在本文中,我们将了解 Hadoop 分布式文件系统 (HDFS) 的真正含义以及它的各种组件。此外,我们还将了解 HDFS 的魅力所在——这就是它如此特别的原因。让我们来了解一下!
什么是 Hadoop 分布式文件系统 (HDFS)?
在单台机器上维护海量数据是很困难的。因此,有必要将数据分解成更小的块并将其存储在多台机器上。
跨机器网络管理存储的文件系统称为分布式文件系统。
Hadoop分布式文件系统(HDFS)是Hadoop的存储组件。存储在 Hadoop 上的所有数据都以分布式方式存储在机器集群中。但它有一些属性定义了它的存在。
- 巨大的容量——作为一个分布式文件系统,它能够存储 PB 级的数据而不会出现任何故障。
- 数据访问——它基于“最有效的数据处理模式是一次写入,多次读取模式”的理念。
- 经济高效——HDFS 在商用硬件集群上运行。这些是可以从任何供应商处购买的廉价机器。
Hadoop 分布式文件系统 (HDFS) 的组件有哪些?
从广义上讲,HDFS 有两个主要组件——数据块和存储这些数据块的节点。但它的意义远不止眼前所见。因此,让我们一一看一下,以更好地理解。
HDFS 块
HDFS 将文件分解为更小的单元。这些单元中的每一个都存储在集群中的不同机器上。然而,这对于在 HDFS 上工作的用户来说是透明的。对他们来说,这似乎是将所有数据存储到一台机器上。
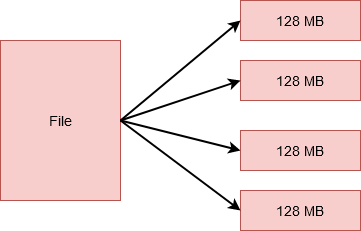
这些较小的单元是 HDFS 中的块。每个块的大小默认为 128MB,您可以根据需要轻松更改。因此,如果您有一个大小为 512MB 的文件,它将被分成 4 个块,每个块存储 128MB。
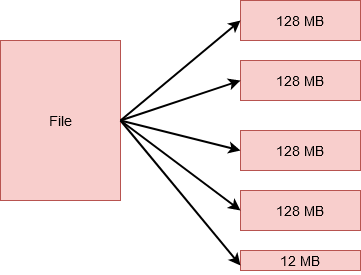
但是,如果您有一个大小为 524MB 的文件,那么它将被分成 5 个块。其中 4 个每个将存储 128MB,总计 512MB。第 5 个将存储剩余的 12MB。那就对了!最后一个块不会占用磁盘上的全部 128MB。
但是,你一定想知道,为什么在一个区块中会有这么大的数量?为什么不是多个 10KB 的块?好吧,我们通常在 Hadoop 中处理的数据量通常是 P级别或更高。
因此,如果我们创建小尺寸的块,我们最终会得到大量的块。这意味着我们将不得不处理关于块位置的同样大的元数据,这只会产生大量开销。我们真的不想要那个!
将数据存储在块中而不是保存完整文件有几个好处。
- 文件本身太大而无法单独存储在任何单个磁盘上。因此,谨慎地将其分布在集群上的不同机器上。
- 它还可以通过利用并行性来适当地分散工作负载并防止单台机器阻塞。
现在,您一定想知道,集群中的机器呢?他们如何存储块以及元数据存储在哪里?让我们来了解一下。
HDFS中的Namenode
HDFS 运行在 master-worker 架构中,这意味着集群中有一个 master 节点和多个 worker 节点。主节点是Namenode。
Namenode是在集群中的单独节点上运行的主节点。
- 管理文件系统命名空间,它是文件系统树或文件和目录的层次结构。
- 存储所有文件的文件所有者、文件权限等信息。
- 它还知道文件中所有块的位置及其大小。
所有这些信息都以两个文件的形式在本地磁盘上永久维护:Fsimage和Edit Log。
- Fsimage存储有关文件系统中文件和目录的信息。对于文件,它存储复制级别、修改和访问时间、访问权限、文件组成的块及其大小。对于目录,它存储修改时间和权限。
- 另一方面,编辑日志Edit Log跟踪客户端执行的所有写操作。这会定期更新到内存中的元数据以服务读取请求。
每当客户端想要向 HDFS 写入信息或从 HDFS 读取信息时,它都会与Namenode连接。Namenode 将块的位置返回给客户端并执行操作。
