体来描述图的实体以及它们之间的关系。例如,食物和美食之间与countryOfOrigin相互关联,而每个实体可以是subCategoryOf的另一个实体。
然后,他们从多个来源提取并转换数据以适应其本体。接下来,对实体和边缘进行重复数据删除,并跨多个数据源构建新的边缘。例如,Foursquare上的同一餐厅和内部数据应表示为同一节点。这将通过同一节点连接来自多个源的完全不同的餐厅数据-查找餐厅应返回所有数据源的元数据。
然后,他们使用基于图节点的标签为餐厅和菜单项添加注释-这是脱机完成的。在查询期间(即,在线),通过遍历图表实时对注释进行注释和扩展,以提高查全率。
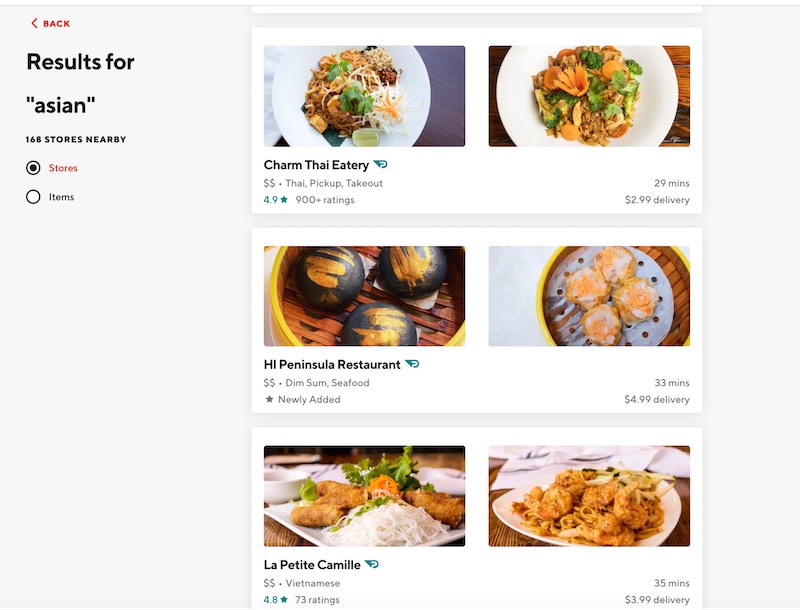
例如,如果用户查询“亚洲人”,则该图会将搜索范围扩大到包括“中国”和“日语”之类的子集。类似地,对“乌冬面”的查询可以扩展为包括诸如“拉面”,“荞麦面”和“日语”之类的相关术语。该图还包括位置作为边。因此,如果餐馆在用户的配送区域之外,则可以遍历该图以在用户的区域中找到相似的美食。
DoorDash还使用知识图并共享其本体。他们的知识图中有三种类型的实体(即节点)(在Neo4j中实现):
- 商店:出售食物的地方。它具有_biz后缀(例如,ihop_biz)。
- 食品类别:诸如鸡肉,中餐,快餐等食物的粗粒度描述。它具有_cat后缀(例如,breakfast_cat)。
- 食品标签:出售的受欢迎商品的细粒度描述,例如炸鸡,点心,炸玉米饼。它具有_tag后缀(例如,sandwich_tag)。
实体通过三种类型的关系连接:
- 每个商店都将属于主要食品类别。例如,ihop_biz属于breakfast_cat。
- 每个食物类别最多可以有一个父食物类别。例如,sandwich_cat仅具有breakfast_cat作为其父级,并且deli_cat仅具有sandwich_cat作为其父级。这样可以在食物类别之间建立等级关系。
- 每个食品标签将属于一个食品类别。例如deli_tag,sandwich_tag和cheesesteaks_tag属于sandwich_cat。
在查询时,知识图扩展了基础查询概念。例如,当客户搜索“ KFC”时,最接近客户的KFC商店将作为最高结果返回。然后,该图用于扩展查询以返回具有相同主要类别(即chicken_cat)的标签(例如fried_chicken_tag,wings_tag)的餐馆。
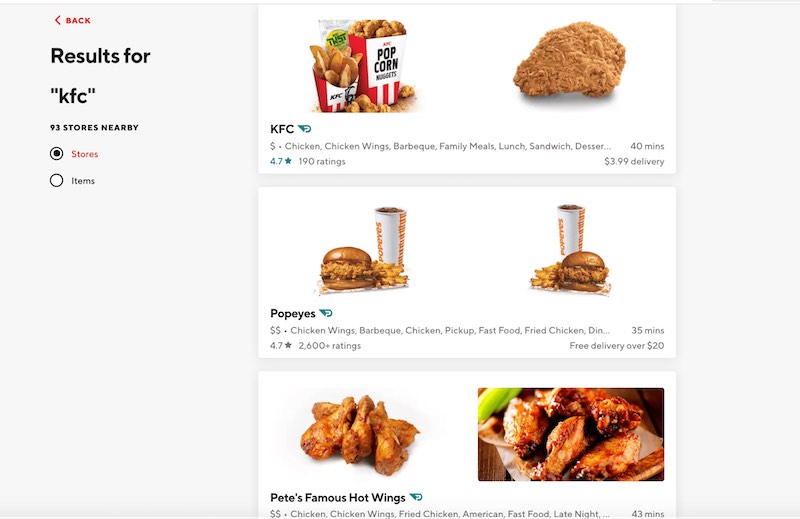
同样,当客户输入广泛的搜索查询(例如“亚洲”)时,它会映射到asian_cat。然后将其扩展到诸如thai_cat和的子类别chinese_cat,并检索具有属于这些类别的标签的餐馆。在下面的示例中,包含thai_tag的Charm Thai是thai_cat一部分,而包含dim_sum_tag的HI Peninsula是chinese_cat一部分。
上述两种办法的陷阱
