有两个级别的实时机器学习。
- 级别1:您的 ML 系统进行实时预测(批量预测)。
- 级别2:您的系统可以合并新数据并实时更新您的模型(实时学习)。
阶段 1. 批量预测
所有的预测都是批量预先计算的,以一定的间隔生成,例如每 4 小时或每天。批量预测的典型用例是协同过滤、基于内容的推荐。使用批量预测的公司的例子有 DoorDash 的餐厅推荐、Reddit 的 subreddit 推荐、Netflix 大约 2021 年的推荐。截至本文,Netflix 正在将他们的预测转移到网上。
批量预测很大程度上是遗留系统的产物:在过去的十年中,大数据处理一直由 MapReduce 和 Spark 等批处理系统主导,这使我们能够非常有效地定期处理大量数据。当公司开始使用机器学习时,他们利用现有的批处理系统进行预测。
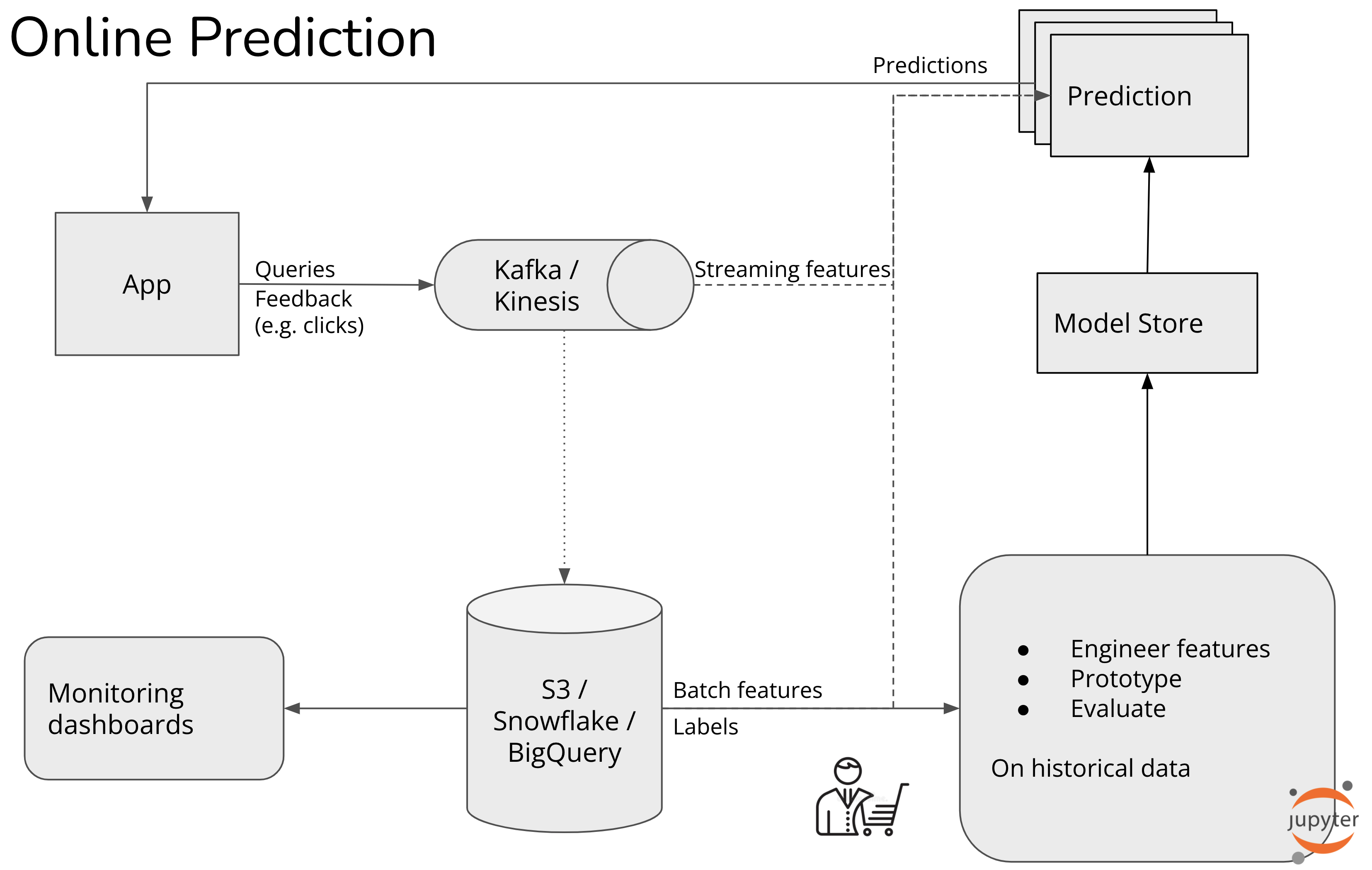
阶段 2. 具有批量特征的在线预测
不是在请求到达之前生成预测,而是在请求到达之后生成预测。他们实时收集用户在其应用上的活动。但是,这些事件仅用于查找预先计算的嵌入以生成会话嵌入。没有从流数据中实时计算特征。
当新访问者访问您的网站时,您不会向他们推荐通用项目,而是根据他们的活动向他们展示项目。例如,如果他们查看了键盘和计算机显示器,他们可能正在查看在家工作的设置,并且您的算法应该推荐相关项目,例如 HDMI 电缆或显示器支架。
为此,您需要在此访问者的活动发生时对其进行收集和处理。如果该访问者查看了第 1 项、第 10 项和第 20 项,则您从数据仓库中提取第 1、10 和 20 项的嵌入。这些嵌入被组合(例如平均)以创建该访问者的当前会话嵌入。
系统将至少包含三个模型:一个用于学习嵌入,一个用于检索,一个用于排名。
已经在进行在线推理或在其 2022 年路线图上进行在线推理的公司名单正在增加,包括 Netflix、YouTube、Roblox、Coveo 等。预计在接下来的两年中,大多数推荐系统将是基于会话的:每次点击、每次查看、每次交易都将用于(近)实时生成新的相关推荐。
在此阶段,您将需要:
- 将您的模型从批量预测更新为基于会话的预测。这意味着您可能需要添加新模型。负责团队:数据科学/ML。
- 将会话数据集成到您的预测服务中。通常,您可以使用由两个组件组成的流式基础设施来做到这一点:
- 流传输,例如 Kafka / AWS Kinesis / GCP Dataflow,用于移动流数据(用户活动)。大多数公司都使用托管实时传输——自托管 Kafka 很痛苦。
- 流式计算引擎,例如 Flink SQL、KSQL、Spark Streaming,用于处理流式数据。在会话内适应的情况下,这个流计算引擎负责将用户的活动划分为会话并跟踪每个会话内的信息(状态保持)。这里提到的三个流计算引擎中,Flink SQL 和 KSQL 是业界比较认可的,为数据科学家提供了一个很好的 SQL 抽象。
好处:
使用在线预测,您不必为未访问您网站的用户生成预测:如果您每天为每个用户生成预测,那么用于生成 98% 预测的计算将被浪费。
