在分布式系统中,事件在解耦系统的不同组件方面起着重要作用。在本文中,我们讨论如何改进领域事件的设计以解决系统中的多个问题。
上下文
CasaOne租赁平台由围绕其自己的有界上下文构建的多个服务组成。去年,我们重建了一个负责管理租赁的服务。我们借此机会解决了我们在早期事件设计中遇到的一些问题。
我们将讨论服务的以下几个方面
- 发布事件:只要域模型发生显着变化,服务就应该发布事件。系统中的其他服务应该能够订阅这些事件并根据业务规则做出反应。该事件至少应交付给消费者使用一次(至少一次交付)。
- 审计跟踪:该服务应存储在该服务中执行的所有业务操作的审计跟踪。
发布事件
过去我们采用了一种简单的方法。该服务将事件直接发布到事件总线。服务中的业务操作一般执行以下步骤
- 执行一系列业务逻辑。
- 在数据库中持久化域实体的状态。
- 在事件总线上发布事件(在我们的案例中为 AWS SNS 主题)。
例如:当客户发起租约时,会在数据库中创建“租约”实体,并将lease.created事件发布到 SNS 主题。
上述方法适用于大多数情况,但根据实施情况会导致以下问题之一。
- 幻影事件:幻像事件指向数据库中不存在的实体
- 丢失事件
实现1:如下面的伪代码所示,该服务在事务内部发布事件,该事件将实体保存在数据库中。如果事件提交后事务提交失败—由于诸如服务与数据库之间的网络问题或服务崩溃之类的故障,则将导致“幻像事件”被发布到事件总线。
//幻象事件 |
如果在上面的例子中这样的幻象事件是由消费者处理的
- 系统将为不存在的租赁保留库存。这导致我们花费数千美元购买了仓库中的新库存租赁信息和从未用过的租赁信息。
- 客户会对从未见过的租约的确认电子邮件感到困惑。
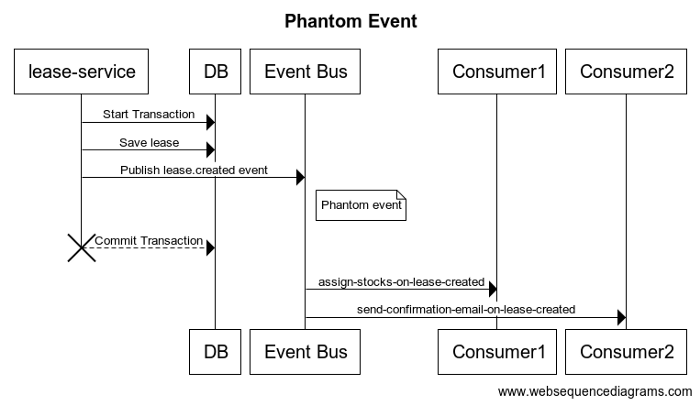
上述问题的根本原因是——我们正在跨多个事务边界执行操作,即数据库和事件总线。确保跨分布式服务的一致性需要复杂的解决方案,例如两阶段提交或补偿事务。这些复杂的解决方案只有在参与的服务支持它们时才是可行的。在许多情况下,这些都没有。
让我们看一下如何通过消除跨服务的事务需求来解决此问题。
当我们开始探索解决方案时,我们遇到了事务发件箱模式CDC模式,用这种方法
- 该服务在单个事务中将域实体和事件保存在同一数据库中。
- 外部进程会将事件从数据库传送到事件总线。
这确保我们不会遇到发布的事件和域实体状态之间的一致性问题。保存域实体和事件的伪代码如下所示。
function createLease(lease) { |
在我们上面的示例中,事件存储在lease_events同一个数据库中调用的表中。这是问题的第一个也是更容易的部分。我们需要一种可靠且快速的方式将事件从事件表(事务发件箱)传送到事件总线。我们有以下选择:
- 轮询发布者:后台进程轮询事件表中的新事件,并在将事件发布到事件总线后将事件标记为已发布。
- 事务日志拖尾:后台进程订阅数据库事务日志,过滤事件表中的日志变化,并将事件发布到事件总线。此过程维护已处理事务日志的偏移量,以了解到目前为止已将哪些事件发布到事件总线。
在上述这两个选项,一个消息可以在极少数情况下不止一次发布到事件总线如-当处理发布事件无法作为发布到标记事件或无法更新发布的后期事件的偏移量。根据至少一次交付语义,这是预期的。我们将在后续部分讨论如何处理这些重复事件。
我们对上述方法进行了讨论和辩论,得出以下结论
- 轮询发布者方法需要为事件表中的每个事件提供额外的跟踪数据。而且,我们必须在两者之间做出选择——由于轮询不频繁导致发布延迟或由于频繁轮询导致数据库负载增加。
- 事务日志尾部追加方法是非侵入性的,并允许跨多个服务重用。主流关系数据库提供了一种使用它们已经用于数据复制的机制来订阅事务日志的方法。因此,我们采用了使用debezium的事务日志拖尾方法,该方法 支持MySQL二进制日志中的变更数据捕获 (CDC) 。