将每个查询视为单词袋的基于词法的方法可能导致错误的结果。DoorDash共享了一个示例,其中搜索“加利福尼亚面包卷”的客户将获得墨西哥餐馆而不是寿司店的结果,因为令牌“加利福尼亚”和“面包卷”出现在墨西哥餐馆的食物菜单中。
基于词法的方法也难以理解:
- 上位词:更广泛类别的单词,例如“帽”是的“贝雷”“帽”,以及“snapback”上位词。
- 同义词:不同的词,具有相同的含义(例如,“勃艮第服饰”,“红色服饰”)。
- 反义词:具有或暗含相反意思的词。尽管“乳胶手套”与“无乳胶手套”具有相同的标记,但它们的含义相反。
尽管可以使用字典和规则来克服这一问题,但手动管理和维护每种语言的这些知识库很繁琐。
基于词法的方法也易受形态变异的影响(例如,“woman”与“women”)。尽管可以应用词干,但它并不完善,并且可能导致信息丢失和错误。例如,“ Universal”,“ university”和“ universe”都源自“ univers”。同样,这牵涉到手工制定的规则,这些规则难以创建和维护。
最后,基于词法的方法对拼写错误很敏感。10个查询中有1个拼写错误。正如DoorDash的经验所示,虽然我们可以采用拼写检查器和校正器,但拼写校正器可能过于激进并改变了客户的意图。
尽管知识图有助于提高recall率,但它们也是大量的手动工作。根据Uber和DoorDash的经验,需要努力构建本体,用来自多个来源的数据填充知识图,对节点和边缘进行重复数据删除,创建新的边缘以更好地进行关系映射以及确保节点和边缘的准确性。
然后,我们需要使用知识图中的节点离线标记目录项,并实时在线标记和扩展查询。知识图的缩放和维护成本很高,并且需要不断进行手动管理和质量检查以确保正确性。
为了增强基于词法和基于图的方法,团队越来越多地转向基于表示机器学习和基于嵌入的方法。
基于嵌入:将查询分解为数字
Representation learning 是一种从数据中学习项目的潜在表示(即嵌入)的方法。它们是潜在的,因为无法直接观察到它们。它们也被称为语义嵌入,因为它们能很好地学习项目的语义。可以通过自我监督或监督的方法来完成。
最常见的自我监督方法可能是word2vec,它可以在给定文本语料库的情况下学习文本嵌入。它通过训练网络以通过跳跃语法方法预测给定单词的单词的邻居(即上下文),或通过连续词袋(CBOW)方法在给定单词的邻居的情况下预测单词来做到这一点。可以使用类似的范例来生成查询嵌入。
受监督的方法通常使用点击或购买事件作为标签。这涉及训练一个模型,该模型将查询和文档作为输入并预测点击或购买的可能性。然后,将训练后的模型用于生成查询和文档嵌入。
一旦有了查询和文档嵌入,就可以在查询扩展和文档检索中使用它们。与基于词法的方法相比,嵌入具有多个优势。例如,它们对语义进行编码并消除了对同义词词典的需求;在嵌入空间中,“handphone”,“cellphone”和“mobile phone”可能很接近。此外,使用字符级n-gram,可以使查询嵌入对形态变异和拼写错误不太敏感。
自我监督技术:无需标签!
