获得腾讯投资的Dream11平台可以让用户创建由真实玩家组成的虚拟团队,并允许他们根据实际游戏中玩家的数据表现来组织比赛。获奖者将获得积分奖励,每场比赛都有参赛费。该平台提供梦幻板球、足球、卡巴迪和NBA的比赛:
对于 1 亿 Dream11 用户来说,在我们的平台上玩梦幻体育的刺激和兴奋是无与伦比的。他们喜欢创建自己的团队并与其他粉丝和朋友竞争!但是,从后端的角度来看,我们在 Dream11 的流量和参与度变化方面面临着各种挑战,主要是在比赛开始时间之前。为了确保应用程序在用户流量高的关键时刻顺利运行,作为一个团队,我们提出了一个可扩展和可定制的解决方案。因此,我们能够同时运行多场比赛,每秒高效处理数百万个用户请求,而不会影响他们玩梦幻体育的体验。
我们如何管理 Dream11 平台上这种在短时间内剧烈波动的流量变化?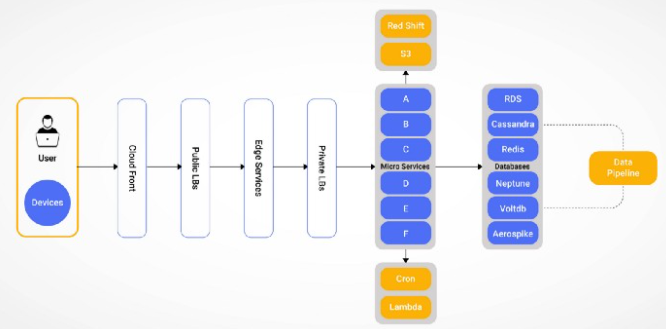
架构支持:
- 超过1亿的用户群
- 用户并发超过550万
- 边缘服务的每分钟请求数 (RPM) 超过 1 亿
- 超过 30K+ 的计算资源来支持峰值 IPL 流量
- 超过 100 多个并行运行的微服务
一旦用户打开 Dream11 应用程序,他们的旅程通常会在主页、巡回赛、团队和比赛页面之间来回切换。因此,应用程序的负载会发生变化,相应地,边缘层、其依赖服务和微服务必须扩展或扩展。
有趣的是,用户并发性可能会在事件之间或比赛之后上升或下降,并且根据每年用户的增长来预测它可能具有挑战性。
让我们还考虑在比赛前、比赛中和比赛后在平台上产生尖峰的不受控制的变量。这些是,
- 用户兴趣取决于比赛和球员在现实生活中的受欢迎程度,这会影响 RPM 的大小。
- 特定于比赛的事件,例如抛球、小队公告、由用户发布小队公告的团队创建,以及中间时段的事件,例如小门倒下、击中六分球、帽子戏法、突围事件和其他不可预测的因素(例如下雨)。
自动扩展为何不起作用?
就基础设施而言,自动缩放有几个限制。它的配置时间不够快,无法在关键事件期间支持用户的计算需求!海啸流量期间的大量用户需要较短的配置时间来跟上峰值,并且可能不适合有构建时间并让用户等待。
- 节点的现货Spot 可用性有限且竞争激烈——尤其是在关键时间!
- 如果要考虑 Dream11 的规模,此时步进Step缩放也可能不起作用,因为它仅限于一定数量的节点
- 基于资源的可用性重新平衡或重新安排跨可用区 (AZ) 的节点数量可能会进一步增加与时间有关的供应成本。
传统应用程序负载均衡器 (CLB/ALB) 的限制
- 根据吞吐量创建负载均衡器分片,因为负载均衡器上生成的请求数量有限制。为了基于用户并发性获得更高的吞吐量,需要创建分片并根据服务路由对其进行管理。
- 必须对 ELB 进行预热以应对突然的流量激增。
云控制平面(云提供商)的限制
- 此外,我们的云提供商的功能也有限制。应用程序接口 (API) 调用率因业务而异,在分配资源时需要考虑这一点
- 由于供应的资源数量众多,控制台操作很繁重。
- 扩展到 100 多个微服务的运营开销。
解决方案:预测 - 主动扩展
- 我们自产的并发预测模型
我们在 Dream11 的数据科学团队在尝试了具有 100 个特征的多个模型后,开发了一个使用 XGboost 模式预测用户并发的模型,以预测 Dream11 平台上的每小时并发。
我们首先通过一个线性模型运行每个匹配的元数据,该模型给出匹配的层级。比赛等级是比赛受欢迎程度的指标变量。
然后根据相似匹配的过去并发对匹配层进行分类(按高并发或最需要的优先)。
然后模型迭代多个特征来预测特定匹配的并发性。这些可以是每小时的特征,例如该小时(及其周围的小时)按层级匹配的数量、前几小时/天的活跃用户、平均交易规模等。所有这些数据都经过标准化处理,可以照顾到Dream11 的指数增长。
最重要的是,我们需要一个合适的成本敏感的损失函数,没有预测不足的选项。总的来说,我们拥有超过 200 个变量和比数据科学更多的数据艺术性,使得 XGBoost 模型可以在非常有限的超参数调整下工作。
正如我们的数据科学团队所相信的,“错误分析 >>>> 超参数调整”。
- 性能测试和游戏日
根据提供并发估计的预测模型,性能团队举行“比赛日”以基准基础设施容量以及基于过去比赛的分解趋势。
使用的性能测试框架是Torque
基础设施配置框架:Playground(观看此空间了解更多信息)
使用 Playground 配置基础设施和Torque来运行性能测试,性能团队根据用户并发预测对业务功能的以下改进进行了认证。
- 性能指标和验证:
- 定义应用延迟——为业务服务的可接受延迟
- 识别个人服务能力
- 基准计算和网络吞吐量
- 识别应用程序的故障和饱和点
- 产生突然的尖峰和浪涌以识别对后端基础设施的影响并识别架构中的级联效应
- 测试基础设施边界,包括计算、网络、API 限制和操作。
- 部署优化以减少配置时间
- 完全烘焙的 Amazon 机器映像 (AMI),用于使用应用程序工件进行部署以实现更快的扩展
- 跨可用区配置多种计算实例类型(多样化),减少容量挑战
- Spot 实例的容量优化分配策略
- 成本优化确保 100% 资源在现场运行
- 在现场不可用的情况下通知失败并启用按需供应。
- 加权域名系统 (DNS) 记录以支持 ELB 分片。
- 使用 Scaler 缩放关键时间
- Dream11 的 DevOps 和 SRE 团队精心设计了一个平台“Scaler”,它有助于根据并发预测和性能基准进行主动扩展。
- 基于与预测的并发性和趋势相关的性能测试,系统被输入不同的用户并发块和各自的基础设施,以在比赛前、比赛中和比赛后跨微服务提供。
未来工作范围
随着架构的成熟,我们正在研究容器和数据存储的预测性和计划性扩展。我们还希望优化我们的基础设施成本并实时扩展我们在 Dream11 平台上看到的峰值。为实现这一目标,我们正在寻找有才华的工程师,他们热衷于大规模解决基础设施问题并为 Dream11 用户提供出色的产品。