是的,没错,Namenode 不存储块。为此,我们有单独的数据节点存储块。
HDFS 中的数据节点
Datanodes是工作节点。它们是可以轻松添加到集群的廉价商品硬件。
当 Namenode 要求时, Datanodes负责存储、检索、复制、删除等块。
他们定期向 Namenode 发送心跳,以便它知道他们的健康状况。这样,DataNode 还会发送存储在其上的块列表,以便 Namenode 可以在其内存中维护块到 Datanodes 的映射。
但是集群中除了这两类节点之外,还有另外一个节点叫做Secondary Namenode。让我们看看那是什么。
HDFS 中的辅助 Namenode
假设我们需要重新启动Namenode,这可能会在失败的情况下发生。这意味着我们必须将 Fsimage 从磁盘复制到内存。此外,我们还必须将编辑日志的最新副本复制到 Fsimage 以跟踪所有事务。但是如果我们在很长一段时间后重新启动节点,那么编辑日志的大小可能会变大。这意味着应用编辑日志中的事务将花费大量时间。在此期间,文件系统将处于脱机状态。因此,为了解决这个问题,我们引入了Secondary Namenode。
Secondary Namenode是集群中的另一个节点,其主要任务是定期将 Edit log 与 Fsimage 合并,并生成主节点内存中文件系统元数据的检查点。这也称为检查点。
但是检查点过程在计算上非常昂贵并且需要大量内存,这就是为什么Secondary namenode在集群上的单独节点上运行的原因。
然而,尽管它的名字,Secondary Namenode 并不充当 Namenode。它仅用于检查点并保留最新 Fsimage 的副本。
现在,HDFS 的最佳特性之一是块的复制,这使得它非常可靠。但是它如何复制块以及将它们存储在哪里?现在让我们回答这些问题。
块的复制
HDFS 是 Hadoop 的可靠存储组件。这是因为存储在文件系统中的每个块都复制到集群中的不同数据节点上。这使得 HDFS 具有容错性。
HDFS 中的默认复制因子是 3。这意味着每个块将有两个以上的副本,每个副本存储在集群中不同的 DataNode 上。但是,此数字是可配置的。
但是您一定想知道这是否意味着我们占用了太多存储空间。例如,如果我们有 5 个 128MB 的块,则等于 5*128*3 = 1920 MB。真的。但是这些节点是商品硬件。我们可以轻松扩展集群以添加更多此类机器。购买机器的成本远低于丢失数据的成本!
现在,您一定想知道,Namenode 是如何决定将副本存储在哪个 Datanode 上的?好吧,在回答这个问题之前,我们需要看看 Hadoop 中的机架Rack是什么。
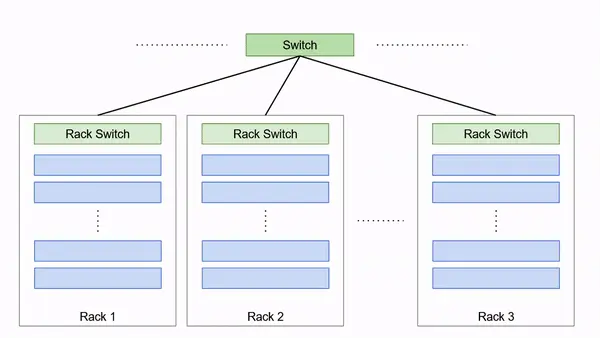
什么是 Hadoop 中的机架Rack?
机架是机器的集合(30-40 Hadoop中)被存储在相同的物理位置。Hadoop 集群中有多个机架,所有机架都通过交换机连接。
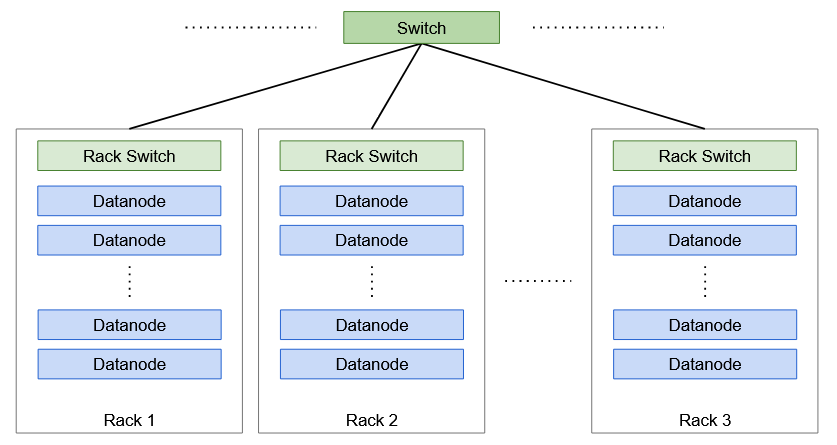
机架意识
副本存储是可靠性和读/写带宽之间的权衡。为了提高可靠性,我们需要将块副本存储在不同的机架和 Datanode 上以提高容错能力。当副本存储在同一节点上时,写入带宽最低。因此,Hadoop 有一个默认的策略来处理这个难题,也称为Rack Awareness算法。
例如,如果一个块的复制因子是 3,那么第一个副本存储在客户端写入的同一个 Datanode 上。第二个副本存储在不同的 Datanode 上,但在不同的机架上,随机选择。第三个副本与第二个副本存储在同一机架上,但在不同的 Datanode 上,再次随机选择。但是,如果复制因子较高,则后续副本将存储在集群中的随机数据节点上。