雅虎学习表示法RL的方法始于创建查询和单击文档的二部图。然后,他们从共同单击的查询中提取标记以表示文档。来自更多共同单击查询的标记可能更能代表文档。因此,两个文档共享的查询越多,它们就越接近,反之亦然。同样,共享许多共同单击文档的查询可能具有相似的意图。
每个查询都由令牌向量表示,权重与查询中的频率成正比,并归一化为1。然后,查询和文档向量进行迭代传播(类似于交替最小二乘以进行协作过滤),从而生成查询和文档嵌入在相同的向量空间中。为了获得查询和文档之间的相似性,它们计算这些向量的内积。
Uber使用GloVe算法学习查询嵌入。GloVe(全局向量)通过学习语料库中的单词共现来创建单词嵌入。为了将语言建模范例应用于搜索,每个查询都被视为句子中的一个单词,并且如果两个查询都导致来自同一餐厅的订单,则查询在句子中(即相同上下文)“彼此相邻”。换句话说,餐厅是上下文,如果两个查询都导致同一餐厅的订单,则这两个查询共享相同的上下文。
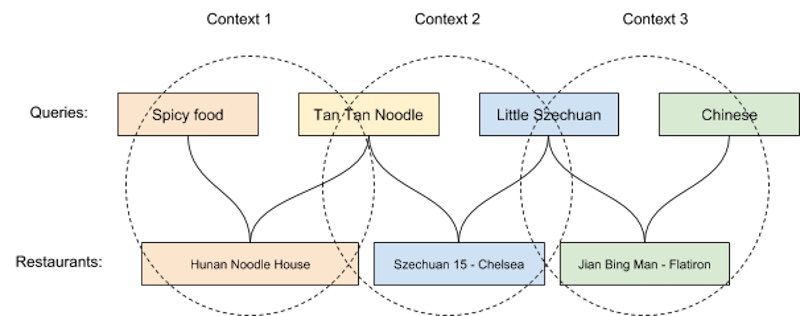
然后,他们应用基于GloVe的因式分解模型来学习查询嵌入。然后,这些查询嵌入可用于查询扩展(通过近似最近的邻居)以提高搜索的查全率。例如,如果用户搜索“棕褐色面条”(或更准确地说是“担担面”),并且附近没有餐馆在出售它,则可以将其扩展为“小四川”,“中国”和“辣”食物”。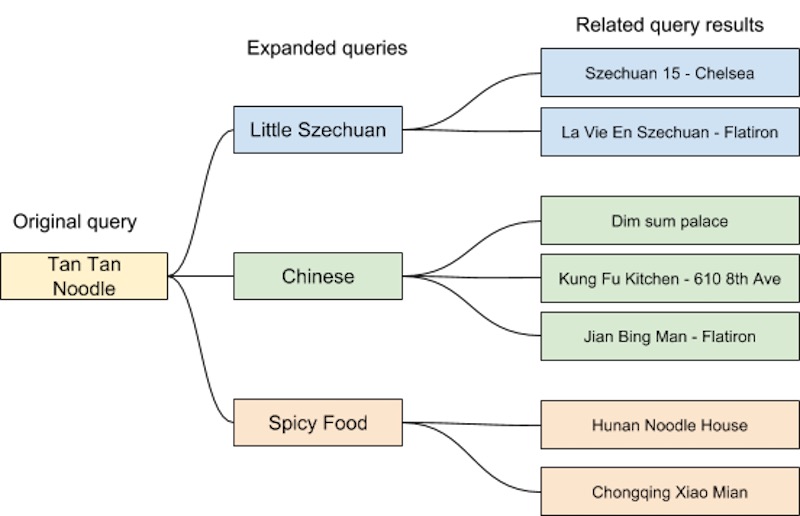
GrubHub采用了类似的范例,采用了跳过语法架构和共享示例,其中“乌冬面”和“地中海风味”的最近邻点几乎与参考食物图以1:1比例映射。这提供了保证,自我监督的方法可以通过嵌入捕获知识图样的语义。
有监督的技术:改进我们所需事件的建模
亚马逊使用客户行为数据构建了语义产品搜索。他们的神经网络架构在整个查询和产品中共享嵌入。将查询按原样输入模型中,而将产品表示为有序属性包(例如标题,品牌,颜色)。他们还尝试了学习属性嵌入,但由于结构化数据的准确性和可用性存在差异,因此recall率(相对于连接属性)降低了5%。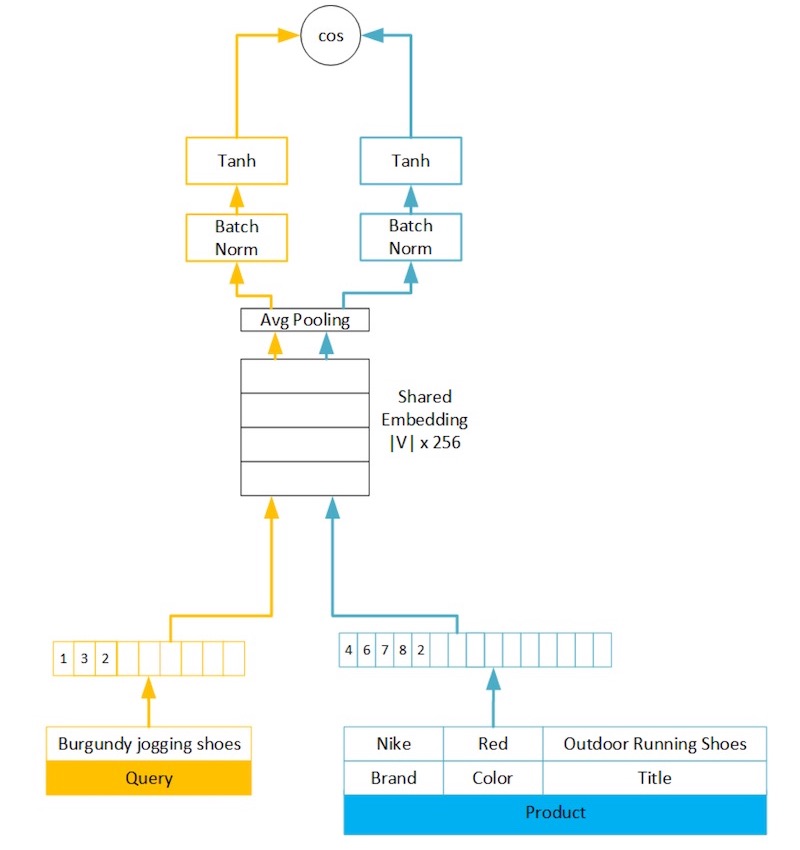
