推荐系统是一种广泛使用的机器学习技术,在电子商务(亚马逊、阿里巴巴)、视频流(Netflix、Disney+)、社交网络(Facebook、Linkedin)和许多其他领域都有很多应用。由于这些服务中的数据量很大,现在大多数行业级推荐系统都是建立在 Spark 和 Hadoop 等大数据框架中的。因此,在这篇博客中,我想向您展示我是如何使用 Scala、Spark 和 Hadoop 构建电影推荐系统的。
目录
推荐系统介绍
推荐系统算法可以分为两大类:基于内容的推荐和协同过滤。
- 基于内容的推荐
利用产品特征向用户推荐与之前喜欢的产品相似的产品。
如果人 P1 和人 P2 对产品 D1 有相同的看法,那么 P1 对产品 D2 的看法与 P2 的看法相同的可能性比与随机选择的人 Px 的看法相同。
适合新闻/文章推荐
好处:
- - 该模型不需要任何用户数据输入,因此更容易扩展。- 能够通过特征工程捕捉小众物品。
缺点:
- - 需要领域知识。
- - 扩展用户兴趣的能力有限。
- 协同过滤
通过收集许多其他用户的偏好信息来预测用户的兴趣。
如果一个人喜欢具有一系列属性的产品D1,他/她更有可能喜欢具有这些属性的产品D2,而不是没有这些属性的产品D3。
应用:电影推荐,亚马逊产品推荐
优点:
- - 不需要领域知识,高度可转移的模式。
- - 能够帮助用户发现新的兴趣。
缺点:
- - 冷启动问题:需要用现有的数据工作,不能处理新的项目/用户。
- - 难以扩展项目的功能。
协同过滤和Spark ALS
在这篇文章中,我们将使用协同过滤作为推荐算法。
协同过滤的工作原理是这样的。
首先,我们把所有用户对所有物品的评分看作是一个矩阵,
这个矩阵可以被因子化为两个独立的矩阵,一个是用户矩阵,行代表用户,列代表潜在因素;
另一个是物品矩阵,行是潜在因素,列代表物品。
在这个因式分解过程中,评分矩阵中的缺失值可以被填补,作为用户对物品评分的预测,然后我们可以用它们来给用户推荐。
ALS(交替最小二乘法)是协同过滤的数学优化实现,它使用带有加权拉姆达正则化 (ALS-WR) 的交替最小二乘法 (ALS) 来找到最小二乘预测和实际评级之间的最小二乘的最佳因子权重。Spark 的 MLLib 包有一个内置的 ALS 功能,我们将在这篇文章中使用它。
系统设置
- Ubuntu 20.04.3
- JDK 11.0.13
- Scala 2.12.11
- Spark 3.2.0
- Hadoop 3.2.2
- IntelliJ IDEA (2021.3.1)
数据集
在这个项目中,我们将使用来自明尼苏达大学双城分校的MovieLens 数据集。您可以通过运行以下命令下载ml-100k (4.7M):
wget https://files.grouplens.org/datasets/movielens/ml-100k.zip
运行以下命令解压缩 zip 文件:
unzip ml-100k.zip
您将看到解压缩ml-100k的文件夹包含多个文件。
我们主要使用两个数据文件:
- u.data:用户评分数据,包括用户id、物品id、评分、时间戳。
- u.item:电影数据,包括项目id、电影名称、上映日期、imdb url等。
在 Spark 中运行
在 Spark 中运行之前,请使用以下命令将代码从我的Github 存储库克隆到您的本地目录:
git clone https://github.com/haocai1992/MovieRecommender.git
准备HDFS中的数据
在我们开始之前,我们需要在终端中启动 hadoop HDFS 和 YARN 服务)。
$ hadoop namenode -format $ start-all.sh
然后我们需要将 ml-100k 数据集上传到 Hadoop HDFS:
$ hadoop fs -put ~/Downloads/ml-100k /user/caihao/movie
Spark中训练推荐模型
使用以下方法在 Spark 中训练推荐模型:
$ spark-submit --driver-memory 512m --executor-cores 2 --class RecommenderTrain --master yarn --deploy-mode client ~/Desktop/spark_test/MovieRecommender/out/artifacts/MovieRecommender_jar/MovieRecommender.jar |
使用以下命令检查您在 HDFS 中训练的模型:
$ hadoop fs -ls -h /user/caihao/movie
在 Spark 中生成推荐
使用以下方法在 Spark 中推荐电影:
$ spark-submit --driver-memory 512m --executor-cores 2 --class Recommend --master yarn --deploy-mode client ~/Desktop/spark_test/MovieRecommender/out/artifacts/MovieRecommender_jar2/MovieRecommender.jar --U 100 |
在 Databricks 中运行 PySpark 版本
如果你不了解 Scala,我还创建了一个 Python 版本的推荐系统!它使用 PySpark 并在 Databricks 上运行。
在此处检查我的代码:我的 Databricks 笔记本。
推荐系统设计
我们的系统设计如下。
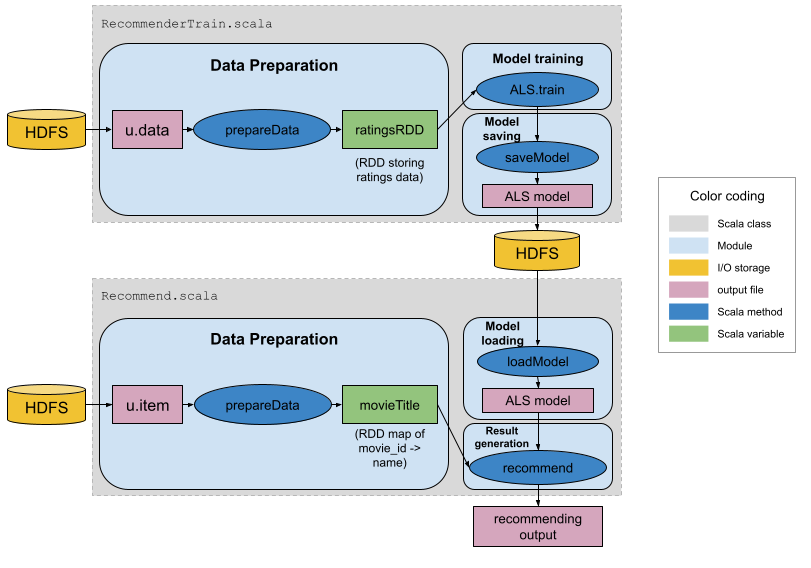
有两个 Scala 对象:
- RecommenderTrain.scala:读取评级文件(u.data),准备数据,训练 ALS 模型并保存模型。
- Recommender.scala:读取电影文件(u.item),加载 ALS 模型,生成电影推荐。
更详细点击标题