整个新的机制:
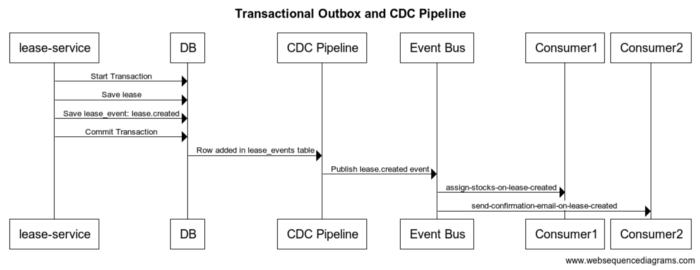 我们做出的高级设计决策是
我们做出的高级设计决策是- 消费者的向后兼容性:Debezium支持将事件推送到Kafka或Kinesis,但不支持SNS。我们不想为使用SQS队列的现有使用者强加新的使用方式。为了支持向后兼容性,Debezium将事件推送到 Kinesis 主题,一个 lambda 函数使用了 Kinesis 主题中的事件并将其发布到相关的 SNS 主题。
- 重复数据删除:如果 debezium 由于故障无法更新日志偏移量,则有可能从 binlog 多次接收相同的事件。我们在管道中构建了一个中间层,以根据事件 ID 对事件进行重复数据删除。
- 本地开发支持:我们希望确保开发人员可以在开发过程中轻松测试发布和消费事件。我们使用localstack(我们已经在使用)和脚本的组合来实现这一点,以运行上述数据管道的最小版本。
整个解决方案最初让我们付出了大量的一次性努力。但它为我们带来了丰厚的回报,因为随着我们的进步,我们以最少的努力获得了更多的服务。
我们有一个单独的平台团队(我们的数据工程团队)专注于事务日志拖尾组件。我们的产品工程团队可以专注于服务的功能方面并轻松发布事件。
审计追踪
过去,我们有不同的表和 API 来维护聚合根实体和服务中相关实体的更改历史记录。例如:status_history,address_history,payment_method_history等这种方法需要大量的努力来跟踪新实体或现有实体的附加信息的历史。
这种方法受到在我们的事务数据库 (RDBMS) 中使用静态列的限制。我们希望利用关系数据库中的JSON列支持来创建通用审核表和基于它的通用API,以最大程度地减少重复的工作。
我们为事务发件箱创建的事件表具有许多类似于审计跟踪属性的属性。这使我们能够丰富事件表(事务发件箱)并将其用作审计跟踪。
事件的事务发件箱(审计跟踪表)被命名为<entity>_events. 该表的高层结构如下:
- event_id:事件的唯一标识符。
- event_type:例如:“lease.created”、“lease.started”。
- schema_version:例如:“v2”。
- created_at:事件时间戳。
- data:包含事件相关数据的 JSON 列。
- <entity>_id:聚合根实体的ID 。这有助于跟踪和过滤特定根实体的事件。
- <related_entity>_id:相关实体的 id 的可选列。这有助于跟踪和过滤相关实体的事件。
我们构建了api,以允许消费者获得整个服务中事件的时间线视图。事件可以通过<entity>\u id、事件类型、时间范围等进行过滤。事件可以根据事件时间戳按最近的顺序或最早的顺序进行排序。
这有助于我们用一个审计表替换多个历史表。我们可以在几天内开发其他历史记录/审计跟踪功能,而不是一周或更长时间。
概括
上述领域事件架构帮助我们
- 将事件一致地交付给消费者,没有幻象事件和丢失事件。
- 提供统一的审计跟踪来跟踪服务中的所有操作。
结论
在产品的早期阶段,我们可以简单地从单体架构开始,在初创公司的时间和资源限制下快速发展。随着产品和团队开始扩展,我们不得不打破这个单体/整体系统,将团队分成更小的单元以快速移动。
在打破单体到服务的早期阶段,一种简单而天真的方法使我们能够快速行动,我们可以手动处理一次性错误。随着我们开始进一步扩展,一次性错误变得更加昂贵,因此有必要投入时间和资源来构建强大的解决方案。这帮助我们减少了管理错误所花费的时间,并花更多时间为我们的客户构建有用的功能。
最后,我们选择的解决方案取决于当时的规模和需求。与往常一样,没有灵丹妙药。