然后,将平均池应用于查询和产品的固定长度嵌入。相对于LSTM和GRU之类的递归方法,使用平均池对平均平均精度和recall率100的影响很小(<0.5%),而所需的计算,训练时间和推理等待时间则更少。
他们最初采用了两部分式铰链损失( two-part hinge loss)。首先,ŷ是查询和产品嵌入之间的余弦相似度,如果购买了产品(响应查询),则y = 1,否则为0。铰链损失可确保当y = 1时ŷ > 0.9,当y = 0时ŷ <0.2。但是,由于产品印象深刻,但随机负数(红色)和购买的正数(绿色)之间的得分分布与没有购买有很大的重叠。
因此,他们更新了两部分损失,还考虑了印象深刻但未购买的产品,其中ŷ <0.55,其中y =印象深刻但未购买的产品。这改善了随机阴性(红色),印象深刻但未购买的阴性(灰色)和购买的阳性(绿色)之间的得分分离。
为了标记查询和产品,他们应用了标记方法,例如:
- 字母组合词和n字母组合词:N-grams捕获字母组合词没有的短语级信息。例如,“巧克力牛奶”和“牛奶巧克力”虽然共享相同的字母组合,但却有所不同。
- 字符三字组:这些字符对类型可靠,可以很好地处理复合词(例如“ amazontv”,“ firetvstick”)。它们还捕获了模型零件的相似性。
由于字典的大小随n呈指数增长,因此拥有所有可能的单词n-gram的词汇表是不可行的。因此,它们基于令牌频率保持数十万个n-gram的词汇量。为了处理看不见的单词,他们将语音(OOV)令牌散列到其他嵌入容器中。通过使用固定的哈希函数和共享的查询文档嵌入,查询和产品中看不见的标记都映射到相同的嵌入向量。使用比vocab大小大5-10倍的垃圾箱。然后,将所有令牌合并为一个令牌袋(即无序,权重相等)。
Facebook的基于嵌入的搜索采用两塔式方法( two-tower approach),分别使用塔式查询和文档。该模型根据查询和文档之间的距离公式化为排名问题。余弦相似度用作距离度量。