如果您的公司已经使用流式传输进行日志记录,那么这种变化不应该太陡峭。但是,这可能会给您的流媒体基础架构带来更重的工作负载,这可能需要升级以使其更高效/可扩展。
这一阶段的挑战将在:
- 推理延迟:使用批量预测,您无需担心推理延迟。然而,对于在线预测,推理延迟至关重要。
- 设置流式基础设施:许多工程师仍然害怕在流上进行类似 SQL 的连接,尽管围绕它的工具正在成熟。
- 拥有高质量的嵌入,尤其是当您处理不同的项目类型时。
阶段 3. 具有复杂流 + 批量特征的在线预测
- 批量特征是从历史数据中提取的特征,通常使用批处理。也称为静态特征或历史特征。
- 流特征是从流数据中提取的特征,通常使用流处理。也称为动态功能或在线功能。
如果处于第 2 阶段的公司需要很少的流处理,则处于第 3 阶段的公司使用更多的流功能。例如,用户在 Doordash 上下订单后,他们可能需要以下功能来估计交货时间:
- 批次特征:这家餐厅过去的平均准备时间
- 流媒体功能:此时,他们还有多少其他订单,有多少送货人可用
在第 2 阶段讨论的基于会话的推荐的情况下,您可能会使用流特征,例如用户在网站上花费的时间量、项目的购买次数,而不是仅使用项目嵌入来创建会话嵌入在过去的 24 小时内。
此阶段的公司示例包括 Stripe、Uber、Faire,用于欺诈检测、信用评分、驾驶和交付评估以及建议等用例。
要将您的 ML 工作流程移至此阶段,您需要:
- 成熟的流媒体基础设施,具有高效的流处理引擎,可以以可接受的延迟计算所有流媒体特征。您需要能够将请求发送到您的流传输中,并在下一个请求到达之前足够快地处理它们以供预测服务使用。
- 用于管理物化特征并确保训练和预测期间流特征的一致性的特征存储。注意:当前的特征存储通常管理物化流特征,但不管理特征计算或特征的源代码。
- 样板店。流特征在创建后需要进行验证。为确保新功能确实有助于提高模型的性能,您希望将其添加到模型中,从而有效地创建新模型。理想情况下,您的模型商店应该可以帮助您管理和评估使用新的流功能创建的模型,但同时评估模型的模型商店还不存在。您可以将其中的一部分委托给功能存储。
- 最好有更好的开发环境。数据科学家目前即使在创建流媒体功能时也会处理历史数据,这使得提出和验证新的流媒体功能变得困难。如果我们可以让数据科学家直接访问数据流,这样他们就可以快速试验和验证新的流特性会怎样?不是数据科学家只能访问历史数据,如果他们也可以访问来自笔记本的传入数据流怎么办?
。。。
实时机器学习在很大程度上是一个基础设施问题。解决它需要数据科学/机器学习团队和平台团队共同努力。
在线推理和持续学习都需要成熟的流媒体基础设施。持续学习的训练部分可以批量进行,但在线评估部分需要流式处理。许多工程师担心流媒体既困难又昂贵。3 年前确实如此,但从那时起,流媒体技术已经显着成熟。越来越多的公司正在提供解决方案以使公司更容易迁移到流媒体,包括 Spark Streaming、Snowflake Streaming、Materialize、Decodable、Vectorize 等。
原文点击标题