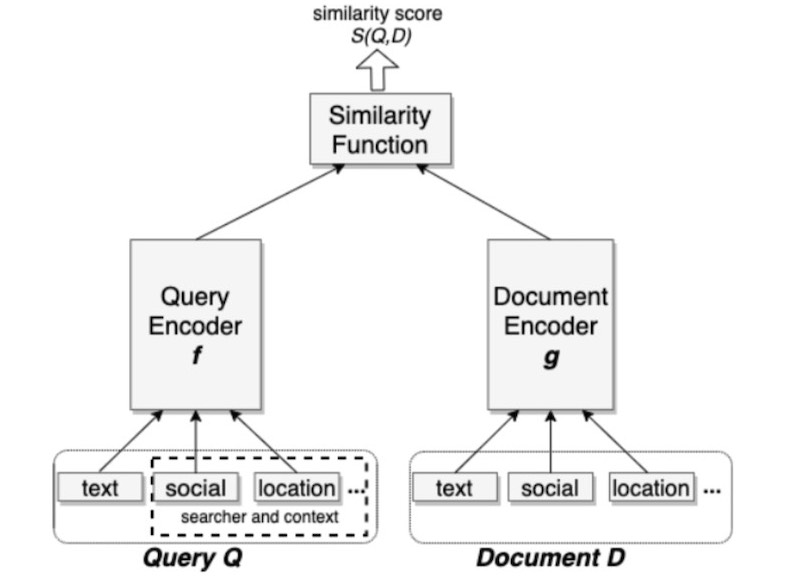
他们使用三重态损失来近似recall目标。对于给定的三元组(q,d +,d-),q是查询,而d +和d-是相关的正面和负面文档。D(q,d)是查询和文档嵌入之间的距离,m是在正负对之间强制执行的边距。直觉是通过距离边距将正对和负对分开。
对于肯定标签,他们尝试使用点击次数和展示次数。为什么将印象作为正面标签?直觉是要教模型返回相同的结果集,该结果集将由排名者排名高。两者都被认为是同等有效的,尽管在点击数据中增加展示次数并不能改善模型。
对于否定标签,他们尝试使用随机样本和印象深刻但未被点击的样本。相对于随机阴性,在后者上训练的模型(即,非点击展现)的recall率更差,嵌入人员的recall率下降了55%。(这与Amazon的方法相比较,在该方法中,考虑非点击印象会带来更好的结果。)他们假设,非点击印象会偏向于文档至少在一个因素上与查询匹配的困难案例。相反,大多数文档都是简单案例,根本不符合查询条件。因此,使用非点击印象会给训练数据造成偏差,使其无法代表实际的检索任务。
对于文本功能,他们使用了字符和单词n-gram。添加单词n-gram会带来较小但一致的改进(recall率+ 1.5%)。与亚马逊类似,他们发现单词n-gram的基数太高(查询三字母组为3.52亿),因此不得不应用散列来减小嵌入表的大小。
作为附加上下文,它们包括查询的位置特征(例如,城市,国家/地区,语言)和文档(例如,组位置)。它们还包括社交嵌入功能,这些功能通过单独的嵌入模型进行了训练,以将用户和实体嵌入社交图中。
作为最后一个示例,我们看一下京东的JD的语义检索模型,该模型通过引入多个查询头将其进一步向前发展。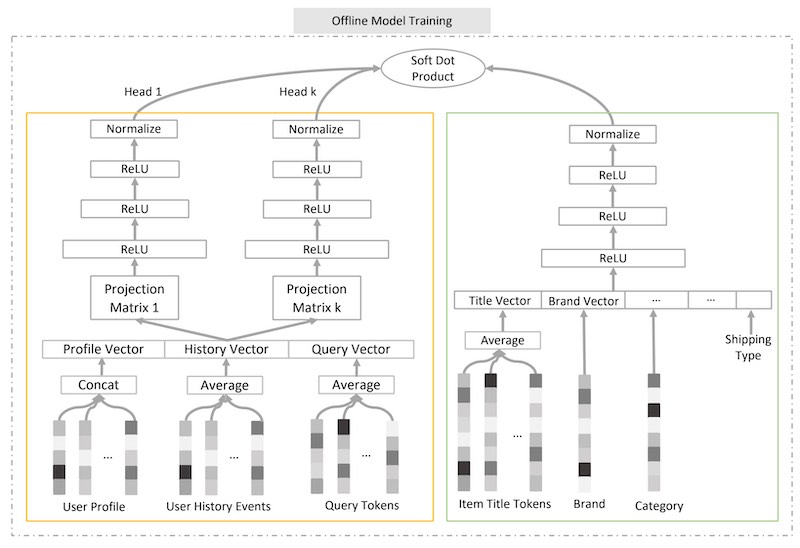
物品塔很简单,其中将来自多个属性(例如,标题,品牌,卖家)的嵌入链接到单个向量中(这类似于Amazon的方法,尽管每个属性都有嵌入)。然后,向量经过多个“整流线性单位”层。最后,将输出项嵌入标准化为与查询嵌入相同的长度。
查询塔是新颖的,因为它有多个头(如Transformer)。附加投影层将密集输入层传递到k个密集表示中。然后,将这k个表示形式传递到k个单独的编码器中,每个编码器都有自己的参数。结果,每个查询头都为查询捕获了不同的语义含义,例如对于产品查询使用了不同的流行品牌(例如,“手机”使用苹果和三星),对于品牌查询使用了不同的产品(例如对于“三星”)。
为了获得查询项目相似性,他们计算了多个查询嵌入和单个项目嵌入之间所有内部乘积的加权和。权重是从同一组内部产品的softmax(具有温度参数(β))计算得出的。温度越高,重量将越均匀。当温度趋于零时,相似性评分等同于选择最大的内部乘积。
为了创建否定项标签,他们使用了随机否定项和批次否定项的组合。从所有项目中均匀抽取随机负数。因此,每个项目都有相同的可能性出现为负数。但是,这在计算上很昂贵,因为每个随机负数都必须经过物料塔(以获得物料嵌入)。批次否定项来自同一批次中的其他查询-项目对。对于查询项目对,同一批中的其他肯定项目用作项目否定项目。他们发现比例为0.5-0.75的随机负片效果很好。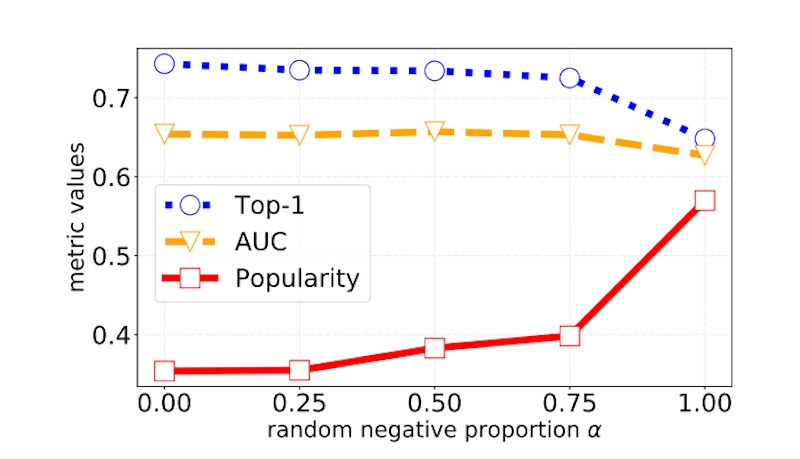
基于嵌入的方法也有陷阱
例如,优步(Uber)表示,“清真食品”可能会扩展到“中东”,“地中海”或东南亚美食,并检索可能不是清真食品的餐馆,从而导致糟糕的客户体验。此外,表示学习RL需要大量的行为数据,而当搜索系统在几乎没有数据的新市场中启动时,这些行为数据可能不可用。
因此,我发现基于词法,图和嵌入的方法是互补的。大多数搜索系统使用基于嵌入的方法来增强词法和/或基于图的方法(而不是完全替换它们)。例如:
- Uber使用其知识图和查询嵌入进行查询扩展
- 亚马逊的语义匹配增强了关键字和行为匹配
- Facebook的语义匹配增强了他们现有的布尔匹配
详情点击标题!